Organisation des données avec des feuilles de calcul
Dernière mise à jour le 2024-09-12 | Modifier cette page
Durée estimée : 60 minutes
Vue d'ensemble
Questions
- Comment organiser des données tabulaires ?
Objectifs
- Découvrez les feuilles de calcul, leurs forces et leurs faiblesses.
- Comment formater les données dans des feuilles de calcul pour une utilisation efficace des données ?
- Découvrez les erreurs courantes des feuilles de calcul et comment les corriger.
- Organisez vos données selon des principes de données propres.
- Découvrez les formats de feuilles de calcul textuels tels que les formats séparés par des virgules (CSV) ou par des tabulations (TSV).
Cet épisode est basé sur la leçon Analyse des données et Visualisation dans R pour les écologistes de Data Carpentries.
Tableurs
Question
- Quels sont les principes de base d’utilisation des feuilles de calcul pour une bonne organisation des données ?
Objectifs
- Décrire les bonnes pratiques pour organiser les données afin que les ordinateurs puissent en faire la meilleure utilisation.
Point clé
- Une bonne organisation des données est la base de tout projet de recherche.
Une bonne organisation des données est la base de votre projet de recherche . La plupart des chercheurs disposent de données ou effectuent la saisie de données dans des feuilles de calcul . Les tableurs sont des interfaces graphiques très utiles pour concevoir des tableaux de données et gérer des fonctions de contrôle qualité de données très basiques. Voir aussi @Broman : 2018.
Aperçu de la feuille de calcul
Les feuilles de calcul sont utiles pour la saisie de données. Nous avons donc beaucoup de données dans des feuilles de calcul. Une grande partie de votre temps en tant que chercheur sera consacrée à cette étape de « gestion des données ». Ce n’est pas le plus amusant, mais c’est nécessaire. Nous vous apprendrons comment réfléchir à l’organisation des données et quelques pratiques pour une gestion plus efficace des données.
Ce que cette leçon ne vous apprendra pas
- Comment faire des statistiques dans une feuille de calcul
- Comment faire un traçage dans une feuille de calcul
- Comment écrire du code dans des tableurs
Si vous cherchez à faire cela, une bonne référence est Head First Excel, publié par O’Reilly.
Pourquoi n’enseignons-nous pas l’analyse des données dans des feuilles de calcul
L’analyse des données dans des feuilles de calcul nécessite généralement beaucoup de travail manuel. Si vous souhaitez modifier un paramètre ou exécuter une analyse avec un nouvel ensemble de données , vous devez généralement tout refaire à la main. (Nous savons que vous pouvez créer des macros, mais voyez le point suivant.)
Il est également difficile de suivre ou de reproduire des analyses statistiques ou graphiques effectuées dans des tableurs lorsque vous souhaitez revenir à votre travail ou que quelqu’un vous demande des détails sur votre analyse.
De nombreux tableurs sont disponibles. Étant donné que la plupart des participants utilisent Excel comme tableur principal, cette leçon utilisera des exemples Excel. Un tableur gratuit qui peut également être utilisé est LibreOffice. Les commandes peuvent différer un peu selon les programmes, mais l’idée générale est la même.
Les tableurs englobent de nombreuses choses que nous devons pouvoir faire en tant que chercheurs. Nous pouvons les utiliser pour :
- La saisie des données
- Organisation des données
- Sous-ensemble et tri des données
- Statistiques
- Traçage
Les tableurs utilisent des tableaux pour représenter et afficher les données. Les données formatées sous forme de tableaux sont également le thème principal de ce chapitre, et nous verrons comment organiser les données en tableaux de manière standardisée pour assurer une analyse efficace en aval.
Défi : Discutez des points suivants avec votre voisin
- Avez-vous utilisé des feuilles de calcul, dans vos recherches, vos cours, ou à la maison ?
- Quel type d’opérations effectuez-vous dans des feuilles de calcul ?
- Selon vous, pour lesquels les feuilles de calcul sont-elles utiles ?
- Avez-vous accidentellement fait quelque chose dans un tableur qui vous a rendu frustré ou triste ?
Problèmes avec les feuilles de calcul
Les feuilles de calcul sont utiles pour la saisie de données, mais en réalité, nous avons tendance à utiliser des tableurs pour bien plus que la saisie de données. Nous les utilisons pour créer des tableaux de données pour les publications, pour générer des statistiques récapitulatives et réaliser des chiffres.
Générer des tableaux pour des publications dans une feuille de calcul n’est pas optimal - souvent, lors du formatage d’un tableau de données, nous rapportons les principales statistiques récapitulatives d’une manière qui n’est pas vraiment destinée à être lue comme des données, et implique souvent un formatage spécial (fusion de cellules, création de bordures, préférences esthétiques pour les couleurs, etc.). Nous vous conseillons de effectuer ce genre d’opération au sein de votre logiciel d’édition de documents.
Ces deux dernières applications, génératrices de statistiques et de chiffres, doivent être utilisées avec précaution : en raison de la nature graphique, par glisser-déposer des tableurs, il peut être très difficile, voire impossible, de reproduisez vos pas (et encore moins retracer ceux de quelqu’un d’autre), en particulier si vos statistiques ou chiffres nécessitent que vous fassiez des calculs plus complexes. De plus, en effectuant des calculs dans une feuille de calcul, il est facile d’appliquer accidentellement une formule légèrement différente à plusieurs cellules adjacentes. Lorsque vous utilisez un programme de statistiques basé sur une ligne de commande comme R ou SAS, il est pratiquement impossible d’appliquer un calcul à une observation de votre ensemble de données mais pas à une autre, sauf si vous le faites cela exprès.
