Content from Organisation des données avec des feuilles de calcul
Last updated on 2025-05-05 | Edit this page
Estimated time: 60 minutes
Overview
Questions
- Comment organiser des données tabulaires ?
Objectives
- Découvrir les feuilles de calcul, leurs forces et leurs faiblesses.
- Comment formater les données dans des feuilles de calcul pour une utilisation efficace des données ?
- Découvrir les erreurs courantes des feuilles de calcul et comment les corriger.
- Organiser vos données selon des principes de données propres.
- Découvrir les formats de feuilles de calcul textuels tels que les formats séparés par des virgules (CSV) ou par des tabulations (TSV).
Cet épisode est basé sur la leçon Data Analysis and Visualisation in R for Ecologists de Data Carpentries.
Tableurs
Question
- Quels sont les principes de base d’utilisation des feuilles de calcul pour une bonne organisation des données ?
Objectifs
- Décrire les bonnes pratiques pour organiser les données afin que les ordinateurs puissent en faire la meilleure utilisation.
Point clé
- Une bonne organisation des données est la base de tout projet de recherche.
Une bonne organisation des données est la base de votre projet de recherche . La plupart des chercheurs disposent de données ou effectuent la saisie de données dans des feuilles de calcul . Les tableurs sont des interfaces graphiques très utiles pour concevoir des tableaux de données et gérer des fonctions de contrôle qualité de données très basiques. Voir aussi @Broman : 2018.
Aperçu de la feuille de calcul
Les feuilles de calcul sont utiles pour la saisie de données. Nous avons donc beaucoup de données dans des feuilles de calcul. Une grande partie de votre temps en tant que chercheur sera consacrée à cette étape de « gestion des données ». Ce n’est pas le plus amusant, mais c’est nécessaire. Nous vous apprendrons comment réfléchir à l’organisation des données et quelques pratiques pour une gestion plus efficace des données.
Ce que cette leçon ne vous apprendra pas
- Comment faire des statistiques dans une feuille de calcul
- Comment faire un graphique dans une feuille de calcul
- Comment écrire du code dans des tableurs
Si vous cherchez à faire cela, une bonne référence est Head First Excel, publié par O’Reilly.
Pourquoi n’enseignons-nous pas l’analyse de données dans des feuilles de calcul
L’analyse de données dans des feuilles de calcul nécessite généralement beaucoup de travail manuel. Si vous souhaitez modifier un paramètre ou exécuter une analyse avec un nouvel ensemble de données, vous devez généralement tout refaire à la main. (Nous savons que vous pouvez créer des macros, mais voir le point suivant.)
Il est également difficile de suivre ou de reproduire des analyses statistiques ou graphiques effectuées dans des tableurs lorsque vous souhaitez revenir à votre travail ou que quelqu’un vous demande des détails sur votre analyse.
De nombreux tableurs sont disponibles. Étant donné que la plupart des participants utilisent Excel comme tableur principal, cette leçon utilisera des exemples Excel. Un tableur gratuit qui peut également être utilisé est LibreOffice. Les commandes peuvent différer un peu selon les programmes, mais l’idée générale est la même.
Les tableurs englobent de nombreuses choses que nous devons être en mesure de faire en tant que chercheurs. Nous pouvons les utiliser pour :
- La saisie des données
- L’organisation des données
- Extraire des sous-ensembles et trier des données
- Des statistiques
- Visualiser des données
Les tableurs utilisent des tableaux pour représenter et afficher les données. Les données formatées sous forme de tableaux sont également le thème principal de ce chapitre, et nous verrons comment organiser les données en tableaux de manière standardisée pour assurer une analyse efficace en aval.
Défi : Discutez des points suivants avec votre voisin
- Avez-vous utilisé des feuilles de calcul, dans vos recherches, vos cours, ou à la maison ?
- Quel type d’opérations effectuez-vous dans des feuilles de calcul ?
- Selon vous, pour lesquels les feuilles de calcul sont-elles utiles ?
- Avez-vous accidentellement fait quelque chose dans un tableur qui vous a rendu frustré ou triste ?
Problèmes avec les feuilles de calcul
Les feuilles de calcul sont utiles pour la saisie de données, mais en réalité, nous avons tendance à utiliser des tableurs pour bien plus que la saisie de données. Nous les utilisons pour créer des tableaux de données pour les publications, pour générer des statistiques récapitulatives et faire des graphiques.
Générer des tableaux pour des publications dans une feuille de calcul n’est pas optimal - souvent, lors du formatage d’un tableau de données, nous rapportons les principales statistiques récapitulatives d’une manière qui n’est pas vraiment destinée à être lue comme des données, et implique souvent un formatage spécial (fusion de cellules, création de bordures, préférences esthétiques pour les couleurs, etc.). Nous vous conseillons d’effectuer ce genre d’opération au sein de votre logiciel d’édition de documents.
Les deux dernières applications, la génération de statistiques et de graphiques, doivent être utilisées avec précaution : en raison de la nature graphique et glisser-déposer des tableurs, il peut être très difficile, voire impossible, de retracer vos pas (et encore plus de retracer ceux de quelqu’un d’autre), en particulier si vos statistiques ou graphiques nécessitent que vous fassiez des calculs plus complexes. De plus, en effectuant des calculs dans une feuille de calcul, il est facile d’appliquer accidentellement une formule légèrement différente à plusieurs cellules adjacentes. Lorsque vous utilisez un programme de statistiques basé sur une ligne de commande comme R ou SAS, il est pratiquement impossible d’appliquer un calcul à une observation de votre ensemble de données mais pas à une autre, sauf si vous le faites exprès.
Utiliser des feuilles de calcul pour la saisie et le nettoyage des données
Dans cette leçon, nous supposerons que vous utilisez très probablement Excel comme tableur principal - il en existe d’autres (gnumeric, Calc d’OpenOffice), et leurs fonctionnalités sont similaires, mais Excel semble être le programme le plus utilisé par les biologistes et les chercheurs en biomédical.
Dans cette leçon, nous allons parler de :
- Formatage de tableaux de données dans des feuilles de calcul
- Problèmes de formatage
- Exportation des données
Formatage des tableaux de données dans des feuilles de calcul
Questions
- Comment formater les données dans des feuilles de calcul pour une utilisation efficace des données ?
Objectifs
Décrire les meilleures pratiques pour la saisie et le formatage des données dans les feuilles de calcul.
Appliquer les meilleures pratiques pour organiser les variables et les observations dans une feuille de calcul.
Points clés
Ne modifiez jamais vos données brutes. Faites toujours une copie avant d’apporter des modifications.
Gardez une trace de toutes les étapes que vous suivez pour nettoyer vos données dans un fichier texte brut.
Organisez vos données selon les principes du tidyverse (des données ordonnées).
L’erreur la plus courante est de traiter les tableurs comme des cahiers de laboratoire, c’est-à-dire de s’appuyer sur le contexte, les notes dans la marge, la disposition spatiale des données et des champs pour transmettre des informations. En tant qu’êtres humains, nous pouvons (généralement) interpréter cela, mais les ordinateurs ne voient pas les informations de la même manière, et à moins que nous expliquions à l’ordinateur ce que tout signifie (et ça peut être dur !), il ne pourra pas voir comment nos données sont reliées.
En utilisant la puissance des ordinateurs, nous pouvons gérer et analyser les données de manière beaucoup plus efficace et plus rapide, mais pour utiliser cette puissance, nous devons configurer nos données pour que l’ordinateur puisse les comprendre (et les ordinateurs sont très littéraux).
C’est pourquoi il est extrêmement important de mettre en place des tableaux bien formatés dès le départ - avant même de commencer à saisir les données de votre toute première expérience préliminaire . L’organisation des données est le fondement de votre projet de recherche. Cela peut simplifier ou complexifier le travail avec vos données tout au long de votre analyse. Ça vaut donc la peine d’y réfléchir au moment où vous effectuez votre saisie de données ou configurez votre expérience. Vous pouvez configurer les choses de différentes manières dans des feuilles de calcul, mais certains de ces choix peuvent limiter votre capacité à travailler avec les données dans d’autres programmes ou empêcher quelqu’un d’autre de travailler avec les données.
Remarque : les meilleures mises en page/formats (ainsi que les logiciels et les interfaces ) pour la saisie et l’analyse des données peuvent être différents. Il est important d’en tenir compte, et idéalement d’automatiser la conversion de l’un à l’autre.
Garder une trace de vos analyses
Lorsque vous travaillez avec des feuilles de calcul, lors du nettoyage ou des analyses des données, il est très facile de vous retrouver avec une feuille de calcul qui semble très différente de celle avec laquelle vous avez commencée. Afin de pouvoir reproduire vos analyses ou comprendre ce que vous avez fait lorsqu’un relecteur ou un instructeur demande une analyse différente, vous devez
Créer un nouveau fichier avec vos données nettoyées ou analysées. Ne modifiez pas le jeu de données d’origine, sinon vous ne saurez jamais par où vous avez commencé !