Utiliser des feuilles de calcul pour la saisie et le nettoyage des données
Dans cette leçon, nous supposerons que vous utilisez très probablement Excel comme votre tableur principal - il en existe d’autres (gnumeric, Calc d’OpenOffice), et leurs fonctionnalités sont similaires, mais Excel semble est le programme le plus utilisé par les biologistes et les chercheurs biomédicaux.
Dans cette leçon, nous allons parler de :
- Formatage des tableaux de données dans des feuilles de calcul
- Problèmes de formatage
- Exporter des données
Formatage des tableaux de données dans des feuilles de calcul
Des questions
- Comment formater les données dans des feuilles de calcul pour une utilisation efficace des données ?
Objectifs
Décrire les meilleures pratiques pour la saisie et le formatage des données dans les feuilles de calcul .
Appliquez les meilleures pratiques pour organiser les variables et les observations dans une feuille de calcul .
Points clés
Ne modifiez jamais vos données brutes. Faites toujours une copie avant d’apporter des modifications.
Gardez une trace de toutes les étapes que vous suivez pour nettoyer vos données dans un fichier texte brut .
Organisez vos données selon des principes de données ordonnés.
L’erreur la plus courante est de traiter les tableurs comme des cahiers de laboratoire , c’est-à-dire de s’appuyer sur le contexte, les notes dans la marge, la disposition spatiale des données et des champs pour transmettre des informations. En tant qu’humains, nous pouvons (généralement) interpréter ces choses, mais les ordinateurs ne voient pas les informations de la même manière, et à moins que nous expliquions à l’ordinateur ce que chaque signifie (et ça peut être dur !), il ne pourra pas voir comment nos données s’emboîtent.
En utilisant la puissance des ordinateurs, nous pouvons gérer et analyser les données de manière beaucoup plus efficace et plus rapide, mais pour utiliser cette puissance, nous devons configurer nos données pour que l’ordinateur puisse comprenez-le (et les ordinateurs sont très littéraux).
C’est pourquoi il est extrêmement important de mettre en place des tableaux bien formatés dès le départ - avant même de commencer à saisir les données de votre toute première expérience préliminaire . L’organisation des données est le fondement de votre projet de recherche. Cela peut rendre plus facile ou plus difficile le travail avec vos données tout au long de votre analyse, il vaut donc la peine de réfléchir au moment où vous effectuez votre saisie de données ou configurez votre expérience. Vous pouvez configurer les choses de différentes manières dans des feuilles de calcul, mais certains de ces choix peuvent limiter votre capacité à travailler avec les données dans d’autres programmes ou vous empêcher de- Dans 6 mois ou votre collaborateur travaillera avec les données.
Remarque : les meilleures mises en page/formats (ainsi que les logiciels et les interfaces ) pour la saisie et l’analyse des données peuvent être différentes. Il est important d’en tenir compte, et idéalement d’automatiser la conversion de l’un à l’autre.
Garder une trace de vos analyses
Lorsque vous travaillez avec des feuilles de calcul, lors d’un nettoyage de données ou d’analyses , il est très facile de vous retrouver avec une feuille de calcul qui semble très différente de celle avec laquelle vous avez commencé. Afin de pouvoir reproduire vos analyses ou comprendre ce que vous avez fait lorsqu’un évaluateur ou un instructeur demande une analyse différente, vous devez
créez un nouveau fichier avec vos données nettoyées ou analysées. Ne modifiez pas l’ensemble de données d’origine, sinon vous ne saurez jamais par où vous avez commencé !
gardez une trace des étapes que vous avez suivies lors de votre nettoyage ou de votre analyse. Vous devez suivre ces étapes comme vous le feriez pour n’importe quelle étape d’une expérience. Nous vous recommandons de le faire dans un fichier texte brut stocké dans le même dossier que le fichier de données.
Ceci pourrait être un exemple de configuration de feuille de calcul :
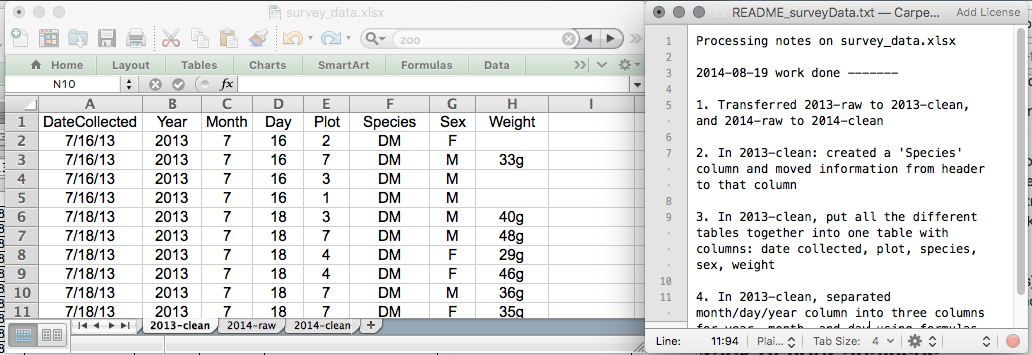
Mettez ces principes en pratique aujourd’hui lors de vos exercices.
Bien que la gestion des versions soit hors de portée de ce cours, vous pouvez consulter la leçon Menuiseries sur ‘Git’ pour découvrez comment maintenir le contrôle de version sur vos données. Voir aussi ce blog post pour un tutoriel rapide ou @Perez-Riverol:2016 pour une approche plus orientée recherche cas d’utilisation.
Structuration des données dans des feuilles de calcul
Les règles cardinales de l’utilisation des tableurs pour les données :
- Mettez toutes vos variables dans des colonnes - la chose que vous mesurez, comme « poids » ou « température ».
- Placez chaque observation dans sa propre rangée.
- Ne combinez pas plusieurs informations dans une seule cellule. Parfois cela semble être une chose, mais pensez que si c’est la seule façon vous voudrez pouvoir utiliser ou trier ces données.
- Laissez les données brutes brutes – ne les modifiez pas !
- Exportez les données nettoyées dans un format texte tel que le format CSV (valeurs séparées par des virgules). Cela garantit que n’importe qui peut utiliser les données et est requis par la plupart des référentiels de données.
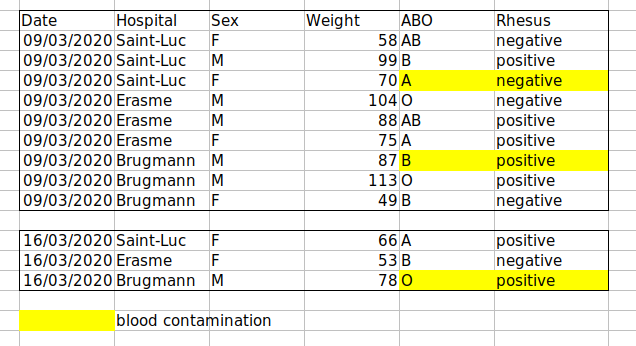
Par exemple, nous disposons de données provenant de patients ayant visité plusieurs hôpitaux à Bruxelles, en Belgique. Ils ont enregistré la date de la visite, l’hôpital, le sexe, le poids et le groupe sanguin des patients.
Si nous devions garder une trace des données comme ceci :
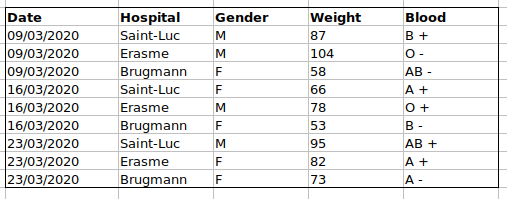
le problème est que les groupes ABO et Rhésus sont dans la même
colonne de type Blood . Donc, s’ils voulaient examiner
toutes les observations du groupe A ou examiner les distributions de
poids par groupe ABO, il serait difficile de le faire en utilisant cette
configuration de données. Si à la place nous mettions les groupes ABO et
Rhésus dans des colonnes différentes, vous voyez que ce serait beaucoup
plus facile.
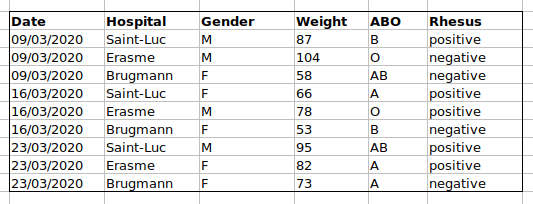
Une règle importante lors de la création d’une feuille de données est que les colonnes sont utilisées pour les variables et les lignes sont utilisées pour les observations :
- les colonnes sont des variables
- les lignes sont des observations
- les cellules sont des valeurs individuelles
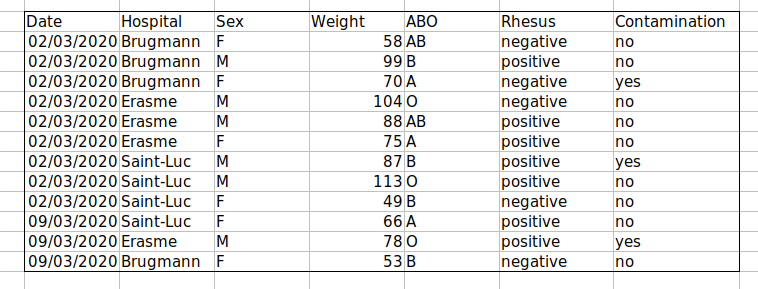
Défi : Nous allons prendre un ensemble de données désordonné et décrire comment nous allons le nettoyer.
Téléchargez un ensemble de données désordonné en cliquant sur ici.
Ouvrez les données dans un tableur.
Vous pouvez voir qu’il y a deux onglets. Les données contiennent diverses variables cliniques enregistrées dans divers hôpitaux bruxellois lors des première et deuxième vagues de COVID-19 en 2020. Comme vous pouvez le constater, les données ont été enregistrées différemment lors des vagues de mars et novembre. Vous êtes désormais la personne en charge de ce projet et vous souhaitez que puisse commencer à analyser les données.
Avec la personne à côté de vous, identifiez ce qui ne va pas avec cette feuille de calcul . Discutez également des étapes que vous devrez suivre pour nettoyer les onglets de la première et de la deuxième vague, et pour les rassembler tous dans une seule feuille de calcul .
Important : N’oubliez pas notre premier conseil : pour créer un nouveau fichier (ou onglet) pour les données nettoyées, ne modifiez jamais vos données (brutes) d’origine.
Après avoir effectué cet exercice, nous discuterons en groupe de ce qui n’allait pas avec ces données et de la manière dont vous pourriez y remédier.
Défi : Une fois que vous avez rangé les données, répondez aux questions suivantes :
- Combien d’hommes et de femmes ont participé à l’étude ?
- Combien de types A, AB et B ont été testés ?
- Comme ci-dessus, mais sans tenir compte des échantillons contaminés ?
- Combien de Rhésus + et - ont été testés ?
- Combien de donneurs universels (O-) ont été testés ?
- Quel est le poids moyen des hommes AB ?
- Combien d’échantillons ont été testés dans les différents hôpitaux ?
Une excellente référence, en particulier en ce qui concerne les scripts R est l’article Tidy Data @Wickham:2014.