Garder une trace des étapes que vous avez suivies lors de votre nettoyage ou de votre analyse. Vous devriez noter ces étapes comme vous le feriez pour n’importe quelle étape d’une expérience. Nous vous recommandons de le faire dans un fichier texte brut stocké dans le même dossier que le fichier de données.
Ceci pourrait être un exemple de configuration d’une feuille de calcul :
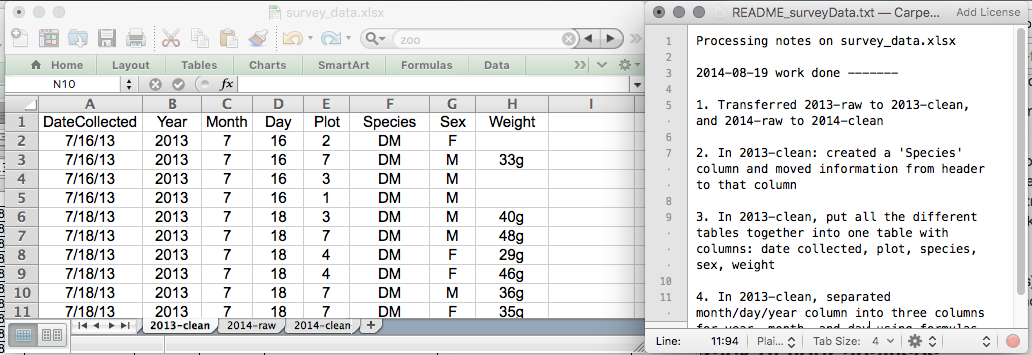
Mettez ces principes en pratique aujourd’hui lors de vos exercices.
Bien que la gestion des versions soit hors de portée de ce cours, vous pouvez consulter la leçon Carpentries sur ‘Git’ pour découvrir comment maintenir le contrôle des versions de vos données. Voir aussi cet article de blog pour un tutoriel rapide ou @Perez-Riverol:2016 pour un cas d’utilisation plus orienté vers la recherche.
Structuration des données dans des feuilles de calcul
Les règles cardinales de l’utilisation des tableurs pour les données :
- Mettez toutes vos variables dans des colonnes - ce que vous mesurez, comme “poids” ou “température”.
- Placez chaque observation dans sa propre ligne.
- Ne combinez pas plusieurs informations dans une seule cellule. Parfois cela semble n’être qu’une seule information, mais demandez-vous si c’est la seule façon dont vous voulez utiliser ou trier ces données.
- Laissez les données brutes telles quelles - ne les modifiez pas !
- Exportez les données nettoyées dans un format texte tel que le format CSV (comma-separated values - valeurs séparées par des virgules). Cela garantit que n’importe qui peut utiliser les données et c’est requis par la plupart des référentiels de données.
Par exemple, nous disposons de données provenant de patients ayant visité plusieurs hôpitaux à Bruxelles, en Belgique. La date de la visite, l’hôpital, le sexe, le poids et le groupe sanguin des patients ont été enregistrés.
Si nous enregistrions les données comme ceci :
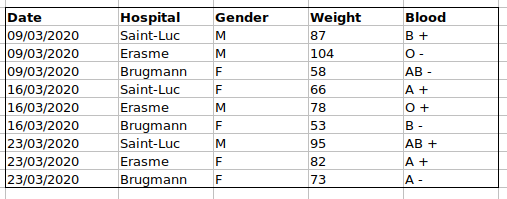
le problème est que les groupes sanguins ABO et le rhésus sont dans
la même colonne Blood. Donc, si on voulait examiner toutes
les observations du groupe A ou examiner les distributions de poids par
groupe ABO, il serait difficile de le faire en utilisant cette
configuration de données. Si à la place nous mettions les groupes ABO et
le rhésus dans des colonnes différentes, vous voyez que ce serait
beaucoup plus facile.
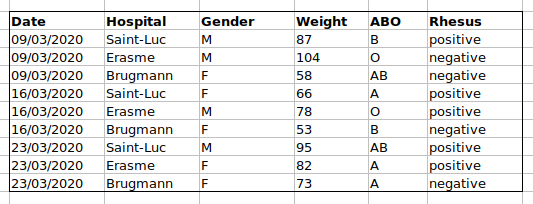
Une règle importante lors de la création d’une feuille de données est que les colonnes sont utilisées pour les variables et les lignes sont utilisées pour les observations :
- les colonnes sont des variables
- les lignes sont des observations
- les cellules sont des valeurs individuelles
Défi : Nous allons prendre un jeu de données désordonné et décrire comment nous allons le nettoyer.
Téléchargez un jeu de données désordonné en cliquant sur ici.
Ouvrez les données dans un tableur.
Vous pouvez voir qu’il y a deux onglets. Les données contiennent diverses variables cliniques enregistrées dans divers hôpitaux bruxellois lors des première et deuxième vagues du COVID-19 en 2020. Comme vous pouvez le constater, les données ont été enregistrées différemment lors des vagues de mars et novembre. Vous êtes désormais la personne en charge de ce projet et vous souhaitez pouvoir commencer à analyser les données.
Avec la personne à côté de vous, identifiez ce qui ne va pas avec cette feuille de calcul. Discutez également des étapes que vous devriez suivre pour nettoyer les onglets de la première et de la deuxième vague, et pour les rassembler tous dans une seule feuille de calcul.
Important : N’oubliez pas notre premier conseil : pour créer un nouveau fichier (ou onglet) pour les données nettoyées, ne modifiez jamais vos données (brutes) d’origine.
Après avoir effectué cet exercice, nous discuterons en groupe de ce qui n’allait pas avec ces données et de la manière dont vous pourriez y remédier.
Défi : Une fois que vous avez nettoyé les données, répondez aux questions suivantes :
- Combien d’hommes et de femmes ont participé à l’étude ?
- Combien de personnes des groupes A, AB et B ont été testés ?
- Idem, mais sans tenir compte des échantillons contaminés ?
- Combien de personnes des rhésus + et - ont été testés ?
- Combien de donneurs universels (O-) ont été testés ?
- Quel est le poids moyen des hommes AB ?
- Combien d’échantillons ont été testés dans les différents hôpitaux ?
Une excellente référence, en particulier en ce qui concerne les scripts R est l’article Tidy Data @Wickham:2014.
Erreurs courantes dans les feuilles de calcul
Questions
- Quels sont les problèmes courants liés au formatage des données dans les feuilles de calcul et comment pouvons-nous les éviter ?
Objectifs
- Reconnaître et résoudre les problèmes courants de formatage des feuilles de calcul.
Points clés
- Éviter d’utiliser plusieurs tableaux dans une même feuille de calcul.
- Éviter de répartir les données sur plusieurs onglets.
- Enregistrer les zéros comme des zéros.
- Utilisez une valeur vide appropriée pour enregistrer les données manquantes.
- N’utilisez pas de formatage pour transmettre des informations ou pour donner une jolie apparence à votre feuille de calcul.
- Placez les commentaires dans une colonne séparée.
- Enregistrez les unités dans les en-têtes de colonnes.
- Incluez une seule information dans une cellule.
- Évitez les espaces, les chiffres et les caractères spéciaux dans les en-têtes de colonnes.
- Évitez les caractères spéciaux dans vos données.
- Enregistrez les métadonnées dans un fichier texte brut séparé.
Il y a quelques erreurs potentielles à surveiller dans vos propres données ainsi que dans les données de vos collaborateurs ou d’Internet. Si vous êtes conscient des erreurs et de l’effet négatif possible sur l’analyse des données en aval et l’interprétation des résultats, cela pourrait vous motiver ainsi que les membres de votre projet à essayer de les éviter. Apporter de petits changements à la façon dont vous formatez vos données dans des feuilles de calcul peut avoir un grand impact sur l’efficacité et la fiabilité en matière de nettoyage et d’analyse des données.