Erreurs courantes dans les feuilles de calcul
Des questions
- Quels sont les défis courants liés au formatage des données dans les feuilles de calcul et comment pouvons-nous les éviter ?
Objectifs
- Reconnaître et résoudre les problèmes courants de formatage des feuilles de calcul.
Points clés
- Évitez d’utiliser plusieurs tableaux dans une même feuille de calcul.
- Évitez de répartir les données sur plusieurs onglets.
- Enregistrez les zéros comme des zéros.
- Utilisez une valeur nulle appropriée pour enregistrer les données manquantes.
- N’utilisez pas de formatage pour transmettre des informations ou pour donner une jolie apparence à votre feuille de calcul.
- Placez les commentaires dans une colonne séparée.
- Enregistrez les unités dans les en-têtes de colonnes.
- Incluez une seule information dans une cellule.
- Évitez les espaces, les chiffres et les caractères spéciaux dans les en-têtes de colonnes.
- Évitez les caractères spéciaux dans vos données.
- Enregistrez les métadonnées dans un fichier texte brut séparé.
Il y a quelques erreurs potentielles à surveiller dans vos propres données ainsi que dans les données de vos collaborateurs ou d’Internet. Si vous êtes conscient des erreurs et de l’effet négatif possible sur l’analyse des données en aval et l’interprétation des résultats, cela pourrait vous motiver ainsi que les membres de votre projet à essayer de les éviter. Apporter de petits changements à la façon dont vous formatez vos données dans des feuilles de calcul peut avoir un grand impact sur l’efficacité et la fiabilité en matière de nettoyage et d’analyse des données.
- Utiliser plusieurs tables
- Utiliser plusieurs onglets
- Ne pas remplir les zéros
- Utilisation de valeurs nulles problématiques
- Utiliser le formatage pour transmettre des informations
- Utiliser le formatage pour rendre la fiche technique jolie
- Placer des commentaires ou des unités dans des cellules
- Saisie de plusieurs informations dans une cellule
- Utilisation de noms de champs problématiques
- Utilisation de caractères spéciaux dans les données
- Inclusion de métadonnées dans le tableau de données
Utilisation de plusieurs tables
Une stratégie courante consiste à créer plusieurs tableaux de données dans une seule feuille de calcul . Cela perturbe l’ordinateur, alors ne faites pas ça ! Lorsque vous créez plusieurs tableaux dans une même feuille de calcul, vous établissez de fausses associations entre les éléments pour l’ordinateur, qui considère chaque ligne comme une observation. Vous utilisez également potentiellement le même nom de champ à plusieurs endroits, ce qui rendra plus difficile le nettoyage de vos données dans un formulaire utilisable. L’exemple ci-dessous illustre le problème :
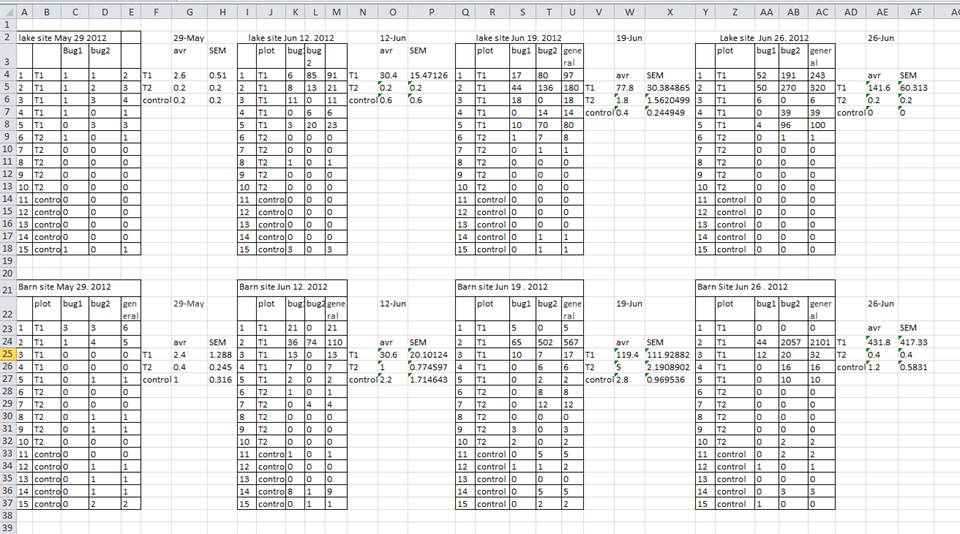
Dans l’exemple ci-dessus, l’ordinateur verra (par exemple) la ligne 4 et supposera que toutes les colonnes A-AF font référence au même échantillon. Cette ligne représente en fait quatre échantillons distincts (échantillon 1 pour chacune des quatre dates de collecte différentes - 29 mai, 12 juin, 19 juin et 26 juin), ainsi que quelques statistiques récapitulatives calculées (une moyenne (avr) et une erreur type de mesure (SEM)) pour deux de ces échantillons. D’autres lignes posent également problème.
Utiliser plusieurs onglets
Mais qu’en est-il des onglets du classeur ? Cela semble être un moyen simple d’organiser les données , n’est-ce pas ? Eh bien, oui et non. Lorsque vous créez des onglets supplémentaires, vous ne parvenez pas à permettre à l’ordinateur de voir les connexions dans les données qui s’y trouvent (vous devez introduire des fonctions spécifiques à l’application de feuille de calcul ou des scripts pour garantir cette connexion). Supposons, par exemple, que vous aillez créé un onglet séparé pour chaque jour où vous prenez une mesure.
Ce n’est pas une bonne pratique pour deux raisons :
vous êtes plus susceptible d’ajouter accidentellement des incohérences à vos données si à chaque fois que vous prenez une mesure, vous commencez à enregistrer les données dans un nouvel onglet, et
même si vous parvenez à empêcher toute incohérence, vous vous ajoutez une étape supplémentaire avant même d’analyser les données car vous devrez combiner ces données en une seule table de données. Vous devrez indiquer explicitement à l’ordinateur comment combiner les onglets - et si les onglets ne sont pas formatés de manière cohérente, vous devrez peut-être même le faire manuellement.
La prochaine fois que vous saisirez des données et que vous créerez un autre onglet ou un autre tableau, demandez-vous si vous pourriez éviter d’ajouter cet onglet en ajoutant une autre colonne à votre feuille de calcul d’origine. Nous avons utilisé plusieurs onglets dans notre exemple de fichier de données désordonné, mais vous avez maintenant vu comment vous pouvez réorganiser vos données pour les consolider entre les onglets.
Votre fiche technique peut devenir très longue au cours de l’expérience . Cela rend plus difficile la saisie des données si vous ne voyez pas vos en-têtes en haut de la feuille de calcul. Mais ne répétez pas votre ligne d’en-tête . Ceux-ci peuvent facilement être mélangés aux données, entraînant des problèmes plus tard. Au lieu de cela, vous pouvez geler les en-têtes de la colonne afin qu’ils restent visibles même lorsque vous disposez d’une feuille de calcul comportant plusieurs lignes.
Ne pas remplir les zéros
Il se peut que lorsque vous mesurez quelque chose, il s’agisse généralement d’un zéro, , par exemple le nombre de fois qu’un lapin est observé dans l’enquête. Pourquoi s’embêter à écrire le chiffre zéro dans cette colonne, alors qu’il s’agit principalement de zéros ?
Cependant, il existe une différence entre un zéro et une cellule vide dans une feuille de calcul . Pour l’ordinateur, un zéro est en réalité une donnée. Vous l’avez mesuré ou compté. Une cellule vide signifie qu’elle n’a pas été mesurée et l’ordinateur l’interprétera comme une valeur inconnue (également appelée valeur nulle ou valeur manquante).
Les feuilles de calcul ou les programmes statistiques interpréteront probablement mal les cellules vides que vous envisagez d’être des zéros. En n’entrant pas la valeur de votre observation, vous dites à votre ordinateur de représenter ces données comme inconnues ou manquantes (nulles). Cela peut entraîner des problèmes lors des calculs ou analyses ultérieurs. Par exemple, la moyenne d’un ensemble de nombres qui comprend une seule valeur nulle est toujours nulle (car l’ordinateur ne peut pas deviner la valeur des observations manquantes). Parce que de cela, il est très important d’enregistrer les zéros comme des zéros et vraiment les données manquantes comme des valeurs nulles.
Utilisation de valeurs nulles problématiques
Exemple : utiliser -999 ou d’autres valeurs numériques (ou zéro) pour représente les données manquantes.
Solutions:
Il existe plusieurs raisons pour lesquelles les valeurs nulles sont représentées différemment dans un ensemble de données. Parfois, des valeurs nulles déroutantes sont automatiquement enregistrées à partir de l’appareil de mesure. Si tel est le cas, vous ne pouvez pas faire grand-chose, mais cela peut être résolu lors du nettoyage des données avec un outil comme OpenRefine avant analyse. D’autres fois, différentes valeurs nulles sont utilisées pour transmettre différentes raisons pour lesquelles les données ne sont pas là. Il s’agit d’une information importante à capturer, mais elle utilise en fait une seule colonne pour capturer deux informations. Like for using formatting to convey information it would be good here to create a new column like ‘data_missing’ and use that column to capture the different reasons.
Quelle que soit la raison, c’est un problème si des données inconnues ou manquantes sont enregistrées comme -999, 999 ou 0.
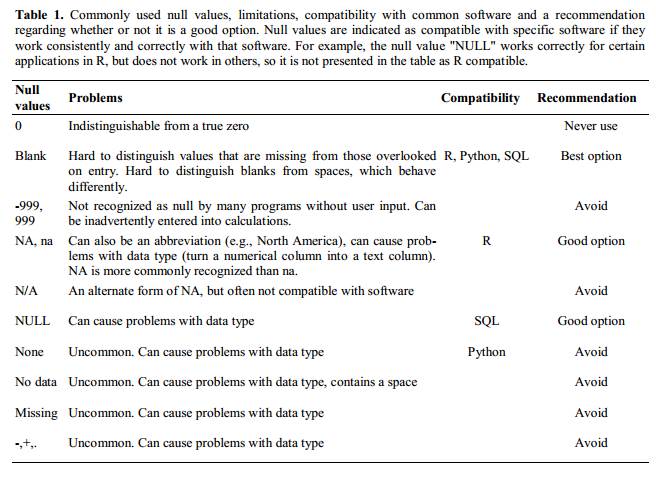
Many statistical programs will not recognise that these are intended to represent missing (null) values. La façon dont ces valeurs sont interprétées dépendra du logiciel que vous utilisez pour analyser vos données. Il est essentiel d’utiliser un indicateur nul clairement défini et cohérent.
Les blancs (la plupart des applications) et NA (pour R) sont de bons choix . @White : 2013 explique les bons choix pour indiquer des valeurs nulles pour différentes applications logicielles dans leur article :
Utiliser le formatage pour transmettre des informations
Exemple : mise en évidence des cellules, des lignes ou des colonnes qui doivent être exclues d’une analyse, en laissant des lignes vides pour indiquer séparations dans les données.
Solution : créez un nouveau champ pour coder les données qui doivent être exclues.