- Utilisation de plusieurs tables
- Utilisation de plusieurs onglets
- Zéros non remplis
- Utilisation de valeurs vides problématiques
- Utilisation du formatage pour transmettre des informations
- Utilisation du formatage pour rendre la feuille de calcul jolie
- Commentaires ou unités dans des cellules
- Plusieurs informations dans une cellule
- Utilisation de noms de champs problématiques
- Utilisation de caractères spéciaux dans les données
- Inclusion de métadonnées dans le tableau de données
Utilisation de plusieurs tables
Une stratégie courante consiste à créer plusieurs tableaux de données dans une seule feuille de calcul . Cela perturbe l’ordinateur, alors ne faites pas ça ! Lorsque vous créez plusieurs tableaux dans une même feuille de calcul, vous établissez de fausses associations entre les éléments pour l’ordinateur, qui considère chaque ligne comme une observation. Vous utilisez également potentiellement le même nom de champ à plusieurs endroits, ce qui rendra plus difficile le nettoyage de vos données dans un format utilisable. L’exemple ci-dessous illustre ce problème :
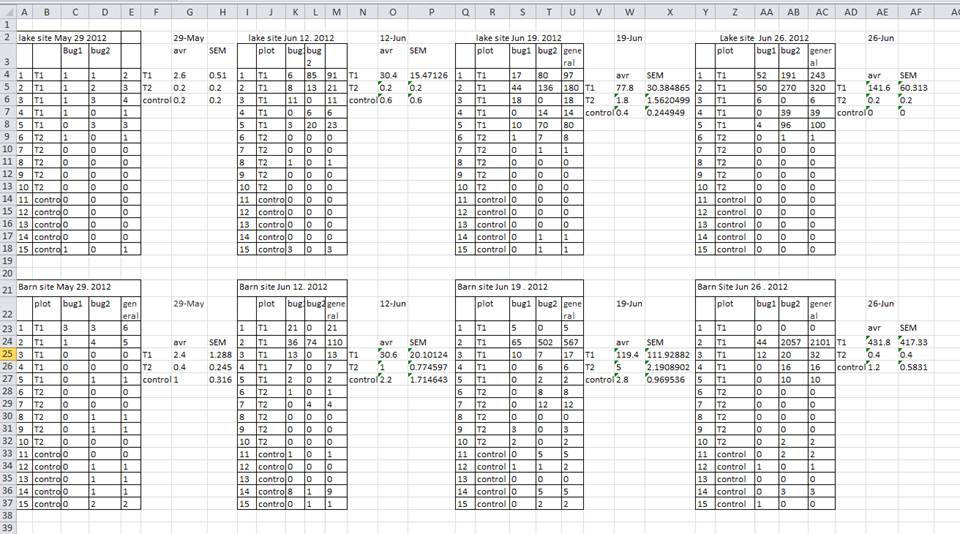
Dans l’exemple ci-dessus, l’ordinateur verra (par exemple) la ligne 4 et supposera que toutes les colonnes A-AF font référence au même échantillon. Cette ligne représente en fait quatre échantillons distincts (échantillon 1 pour chacune des quatre dates de collecte différentes - 29 mai, 12 juin, 19 juin et 26 juin), ainsi que quelques statistiques récapitulatives calculées (une moyenne (avr) et une erreur type de mesure (SEM)) pour deux de ces échantillons. D’autres lignes posent également problème.
Utilisation de plusieurs onglets
Mais qu’en est-il des onglets du classeur ? Cela semble être un moyen simple d’organiser les données, n’est-ce pas ? Eh bien, oui et non. Lorsque vous créez des onglets supplémentaires, vous ne permettez pas à l’ordinateur de voir les connexions dans les données qui s’y trouvent (vous devez introduire des fonctions spécifiques à l’application de feuille de calcul ou des scripts pour garantir cette connexion). Supposons, par exemple, que vous créiez un onglet séparé pour chaque jour où vous prenez une mesure.
Ce n’est pas une bonne pratique pour deux raisons :
vous êtes plus susceptible d’ajouter accidentellement des incohérences à vos données si à chaque fois que vous prenez une mesure, vous commencez à enregistrer les données dans un nouvel onglet, et
Même si vous parvenez à empêcher toute incohérence, vous vous ajoutez une étape supplémentaire avant même d’analyser les données car vous devrez combiner ces données en une seule table de données. Vous devrez indiquer explicitement à l’ordinateur comment combiner les onglets - et si les onglets ne sont pas formatés de manière cohérente, vous devrez peut-être même le faire manuellement.
La prochaine fois que vous saisirez des données et que vous créerez un autre onglet ou un autre tableau, demandez-vous si vous pourriez éviter d’ajouter cet onglet en ajoutant une autre colonne à votre feuille de calcul d’origine. Nous avons utilisé plusieurs onglets dans notre exemple de fichier de données désordonné, mais vous avez maintenant vu comment vous pouvez réorganiser vos données pour regrouper les onglets.
Votre feuille de calcul peut devenir très longue au cours de l’expérience. Cela rend plus difficile la saisie des données si vous ne voyez pas vos en-têtes en haut de la feuille de calcul mais ne répétez pas votre ligne d’en-tête. Ceux-ci peuvent facilement être mélangés aux données, entraînant des problèmes plus tard. À la place, vous pouvez geler les en-têtes de la colonne afin qu’ils restent visibles même lorsque vous disposez d’une feuille de calcul comportant beaucoup de lignes.
Zéros non remplis
Il se peut que lorsque vous mesurez quelque chose, il s’agisse généralement d’un zéro, par exemple le nombre de fois qu’un lapin est observé dans l’enquête. Pourquoi s’embêter à écrire le chiffre zéro dans cette colonne, alors qu’il s’agit majoritairement de zéros ?
Cependant, il existe une différence entre un zéro et une cellule vide dans une feuille de calcul. Pour l’ordinateur, un zéro est en réalité une donnée. Vous l’avez mesuré ou compté. Une cellule vide signifie qu’elle n’a pas été mesurée et l’ordinateur l’interprétera comme une valeur inconnue (également appelée valeur vide ou valeur manquante).
Les feuilles de calcul ou les programmes statistiques interpréteront probablement mal les cellules vides que vous envisagez d’être des zéros. En n’entrant pas la valeur de votre observation, vous dites à votre ordinateur de représenter ces données comme inconnues ou manquantes (vides). Cela peut entraîner des problèmes lors des calculs ou analyses ultérieurs. Par exemple, la moyenne d’un ensemble de nombres qui comprend une seule valeur vide est toujours vide (car l’ordinateur ne peut pas deviner la valeur des observations manquantes). À cause de cela, il est très important d’enregistrer les zéros comme des zéros et vraiment les données manquantes comme des valeurs vides.
Utilisation de valeurs vides problématiques
Exemple : utiliser -999 ou d’autres valeurs numériques (ou zéro) pour représenter les données manquantes.
Solutions:
Il existe plusieurs raisons pour lesquelles les valeurs vides sont représentées différemment dans un jeu de données. Parfois, des valeurs vides déroutantes sont automatiquement enregistrées à partir de l’appareil de mesure. Si tel est le cas, vous ne pouvez pas faire grand-chose, mais cela peut être résolu lors du nettoyage des données avec un outil comme OpenRefine avant l’analyse. D’autres fois, différentes valeurs vides sont utilisées pour transmettre différentes raisons pour lesquelles les données ne sont pas là. Il s’agit d’une information importante à capturer, mais elle utilise en fait une seule colonne pour capturer deux informations. Comme pour l’utilisation du formatage pour transmettre des informations, il serait bon de créer une nouvelle colonne comme “data_missing” et utiliser cette colonne pour capturer les différentes raisons.
Quelle que soit la raison, c’est un problème si des données inconnues ou manquantes sont enregistrées comme -999, 999 ou 0.
De nombreux programmes statistiques ne reconnaitront pas qu’ils sont censés représenter des valeurs manquantes. La façon dont ces valeurs sont interprétées dépendra du logiciel que vous utilisez pour analyser vos données. Il est essentiel d’utiliser un indicateur clairement défini et cohérent pour les valeurs vides.
Les blancs (pour la plupart des applications) et NA (pour R) sont de bons choix. @White : 2013 explique les bons choix pour indiquer des valeurs vides pour différentes applications logicielles dans leur article :
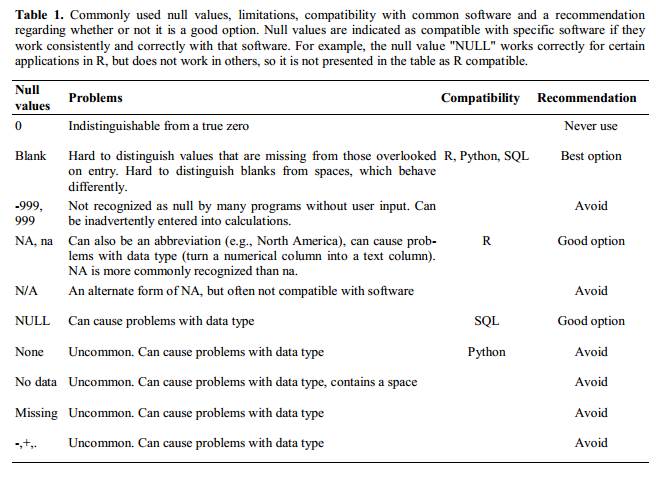
Utilisation du formatage pour transmettre des informations
Exemple : mise en évidence des cellules, des lignes ou des colonnes qui doivent être exclues d’une analyse, en laissant des lignes vides pour indiquer séparations dans les données.
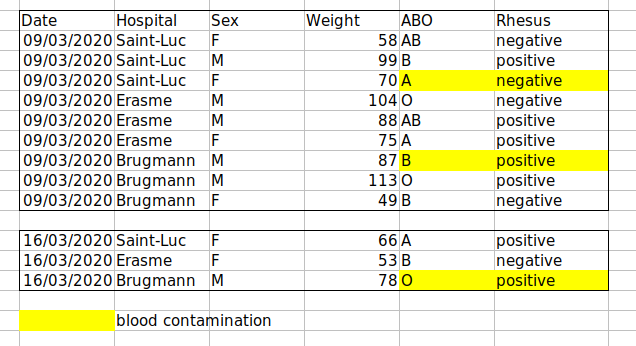
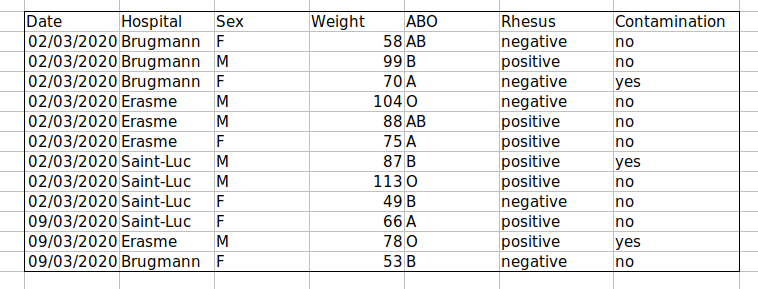
Solution : créer un nouveau champ pour coder les données qui doivent être exclues.