Utiliser le formatage pour rendre la fiche technique jolie {#formatting_pretty}
Exemple : fusion de cellules.
Solution : Si vous ne faites pas attention, le formatage d’une feuille de calcul pour qu’elle soit plus esthétiquement peut compromettre la capacité de votre ordinateur à voir les associations dans les données. Les cellules fusionnées rendront vos données illisibles par les logiciels de statistiques. Pensez à restructurer vos données de telle manière que vous n’aurez pas besoin de fusionner des cellules pour organiser vos données.
Placer des commentaires ou des unités dans des cellules
La plupart des logiciels d’analyse ne peuvent pas voir les commentaires Excel ou LibreOffice, et serait dérouté par les commentaires placés dans vos cellules de données. Comme décrit ci-dessus pour le formatage, créez un autre champ si vous devez ajouter des notes aux cellules. De même, n’incluez pas d’unités dans les cellules : idéalement, toutes les mesures que vous placez dans une colonne devraient être dans la même unité , mais si pour une raison quelconque ce n’est pas le cas, créez un autre champ et spécifient les unités dans lesquelles se trouve la cellule.
Saisir plusieurs informations dans une cellule
Exemple : Enregistrement des groupes ABO et Rhésus dans une seule cellule, tels que A+, B+, A-, …
Solution : N’incluez pas plus d’une information dans une cellule . Cela limitera les façons dont vous pourrez analyser vos données. Si vous avez besoin de ces deux mesures, concevez votre fiche technique pour inclure ces informations. Par exemple, incluez une colonne pour le groupe ABO et une pour le groupe Rhésus.
Utilisation de noms de champs problématiques {#field_name}
Choisissez des noms de champs descriptifs, mais veillez à ne pas inclure d’espaces, de chiffres ou de caractères spéciaux de quelque nature que ce soit. Les espaces peuvent être mal interprétés par les analyseurs qui utilisent des espaces comme délimiteurs et certains programmes n’aiment pas les noms de champs qui sont des chaînes de texte commençant par nombres.
Les traits de soulignement (_) sont une bonne
alternative aux espaces. Pensez à écrire les noms en casse chameau
(comme ceci : SampleFileName) pour améliorer la lisibilité de .
N’oubliez pas que les abréviations qui ont un sens pour le moment ne
seront peut-être pas si évidentes dans 6 mois, mais n’en faites pas trop
avec des noms qui sont excessivement longs. L’inclusion des unités dans
les noms de champs évite toute confusion et permet aux autres
d’interpréter facilement vos champs.
Exemples
| Réputation | Bonne alternative | Éviter |
|---|---|---|
| Max_temp_C | Température maximale | Température maximale (°C) |
| Précipitations_mm | Précipitation | précm |
| Moyenne_année_croissance | Croissance annuelle moyenne | Croissance moyenne/an |
| sexe | sexe | H/F |
| poids | poids | w. |
| cellule_type | Type de cellule | Type de cellule |
| Observation_01 | première_observation | 1er Obs. |
Utilisation de caractères spéciaux dans les données
Exemple : Vous traitez votre tableur comme un traitement de texte lorsque vous rédigez des notes, par exemple en copiant des données directement depuis Word ou d’autres applications.
Solution : Il s’agit d’une stratégie courante. Par exemple, lorsqu’ils écrivent un texte plus long dans une cellule, les utilisateurs incluent souvent des sauts de ligne, des tirets cadratins, , etc. dans leur feuille de calcul. De plus, lors de la copie de données à partir d’applications telles que Word, le formatage et les caractères non standard (tels que les guillemets alignés à gauche et à droite) sont inclus. Lors de l’exportation de ces données dans un environnement de codage/statistique ou dans une base de données relationnelle, des choses dangereuses peuvent se produire, comme des lignes coupées en deux et des erreurs d’encodage générées.
La meilleure pratique générale consiste à éviter d’ajouter des caractères tels que des nouvelles lignes, des tabulations et des tabulations verticales. In other words, treat a text cell as if it were a simple web form that can only contain text and spaces.
Inclusion de métadonnées dans le tableau de données
Exemple : Vous ajoutez une légende en haut ou en bas de votre tableau de données expliquant la signification des colonnes, les unités, les exceptions, etc.
Solution : L’enregistrement des données sur vos données (“métadonnées”) est essentiel. You may be on intimate terms with your dataset while you are collecting and analysing it, but the chances that you will still remember that the variable “sglmemgp” means single member of group, for example, or the exact algorithm you used to transform a variable or create a derived one, after a few months, a year, or more are slim.
De plus, il existe de nombreuses raisons pour lesquelles d’autres personnes pourraient vouloir examiner ou utiliser vos données : pour comprendre vos conclusions, pour vérifier vos conclusions, pour examiner la publication que vous avez soumise, pour reproduire vos résultats, pour concevoir une étude similaire, ou même archiver vos données pour y accéder et réutiliser par d’autres. Bien que les données numériques soient par définition lisibles par machine, comprendre leur signification est un travail pour les êtres humains. L’importance de documenter vos données pendant la phase de collecte et d’analyse de votre recherche ne peut être surestimée, surtout si votre recherche doit faire partie du dossier scientifique .
Cependant, les métadonnées ne doivent pas être contenues dans le fichier de données lui-même. Contrairement à un tableau dans un article ou un fichier supplémentaire, les métadonnées (sous sous forme de légendes) ne doivent pas être incluses dans un fichier de données puisque ces informations ne sont pas des données, et leur inclusion peut perturber la façon dont les programmes informatiques interprètent votre fichier de données. Les métadonnées doivent plutôt être stockées en tant que fichier distinct dans le même répertoire que votre fichier de données, de préférence au format texte brut avec un nom qui l’associe clairement à votre fichier de données. . Because metadata files are free text format, they also allow you to encode comments, units, information about how null values are encoded, etc. that are important to document but can disrupt the formatting of your data file.