Utilisation du formatage pour rendre la feuille de calcul jolie {#formatting_pretty}
Exemple : fusion de cellules.
Solution : Si vous ne faites pas attention, le formatage d’une feuille de calcul pour qu’elle soit plus esthétique peut compromettre la capacité de votre ordinateur à voir les associations dans les données. Les cellules fusionnées rendront vos données illisibles par les logiciels de statistiques. Pensez à restructurer vos données de telle manière que vous n’aurez pas besoin de fusionner des cellules pour organiser vos données.
Commentaires ou unités dans des cellules
La plupart des logiciels d’analyse ne peuvent pas voir les commentaires Excel ou LibreOffice, et serait embrouillé par les commentaires placés dans vos cellules de données. Comme décrit ci-dessus pour le formatage, créez un autre champ si vous devez ajouter des notes aux cellules. De même, n’incluez pas d’unités dans les cellules : idéalement, toutes les mesures que vous placez dans une colonne devraient être dans la même unité , mais si pour une raison quelconque ce n’est pas le cas, créez un autre champ et spécifient les unités dans lesquelles se trouve la cellule.
Plusieurs informations dans une cellule
Exemple : Enregistrement des groupes sanguins ABO et rhésus dans une seule cellule, tels que A+, B+, A-, …
Solution : N’incluez pas plus d’une information dans une cellule . Cela limitera les façons dont vous pourrez analyser vos données. Si vous avez besoin de ces deux mesures, concevez votre feuille de calcul pour inclure ces informations. Par exemple, incluez une colonne pour le groupe ABO et une pour le rhésus.
Utilisation de noms de champs problématiques {#field_name}
Choisissez des noms de champs descriptifs, mais veillez à ne pas inclure d’espaces, de chiffres ou de caractères spéciaux de quelque nature que ce soit. Les espaces peuvent être mal interprétés par les parseurs qui utilisent des espaces comme délimiteurs et certains programmes n’aiment pas les noms de champs qui sont des chaînes de caractères commençant par nombres.
Les tirets bas (_) sont une bonne alternative aux
espaces. Pensez à écrire les noms en camel case (comme ceci :
SampleFileName) pour améliorer la lisibilité de. N’oubliez pas que les
abréviations qui ont un sens pour le moment ne seront peut-être pas si
évidentes dans 6 mois, mais n’en faites pas trop avec des noms qui sont
excessivement longs. L’inclusion des unités dans les noms de champs
évite toute confusion et permet aux autres d’interpréter facilement vos
champs.
Exemples
| Bon Nom | Bonne Alternative | Éviter |
|---|---|---|
| Max_temp_C | MaxTemp | Temp Maximale (°C) |
| Precipitations_mm | Precipitation | precmm |
| Croissance_annuelle_moyenne | CroissanceAnnuelleMoyenne | Croissance moyenne/an |
| sexe | sexe | H/F |
| poids | poids | w. |
| type_cellulaire | TypeCellulaire | Type cellulaire |
| Observation_01 | premiere_observation | 1er Obs. |
Utilisation de caractères spéciaux dans les données
Exemple : Vous traitez votre tableur comme un traitement de texte lorsque vous rédigez des notes, par exemple en copiant des données directement depuis Word ou d’autres applications.
Solution : Il s’agit d’une stratégie courante. Par exemple, lorsqu’ils écrivent un texte plus long dans une cellule, les utilisateurs incluent souvent des sauts de ligne, des tirets cadratins, etc. dans leur feuille de calcul. De même, lors de la copie de données à partir d’applications telles que Word, le formatage et les caractères non standard (tels que les guillemets alignés à gauche et à droite et les accents) sont inclus. Lors de l’exportation de ces données dans un environnement de codage/statistique ou dans une base de données relationnelle, des choses dangereuses peuvent se produire, comme des lignes coupées en deux et des erreurs d’encodage générées.
La meilleure pratique consiste à éviter d’ajouter des caractères tels que des nouvelles lignes, des tabulations et des accents. En d’autres termes, traitez une cellule de texte comme s’il s’agissait d’un simple formulaire web qui ne peut contenir que du texte et des espaces.
Inclusion de métadonnées dans le tableau de données
Exemple : Vous ajoutez une légende en haut ou en bas de votre tableau de données expliquant la signification des colonnes, les unités, les exceptions, etc.
Solution : L’enregistrement des données sur vos données (“métadonnées”) est essentiel. Il se peut que vous connaissiez parfaitement votre jeu de données pendant que vous les collectez et les analysez, mais il y a peu de chances que vous vous souveniez encore que la variable “sglmemgp” signifie membre unique d’un groupe, par exemple, ou de l’algorithme exact que vous avez utilisé pour transformer une variable ou en créer une dérivée, après quelques mois, un an ou plus.
De plus, il existe de nombreuses raisons pour lesquelles d’autres personnes pourraient vouloir examiner ou utiliser vos données : pour comprendre vos conclusions, pour vérifier vos conclusions, pour examiner la publication que vous avez soumise, pour reproduire vos résultats, pour concevoir une étude similaire, ou même archiver vos données pour y accéder et réutiliser par d’autres. Bien que les données numériques soient par définition lisibles par machine, comprendre leur signification est un travail pour les êtres humains. L’importance de documenter vos données pendant la phase de collecte et d’analyse de votre recherche ne doit pas être sous-estimée, surtout si votre recherche doit faire partie du dossier scientifique.
Cependant, les métadonnées ne doivent pas être contenues dans le fichier de données lui-même. Contrairement à un tableau dans un article ou un fichier supplémentaire, les métadonnées (sous forme de légendes) ne doivent pas être incluses dans un fichier de données puisque ces informations ne sont pas des données, et leur inclusion peut perturber la façon dont les programmes informatiques interprètent votre fichier de données. Les métadonnées doivent plutôt être stockées dans un fichier distinct dans le même dossier que votre fichier de données, de préférence au format texte brut avec un nom qui l’associe clairement à votre fichier de données. Parce que les fichiers de métadonnées sont au format texte libre, ils vous permettent également d’encoder des commentaires, des unités, des informations sur la façon dont les valeurs vides sont encodées, etc. qui sont importants pour documenter vos données, mais peuvent perturber le formatage de votre fichier de données.
De plus, les métadonnées au niveau d’un fichier ou de la base de données décrivent comment les fichiers qui constituent le jeu de données sont liés les uns aux autres ; dans quel format ils se trouvent ; et s’ils remplacent ou sont remplacés par les fichiers précédents. Un fichier readme.txt au niveau du dossier est la manière classique de répertorier tous les fichiers et dossiers d’un projet.
(Texte sur les métadonnées adapté du cours en ligne Research Data MANTRA par EDINA et Data Library, Université d’Édimbourg. MANTRA est sous licence Creative Commons Attribution 4.0 International Licence.)
Exporter des données
Question
- Comment pouvons-nous exporter des données à partir de feuilles de calcul d’une manière utile pour les applications en aval ?
Objectifs
- Stocker les données des feuilles de calcul dans des formats de fichiers universels.
- Exporter les données d’une feuille de calcul vers un fichier CSV.
Points clés
Les données stockées dans des formats de feuilles de calcul courants ne seront souvent pas lues correctement dans un logiciel d’analyse de données, introduisant des erreurs dans vos données.
L’exportation de données à partir de feuilles de calcul vers des formats tels que CSV ou TSV les met dans un format qui peut être utilisé de manière cohérente par la plupart des programmes.
Le stockage des données avec lesquelles vous allez travailler pour
vos analyses dans le format de fichier Excel par défaut
(*.xls ou *.xlsx - selon la version d’Excel )
n’est pas une bonne idée. Pourquoi ?
Parce qu’il s’agit d’un format propriétaire, et qu’il est possible que dans le futur, la technologie n’existera pas (ou devienne suffisamment rare) pour rendre l’ouverture du fichier peu pratique, voire impossible.
D’autres logiciels de tableur peuvent ne pas être en mesure d’ouvrir les fichiers enregistrés dans un format Excel propriétaire.
Différentes versions d’Excel peuvent gérer les données différemment, entraînant des incohérences. Les dates sont un exemple bien documenté d’incohérences dans le stockage de données.
Enfin, de plus en plus de revues et d’organismes de financement vous demandent de déposer vos données dans un dépôt de données, et la plupart d’entre eux n’acceptent pas le format Excel. Les données doivent être dans l’un des formats discutés ci-dessous.
Les points ci-dessus s’appliquent également à d’autres formats tels que les formats open data utilisés par LibreOffice/Open Office. Ces formats ne sont pas statiques et ne sont pas analysés de la même manière par différents logiciels.
Le stockage des données dans un format universel, ouvert et statique aidera à résoudre ce problème. Essayez les valeurs délimitées par des tabulations (tab separated values ou TSV) ou délimitées par des virgules (comma separated values ou CSV). Les fichiers CSV sont des fichiers texte simples où les colonnes sont séparées par des virgules, d’où “comma separated values” ou CSV. L’avantage d’un fichier CSV par rapport à un Excel/SPSS/etc. est que nous pouvons ouvrir et lire un fichier CSV en utilisant à peu près n’importe quel logiciel, y compris des éditeurs de texte brut comme TextEdit ou NotePad. Les données d’un fichier CSV peuvent également être facilement importées dans d’autres formats et environnements, tels que SQLite et R. Nous ne sommes pas limités à une certaine version d’un certain programme coûteux lorsque nous travaillons avec des fichiers CSV, c’est donc un bon format avec lequel travailler pour une interopérabilité et une durabilité maximale. La plupart des tableurs peuvent facilement enregistrer au format texte délimité comme CSV, bien qu’ils puissent vous avertir lors de l’exportation du fichier.
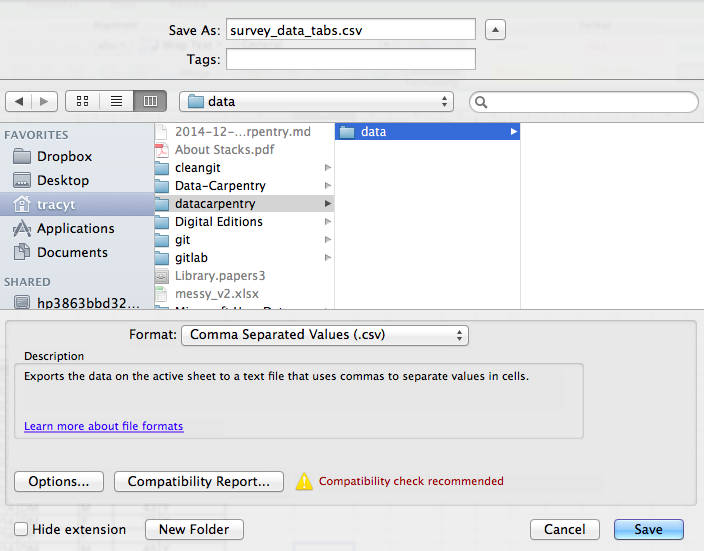
Pour enregistrer un fichier que vous avez ouvert dans Excel au format CSV :
- Dans le menu supérieur, sélectionnez “Fichier” et “Enregistrer sous”.
- Dans le champ “Format”, dans la liste, sélectionnez “délimité par
des virgules” (
*.csv). - Vérifiez le nom du fichier et l’emplacement où vous souhaitez l’enregistrer et cliquez sur “Enregistrer”.
Une remarque importante pour la rétrocompatibilité : vous pouvez ouvrir les fichiers CSV dans Excel !
Une note sur R et xls : Il existe des
packages R qui peuvent lire les fichiers xls (ainsi que les
feuilles de calcul Google). Il est même possible d’accéder à différentes
feuilles de calcul des documents xls.
Mais
- certains d’entre eux ne fonctionnent que sous Windows.
- cela équivaut à remplacer une exportation (simple mais manuelle)
vers
csvpar une complexité/dépendance supplémentaire dans le code R d’analyse des données. - les meilleures pratiques en matière de formatage des données s’appliquent toujours.
- Y a-t-il vraiment une bonne raison pour laquelle
csv(ou un format similaire) n’est pas adéquat ?
Mises en garde concernant les virgules
Dans certains jeux de données, les valeurs des données elles-mêmes peuvent inclure des virgules (,). Dans ce cas, le logiciel que vous utilisez (y compris Excel) affichera très probablement de manière incorrecte les données en colonnes. En effet, les virgules qui font partie des valeurs de données seront interprétées comme des délimiteurs.
Par exemple, nos données pourraient ressembler à ceci :
species_id,genus,species,taxa
AB,Amphispiza,bilineata,Bird
AH,Ammospermophilus,harrisi,Rodent, not censused
AS,Ammodramus,savannarum,Bird
BA,Baiomys,taylori,RodentDans l’enregistrement “AH, Ammospermophilus, harrisi, Rodent, not censused”, la valeur pour « taxons » comprend une virgule (“Rodent, not censused”). Si nous essayons de lire ce qui précède dans Excel (ou un autre tableur), nous obtiendrons quelque chose comme ceci :
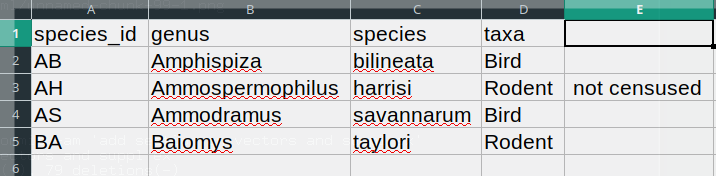
La valeur de « taxons » a été divisée en deux colonnes (au lieu d’être placée dans une seule colonne “D”). Cela peut se propager à un certain nombre d’autres erreurs. Par exemple, la colonne supplémentaire sera interprétée comme une colonne avec de nombreuses valeurs manquantes (et sans en-tête approprié). En plus de cela, la valeur dans la colonne “D” pour l’enregistrement de la ligne 3 (donc celle où la valeur de “taxons” contenait la virgule) est désormais incorrecte.
Si vous souhaitez stocker vos données au format csv et
vous attendez à ce que vos valeurs de données contiennent des virgules,
vous pouvez éviter le problème évoqué ci-dessus en mettant les valeurs
entre guillemets (““). En appliquant cette règle, nos données pourraient
ressembler à ceci :
species_id,genus,species,taxa
"AB","Amphispiza","bilineata","Bird"
"AH","Ammospermophilus","harrisi","Rodent, not censused"
"AS","Ammodramus","savannarum","Bird"
"BA","Baiomys","taylori","Rodent"Désormais, l’ouverture de ce fichier en tant que “csv” dans Excel n’entraînera pas une colonne supplémentaire, car Excel n’utilisera que des virgules qui se trouvent en dehors des guillemets comme caractères de délimitation.
Alternativement, si vous travaillez avec des données contenant des virgules, vous devrez probablement utiliser un autre délimiteur lorsque vous travaillerez dans une feuille de calcul 1. Dans ce cas, pensez à utiliser des tabulations comme délimiteur et à travailler avec des fichiers TSV. Les fichiers TSV peuvent être exportés à partir de feuilles de calcul de la même manière que les fichiers CSV.
Si vous travaillez avec un jeu de données déjà existant dans lequel les valeurs de données ne sont pas incluses entre “” mais qui ont à la fois des virgules comme délimiteurs et faisant partie de valeurs de données, vous êtes potentiellement confronté à un problème majeur avec le nettoyage des données. Si le jeu de données que vous traitez contient des centaines ou des milliers d’enregistrements, les nettoyer manuellement (soit en supprimant les virgules des valeurs de données, soit en mettant les valeurs entre guillemets - ““) non seulement va prendre des heures et des heures, mais peut finir par vous amener à introduire accidentellement de nombreuses erreurs.
Le nettoyage des jeux de données est l’un des problèmes majeurs dans de nombreuses disciplines scientifiques. L’approche dépend presque toujours du contexte particulier. Cependant, il est recommandé de nettoyer les données de manière automatisée, par exemple en écrivant et en exécutant un script. Des leçons Python et R vous donneront les bases pour développer des compétences permettant de créer des scripts pertinents.
Résumé

Un workflow typique d’analyse de données est illustré dans la figure ci-dessus, où les données sont transformées, visualisées et modélisées à plusieurs reprises. Cette itération est répétée plusieurs fois jusqu’à ce que les données soient comprises. Cependant, dans de nombreux cas réels, la majorité du temps est consacré au nettoyage et à la préparation des données, plutôt qu’à leur analyse et à leur compréhension.
Un workflow d’analyse de données agile, avec plusieurs itérations rapides du cycle transformation/visualisation/modèle, n’est possible que si les données sont formatées de manière prévisible et que l’on peut raisonner sur les données sans avoir à les regarder et/ou à les corriger.
Key Points
- Une bonne organisation des données est la base de tout projet de recherche.
Ceci est particulièrement pertinent dans les pays européens où la virgule est utilisée comme séparateur décimal. Dans de tels cas, le séparateur de valeurs par défaut dans un fichier csv sera le point-virgule (;), ou les valeurs seront systématiquement entre guillemets.↩︎
Content from R et RStudio
Last updated on 2025-05-05 | Edit this page
Estimated time: 30 minutes
Overview
Questions
- Que sont R et RStudio ?
Objectives
- Décrire le principe des scripts RStudio, de la console, de l’environnement et des panneaux de visualisation.