De plus, les métadonnées au niveau du fichier ou de la base de données décrivent comment les fichiers qui constituent l’ensemble de données sont liés les uns aux autres ; dans quel format ils se trouvent ; et s’ils remplacent ou sont remplacés par les fichiers précédents. Un fichier readme.txt au niveau du dossier est la manière classique de comptabiliser tous les fichiers et dossiers d’un projet.
(Texte sur les métadonnées adapté du cours en ligne Research Data MANTRA par EDINA et Data Library, Université d’Édimbourg. MANTRA est sous licence Creative Commons Attribution 4.0 International Licence.)
Exporter des données
Question
- Comment pouvons-nous exporter des données à partir de feuilles de calcul d’une manière utile pour les applications en aval ?
Objectifs
- Stockez les données des feuilles de calcul dans des formats de fichiers universels.
- Exportez les données d’une feuille de calcul vers un fichier CSV.
Points clés
Les données stockées dans des formats de feuilles de calcul courants ne seront souvent pas lues correctement dans un logiciel d’analyse de données, introduisant des erreurs dans vos données .
L’exportation de données à partir de feuilles de calcul vers des formats tels que CSV ou TSV les place dans un format qui peut être utilisé de manière cohérente par la plupart des programmes.
Le stockage des données avec lesquelles vous allez travailler pour
vos analyses dans le format de fichier Excel par défaut
(*.xls ou *.xlsx - selon la version d’Excel )
n’est pas une bonne idée. Pourquoi?
Parce qu’il s’agit d’un format propriétaire, et qu’il est possible que dans le futur, la technologie n’existe pas (ou devienne suffisamment rare) pour rendre l’ouverture du fichier peu pratique, voire impossible. déposer.
D’autres logiciels de tableur peuvent ne pas être en mesure d’ouvrir les fichiers enregistrés dans un format Excel propriétaire .
Différentes versions d’Excel peuvent gérer les données différemment, entraînant des incohérences. Dates est un exemple bien documenté d’incohérences dans le stockage de données.
Enfin, de plus en plus de revues et d’organismes subventionnaires vous demandent de déposer vos données dans un référentiel de données, et la plupart d’entre elles n’acceptent pas le format Excel. Il doit être dans l’un des formats discutés ci-dessous.
Les points ci-dessus s’appliquent également à d’autres formats tels que les formats open data utilisés par LibreOffice / Open Office. Ces formats ne sont pas statiques et ne sont pas analysés de la même manière par différents packages logiciels .
Le stockage des données dans un format universel, ouvert et statique aidera à résoudre ce problème. Essayez les valeurs délimitées par des tabulations (valeurs séparées par des tabulations ou TSV) ou délimitées par des virgules (valeurs séparées par des virgules ou CSV). Les fichiers CSV sont des fichiers texte simples où les colonnes sont séparées par des virgules, d’où « valeurs séparées par des virgules » ou CSV. L’avantage d’un fichier CSV par rapport à un Excel/SPSS/etc. est que nous pouvons ouvrir et lire un fichier CSV en utilisant à peu près n’importe quel logiciel, y compris des éditeurs de texte brut comme TextEdit ou NotePad. Les données d’un fichier CSV peuvent également être facilement importées dans d’autres formats et environnements, tels que SQLite et R. Nous ne sommes pas liés à une certaine version d’un certain programme coûteux lorsque nous travaillons avec CSV fichiers, c’est donc un bon format avec lequel travailler pour une portabilité maximale et une endurance. La plupart des tableurs peuvent facilement enregistrer au format texte délimité comme CSV, bien qu’ils puissent vous avertir lors de l’exportation du fichier.
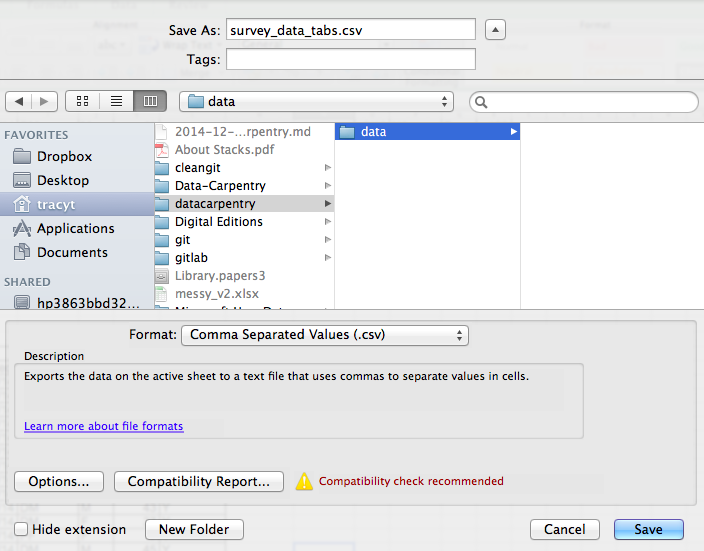
Pour enregistrer un fichier que vous avez ouvert dans Excel au format CSV :
- Dans le menu supérieur, sélectionnez « Fichier » et « Enregistrer sous ».
- Dans le champ « Format », dans la liste, sélectionnez « Valeurs
séparées par des virgules » (
*.csv). - Vérifiez le nom du fichier et l’emplacement où vous souhaitez l’enregistrer et cliquez sur « Enregistrer ».