- Organiser les fichiers et les répertoires d’une même série d’analyses en projet R et comprendre le but du répertoire de travail.
- Utiliser l’interface d’aide intégrée de RStudio pour rechercher des informations sur les fonctions R.
- Montrer comment fournir suffisamment d’informations pour faciliter le dépannage par la communauté des utilisateurs R.
Cet épisode est basé sur la leçon Data Analysis and Visualisation in R for Ecologists de Data Carpentries.
Qu’est-ce que R ? Qu’est-ce que RStudio ?
Le terme R est utilisé pour désigner le langage de programmation, l’environnement de calcul statistique et le logiciel qui interprète les scripts écrits à l’aide de celui-ci.
RStudio est fréquemment utilisé pour écrire des scripts R et pour interagir avec le logiciel R 1. R doit être préalablement installé sur votre ordinateur pour que RStudio puisse fonctionner correctement.
La RStudio IDE Cheat Sheet fournit davantage d’informations que ce qui sera couvert dans cet épisode et peut être utile pour apprendre les raccourcis clavier et découvrir de nouvelles fonctionnalités.
Pourquoi apprendre R ?
R utilise peu de “clic-bouton”, ce qui est une bonne chose
La courbe d’apprentissage en R est probablement plus complexe qu’avec un autre logiciel. Par contre, les résultats des analyses effectuées ne découleront pas d’une succession de commandes en clic-bouton (que l’on risque d’oublier) mais d’une série de commandes écrites. L’énorme avantage est que si vous souhaitez refaire votre analyse parce que vous avez par exemple collecté davantage de données, vous n’aurez pas besoin de vous rappeler sur quel bouton vous avez cliqué, ni dans quel ordre, pour obtenir vos résultats ; il vous suffira de re-exécuter votre script.
Travailler avec des scripts clarifie les étapes utilisées dans vos analyses, et le code que vous écrivez peut être relu par quelqu’un d’autre qui pourrait le commenter et repérer les erreurs.
Travailler avec des scripts vous force à bien comprendre ce que vous faites. Vous aurez ainsi une meilleure compréhension des méthodes que vous utilisez.
Le code R est idéal pour la reproductibilité
La reproductibilité signifie que quelqu’un d’autre (ou vous-même!) peut obtenir les mêmes résultats à partir du même jeu de données en utilisant le même code.
R s’intègre à d’autres outils pour générer des manuscrits ou des rapports à partir de votre code. Si vous collectez davantage de données ou si vous corrigez une erreur dans votre jeu de données, les chiffres et les tests statistiques de votre rapport sont mis à jour automatiquement.
De plus en plus de revues scientifiques et d’agences de financement exigent que les analyses soient reproductibles. Savoir utiliser R sera donc un avantage.
R est interdisciplinaire et extensible
Plus de 10 000 packages 2 (paquets) peuvent être installés pour étendre les capacités de R. Les approches statistiques de nombreuses disciplines scientifiques peuvent donc être combinées, ce qui permet d’optimiser le cadre analytique nécessaire à l’analyse de vos données. Par exemple, R propose des packages pour l’analyse d’images, de données géographiques, de séries chronologiques, pour l’analyse de génétique de population et bien plus encore.
, the Comprehensive R Archive Network. From the R Journal, Volume 10/2, December 2018.](../fig/cran.png)
R fonctionne quel que soit la forme et la taille des données
R fonctionne aussi bien sur des petits que sur des gros jeux de données (pouvant contenir des millions de lignes).
R est conçu pour l’analyse des données. Ce langage utilise des structures de données particulières ainsi que certains types de données qui facilitent la gestion des données, comme les données manquantes ou les variables catégorielles .
R peut se connecter à des feuilles de calcul, à des bases de données et à de nombreux autres formats de données, sur votre ordinateur ou sur le Web.
R génère des graphiques de haute qualité
Les fonctionnalités graphiques de R sont étendues. Elles permettent d’ajuster n’importe quel aspect d’une figure pour transmettre efficacement le message des données.
La communauté R est grande et accueillante
Des milliers de personnes utilisent R quotidiennement. Beaucoup d’entre elles sont prêtes à vous aider via des listes de diffusion et des sites Web tels que Stack Overflow, ou sur le . Ces larges communautés d’utilisateurs recouvrent des domaines spécialisés tels que la bioinformatique. Un des sous-ensembles de la communauté R est Bioconductor, un projet scientifique pour l’analyse et la compréhension de données biologiques . Cet atelier a d’ailleurs été développé par des membres de la communauté Bioconductor ; pour plus d’informations, veuillez consulter l’atelier complémentaire “The Bioconductor Project”.
R est non seulement gratuit, mais également open source et multiplateforme
N’importe qui peut inspecter le code source pour voir comment R fonctionne. Grâce à cette transparence, il y a moins de risques d’erreurs, et si vous (ou quelqu’un d’autre) en trouvez, vous pouvez signaler et corriger des bugs.
RStudio
Commençons par découvrir RStudio, qui est un environnement de développement intégré (IDE) permettant de travailler avec R.
Le produit open source RStudio IDE est gratuit sous la license . L’IDE RStudio est également disponible avec une licence commerciale et une assistance prioritaire par courrier électronique de Posit, Inc.
Nous utiliserons l’IDE RStudio pour écrire du code, parcourir les fichiers sur notre ordinateur, inspecter les variables que nous allons créer et visualiser les graphiques que nous allons générer. RStudio peut également être utilisé pour d’autres choses (par exemple, le contrôle de version, le développement de packages, l’écriture d’applications Shiny) que nous n’aurons pas l’occasion d’aborder pendant cet atelier.
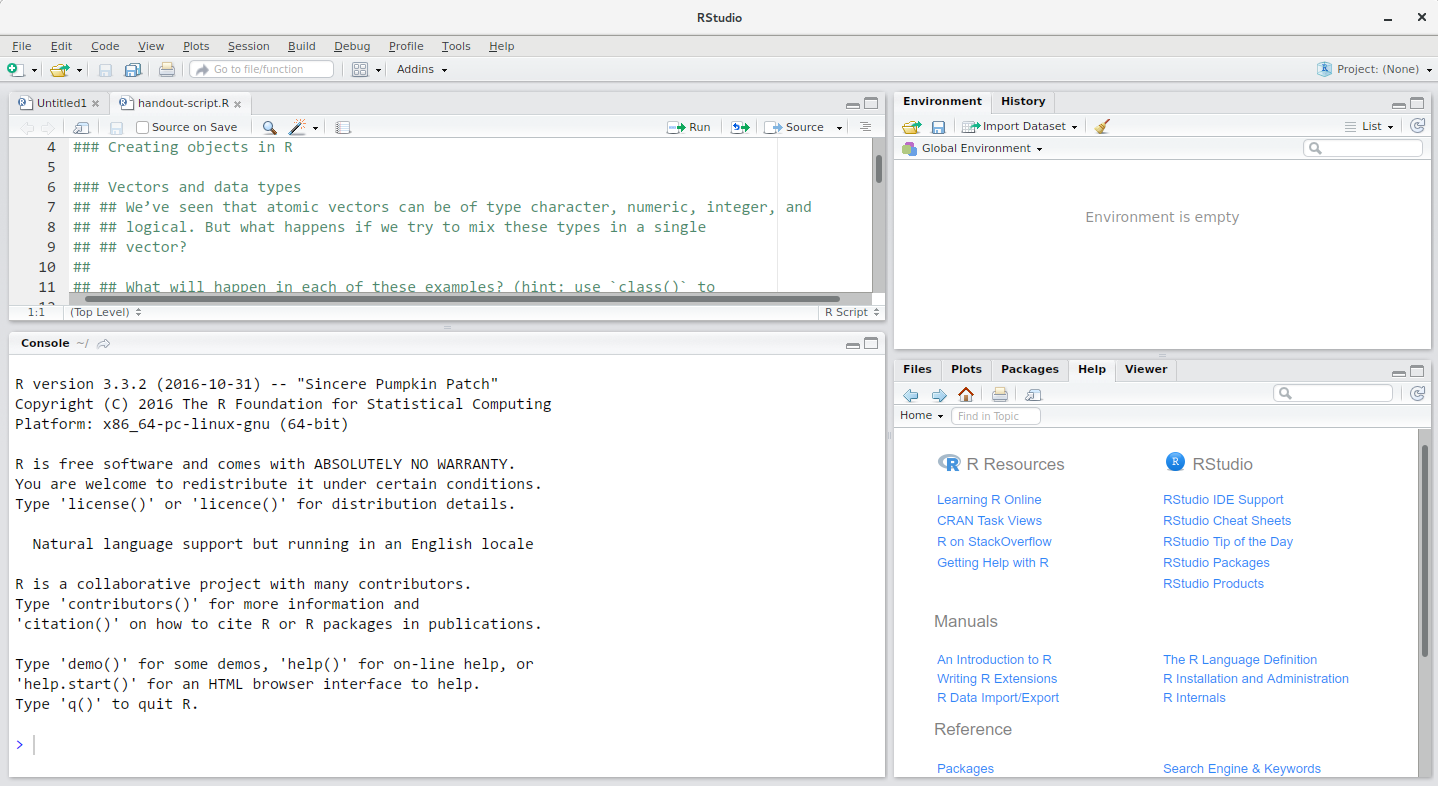
La fenêtre RStudio est divisée en 4 “Volets” :
- la Source de vos scripts et documents (en haut à gauche, dans la mise en page par défaut )
- votre Environnement/Historique (en haut à droite),
- vos Fichiers/Graphiques/Packages/Aide/Visionneuse (en bas à droite), et
- la R Console (en bas à gauche).
L’emplacement de ces volets et leur contenu peuvent être
personnalisés (voir le menu ,
Outils -> Options globales -> Disposition des volets).
L’un des avantages de l’utilisation de RStudio est que toutes les informations dont vous avez besoin pour écrire du code sont disponibles dans la même fenêtre. De plus, avec de nombreux raccourcis, avec les couleurs associées aux différents types de variables, et grâce à la complétion automatique RStudio facilite l’écriture de code et le rend moins sujet aux erreurs.
Mise en place
Il est recommandé de conserver l’ensemble des données, d’analyses et de textes relatifs à un même projet dans un seul et même dossier, appelé répertoire de travail. Tous les scripts de ce dossier peuvent alors utiliser des chemins relatifs qui indiquent où se trouvent les différents fichiers dans le projet (par opposition aux chemins absolus, qui pointent vers l’endroit où se trouvent les fichiers sur un ordinateur spécifique). Travailler de cette façon permet de pouvoir facilement déplacer le projet sur votre ordinateur ou de le partager avec d’autres, sans vous soucier de savoir si les scripts sous-jacents fonctionneront toujours.
RStudio fournit un ensemble d’outils via son interface “Projets”, qui non seulement crée un répertoire de travail pour vous, mais mémorise également son emplacement (vous permettant d’y accéder rapidement). Ceci permet aussi d’éventuellement conserver les paramètres personnalisés et les fichiers ouverts pour faciliter la reprise du travail après une pause. Suivez les étapes de création d’un “Projet R” pour ce tutoriel ci-dessous.
- Démarrez RStudio.
- Dans le menu « Fichier », cliquez sur « Nouveau projet ». Choisissez
Nouveau répertoire, puisNouveau projet. - Entrez un nom pour ce nouveau dossier (ou “répertoire”) et
choisissez un emplacement pratique pour celui-ci. Ce sera votre
répertoire de travail pour cette session (ou tout le
cours) (par exemple,
bioc-intro). - Cliquez sur « Créer un projet ».
- (Facultatif) Définissez les préférences sur « Jamais » pour enregistrer l’espace de travail dans RStudio.
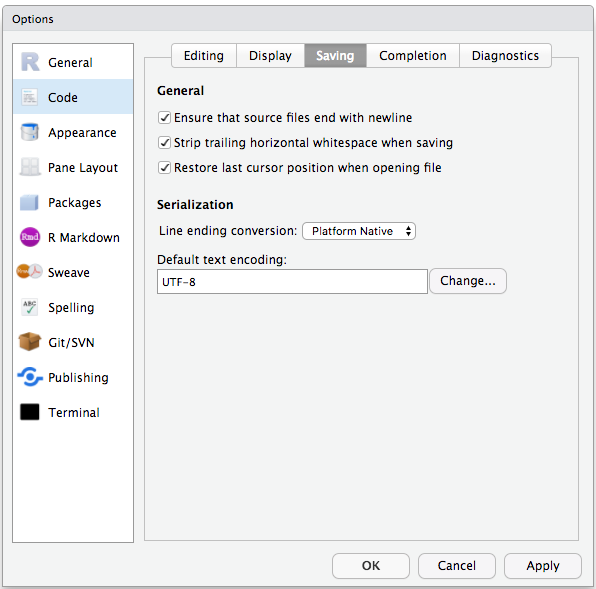
Les préférences par défaut de RStudio fonctionnent généralement bien, mais il vaut mieux éviter d’enregistrer l’espace de travail dans .RData, surtout si vous travaillez avec des jeux de données volumineux. Pour désactiver cela, allez dans Outils –> « Options globales » et sélectionnez l’option « Jamais » pour « Enregistrer l’espace de travail dans .RData » à la sortie.

Pour éviter les problèmes d’encodage des caractères entre Windows et d’autres systèmes d’exploitation, nous allons utiliser UTF-8 par défaut :
Organiser votre répertoire de travail
L’utilisation d’une structure de dossiers cohérente pour vos différents projets vous aidera à être organisés et facilitera également la recherche/le classement des éléments à l’avenir. Ce peut être particulièrement utile lorsque vous avez plusieurs projets. En général, vous pouvez créer des répertoires (dossiers) pour les scripts, données et documents.
-
data/Utilisez ce dossier pour stocker vos données brutes et les données intermédiaires que vous pourriez avoir besoin de créer lors d’une analyse particulière. Par souci de transparence et pour pouvoir retracer l’origine et la provenance des données, vous devez toujours conserver une copie (accessible) des données brutes et effectuer le nettoyage et le prétraitement de vos données autant que possible par programmation (c’est-à-dire avec scripts, plutôt que manuellement) . Séparer les données brutes des données traitées est également une bonne idée. Par exemple, vous pourriez vouloir conserver les fichiersdata/raw/tree_survey.plot1.txtet...plot2.txtdans un dossier séparé d’un fichierdata/processed/tree.survey.csvqui est, lui, un fichier processé qui a été généré par le scriptscripts/01.preprocess.tree_survey.R. -
documents/serait typiquement l’endroit où conserver les plans, les brouillons, ou d’autre types de textes. -
scripts/(ousrc) serait l’emplacement où sauvegarder les scripts correspondant différentes analyses ou visualisations, et potentiellement un dossier séparé pour vos fonctions (nous y reviendrons plus tard).
Ces dossiers devraient être la structure de base de votre répertoire de travail, auquel vous souhaiterez peut-être ajouter des répertoires ou sous-répertoires supplémentaires en fonction des besoins de votre projet. .
Pour ce cours, nous aurons besoin d’un dossier data/
pour stocker nos données brutes, nous utiliserons un dossier
data_output/ lorsque nous exporterons des données sous
forme de fichiers CSV et nous créerons un dossier
fig_output/ pour y mettre les figures que nous allons
enregistrer.
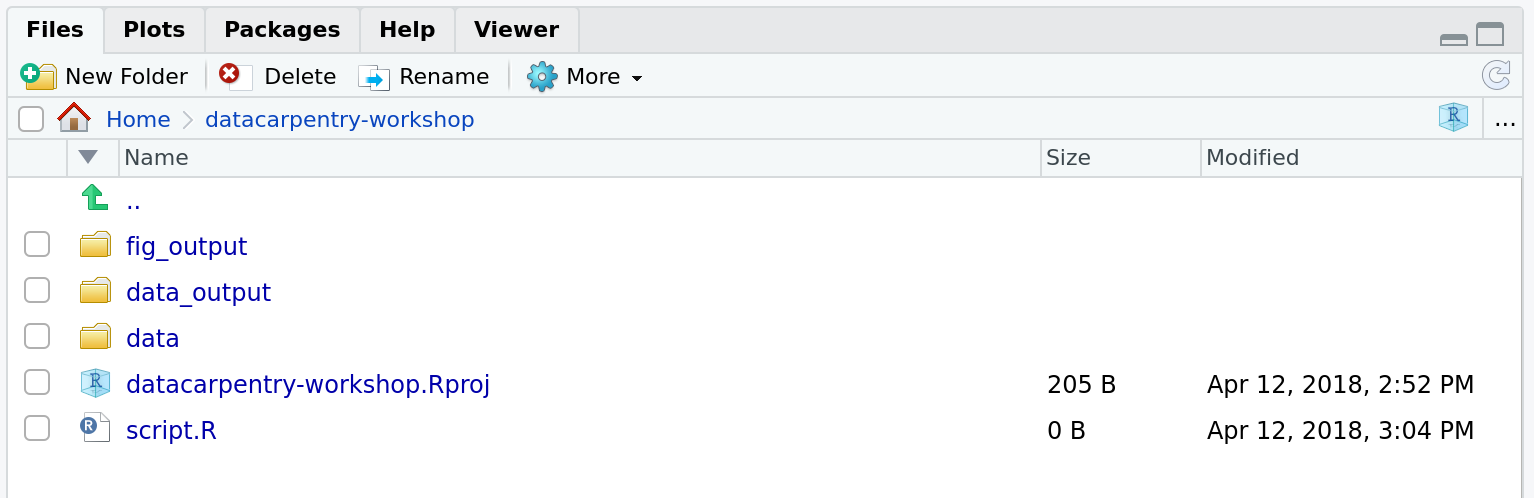
Défi : créer la structure de répertoires de votre projet
Sous l’onglet “Fichiers” à droite de l’écran, cliquez sur “Nouveau
dossier” et créez un dossier nommé “data” dans votre répertoire de
travail nouvellement créé (par exemple, “~/bioc-intro/data”). Vous
pouvez également taper dir.create("data") sur votre console
R. Répétez ces opérations pour créer un dossier
data_output/ et un fig_output.