Une remarque importante pour la rétrocompatibilité : vous pouvez ouvrir les fichiers CSV dans Excel !
Une note sur R et xls : Il existe des
packages R qui peuvent lire les fichiers xls (ainsi que les
feuilles de calcul Google). Il est même possible d’accéder à différentes
feuilles de calcul dans les documents xls.
Mais
- certains d’entre eux ne fonctionnent que sous Windows.
- cela équivaut à remplacer une exportation (simple mais manuelle)
vers
csvpar complexité/dépendances supplémentaires dans le code R d’analyse des données. - Les meilleures pratiques en matière de formatage des données s’appliquent toujours.
- Y a-t-il vraiment une bonne raison pour laquelle
csv(ou similaire) n’est pas adéquat ?
Mises en garde concernant les virgules
Dans certains ensembles de données, les valeurs des données elles-mêmes peuvent inclure des virgules (,). Dans ce cas, le logiciel que vous utilisez (y compris Excel) affichera très probablement de manière incorrecte les données en colonnes. En effet, les virgules qui font partie des valeurs de données seront interprétées comme des délimiteurs .
Par exemple, nos données pourraient ressembler à ceci :
species_id,genus,species,taxa
AB,Amphispiza,bilineata,Bird
AH,Ammospermophilus,harrisi,Rodent, not censused
AS,Ammodramus,savannarum,Bird
BA,Baiomys,taylori,RodentDans l’enregistrement « AH, Ammospermophilus, harrisi, Rongeur, non recensé », la valeur pour « taxons » comprend une virgule (« Rongeur, non recensé »). Si nous essayons de lire ce qui précède dans Excel (ou un autre tableur), nous obtiendrons quelque chose comme ceci :
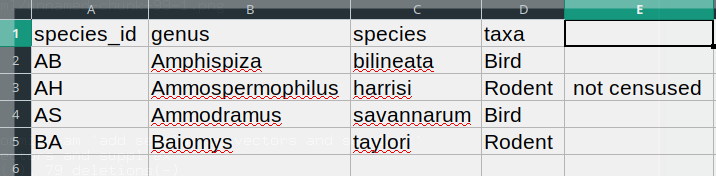
La valeur de « taxons » a été divisée en deux colonnes (au lieu d’être placée dans une seule colonne « D »). Cela peut se propager à un certain nombre d’autres erreurs . Par exemple, la colonne supplémentaire sera interprétée comme une colonne avec de nombreuses valeurs manquantes (et sans en-tête approprié). En plus de cela, la valeur dans la colonne « D » pour l’enregistrement de la ligne 3 (donc celle où la valeur de « taxons » contenait la virgule) est désormais incorrecte.
Si vous souhaitez stocker vos données au format csv et
vous attendez à ce que vos valeurs de données contiennent des virgules,
vous pouvez éviter le problème évoqué ci-dessus en mettant les valeurs
entre guillemets (““). En appliquant cette règle, nos données pourraient
ressembler à ceci :
species_id,genus,species,taxa
"AB","Amphispiza","bilineata","Bird"
"AH","Ammospermophilus","harrisi","Rodent, not censused"
"AS","Ammodramus","savannarum","Bird"
"BA","Baiomys","taylori","Rodent"Désormais, l’ouverture de ce fichier en tant que « csv » dans Excel n’entraînera pas une colonne supplémentaire, car Excel n’utilisera que des virgules qui se trouvent en dehors des guillemets comme caractères de délimitation.
Alternativement, si vous travaillez avec des données contenant des virgules, vous devrez probablement utiliser un autre délimiteur lorsque vous travaillerez dans une feuille de calcul 1. Dans ce cas, pensez à utiliser des tabulations comme délimiteur et à travailler avec des fichiers TSV. Les fichiers TSV peuvent être exportés à partir de feuilles de calcul de la même manière que les fichiers CSV.
Si vous travaillez avec un ensemble de données déjà existant dans lequel les valeurs de données ne sont pas incluses entre “” mais qui ont à la fois des virgules comme délimiteurs et des parties de valeurs de données, vous êtes potentiellement confronté à un problème majeur. avec nettoyage des données. Si l’ensemble de données que vous traitez contient des centaines ou des milliers d’enregistrements, nettoyez-les manuellement (soit en supprimant les virgules des valeurs de données, soit en mettant les valeurs entre guillemets - ““) non seulement va prendre des heures et des heures, mais peut finir par vous amener à introduire accidentellement de nombreuses erreurs.
Le nettoyage des ensembles de données est l’un des problèmes majeurs dans de nombreuses disciplines scientifiques . L’approche dépend presque toujours du contexte particulier. Cependant, il est recommandé de nettoyer les données de manière automatisée, par exemple en écrivant et en exécutant un script. Les leçons Python et R vous donneront les bases pour développer des compétences permettant de créer des scripts pertinents.
Résumé

Un flux de travail typique d’analyse de données est illustré dans la figure ci-dessus, où les données sont transformées, visualisées et modélisées à plusieurs reprises. Cette itération est répétée plusieurs fois jusqu’à ce que les données soient comprises. Cependant, dans de nombreux cas réels, la plupart du temps est consacré au nettoyage et à la préparation des données, plutôt qu’à leur analyse et à leur compréhension .
An agile data analysis workflow, with several fast iterations of the transform/visualise/model cycle is only feasible if the data is formatted in a predictable way and one can reason about the data without having to look at it and/or fix it.
Ceci est particulièrement pertinent dans les pays européens où la virgule est utilisée comme séparateur décimal . Dans de tels cas, le séparateur de valeurs par défaut dans un fichier csv sera le point-virgule (;), ou les valeurs seront systématiquement entre guillemets.↩︎