Nous allons conserver le script à la racine de notre répertoire de travail car nous n’allons utiliser qu’un seul fichier et cela facilitera les choses.
Votre répertoire de travail devrait maintenant ressembler à ceci :
La gestion de projet s’applique évidemment aussi aux projets de bioinformatique 3. William Noble (@Noble:2009) propose la structure de répertoires suivante :
Les noms de répertoires sont en gros caractères et les noms de fichiers sont en caractères plus petits . Seul un sous-ensemble des fichiers est affiché ici. Notez que les dates sont formatées en
<Année>-<mois>-<jour>afin qu’elles puissent être triées par ordre chronologique. Le code sourcesrc/ms-analysis.cest compilé pour créerbin/ms-analysiset est documenté dansdoc/ms-analysis.html. Les fichiersREADMEdans les répertoires de données précisent qui a téléchargé les données, à partir de quelle URL, et à quelle date . Le scriptresults/2009-01-15/runallgénère automatiquement les trois sous-répertoires split1, split2 et split3, correspondant à des validation croisées de 3 sous-ensembles. Le scriptbin/parse-sqt.pyest appelé par le scriptrunall.
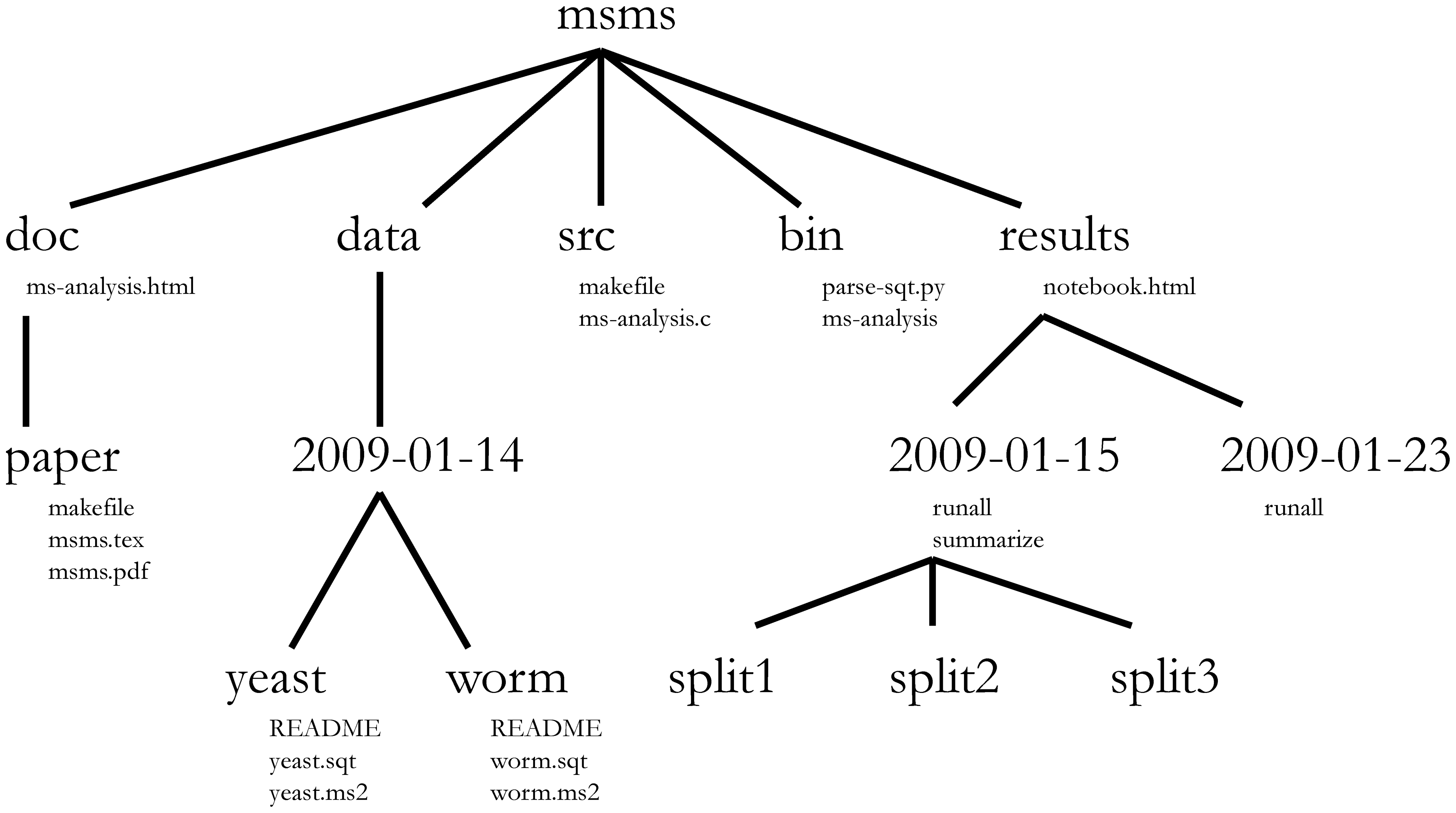
Un répertoire de projet bien défini et bien documenté doit permettre à quelqu’un qui n’est pas familier avec le projet 4 de :
comprendre en quoi consiste le projet, quelles données sont disponibles, quelles analyses ont été effectuées et quels résultats ont été produits
et surtout de répéter l’analyse à nouveau - avec de nouvelles données ou en modifiant certains paramètres d’analyse .
Le répertoire de travail
Le répertoire de travail est un concept important à comprendre. C’est l’endroit à partir duquel R recherchera et enregistrera les fichiers. Lorsque vous écrivez du code pour votre projet, il doit faire référence à des fichiers en relation avec la racine de votre répertoire de travail et n’a besoin que de fichiers au sein de cette structure .
L’utilisation de projets RStudio facilite cela et garantit que votre
répertoire de travail est correctement défini. Si vous avez besoin de le
vérifier, vous pouvez utiliser getwd(). Si par hasard votre
répertoire de travail n’est pas celui qu’il devrait être, vous pouvez le
changer dans RStudio en y accédant via le navigateur de fichiers, puis
en cliquant sur l’icône representant un engrenage bleu, et sélectionner
Définir comme répertoire de travail. Vous pouvez également
utiliser setwd("/path/to/working/directory") pour
réinitialiser votre répertoire de travail. Cependant, vos scripts ne
doivent pas inclure cette ligne car elle échouera sur l’ordinateur de
quelqu’un d’autre.
Exemple
Le schéma ci-dessous représente le répertoire de travail
bioc-intro avec les sous-répertoires data et
fig_output, et 2 fichiers dans ce dernier :
bioc-intro/data/
/fig_output/fig1.pdf
/fig_output/fig2.pngSi on était dans le répertoire de travail, on pourrait faire
référence au fichier fig1.pdf en utilisant le chemin
relatif bioc-intro/fig_output/fig1.pdf ou le chemin absolu
/home/user/bioc-intro/fig_output/fig1.pdf.
Si nous étions dans le répertoire data, nous
utiliserions le chemin relatif ../fig_output/fig1.pdf ou le
même chemin absolu
/home/user/bioc-intro /fig_output/fig1.pdf.
Interagir avec R
La base de la programmation est que nous écrivons les instructions que l’ordinateur doit faire, puis nous demandons à l’ordinateur de les suivre . Nous écrivons, ou codons, des instructions dans R car c’est un langage commun que l’ordinateur et nous pouvons comprendre. Nous appelons les instructions commandes et nous demandons à l’ordinateur de les suivre en exécutant (ou en runnant) ces commandes.
Il existe deux manières principales d’interagir avec R : en utilisant la console ou en utilisant des scripts (fichiers texte brut contenant votre code). Le volet de la console (dans RStudio, le panneau inférieur gauche) est l’endroit où les commandes écrites en langage R peuvent être saisies et exécutées immédiatement par l’ordinateur. C’est également là que les résultats seront affichés pour les commandes exécutées. Vous pouvez taper des commandes directement dans la console et appuyer sur « Entrée » pour exécuter ces commandes , mais elles seront oubliées lorsque vous fermerez la session.
Parce que nous voulons que notre code et notre flux de travail soient reproductibles, il est préférable de taper les commandes souhaitées dans l’éditeur de script et d’enregistrer le script . De cette façon, il existe un enregistrement complet de ce que nous avons fait, et n’importe qui (y compris nous-même !) pourra reproduire facilement les résultats sur n’importe quel ordinateur. Notez cependant que le simple fait de taper les commandes dans le script ne les exécute pas automatiquement - elles doivent quand même être envoyées à la console pour exécution.
RStudio vous permet d’exécuter des commandes directement depuis
l’éditeur de script en utilisant le raccourci Ctrl +
Entrée (sur Mac, Cmd + Return
fonctionnera également). La commande sur la ligne actuelle du script
(indiquée par le curseur) ou toutes les commandes dans le texte qui sont
sélectionnées seront envoyées à la console et exécutées lorsque vous
appuyez sur Ctrl + Entrer. Vous pouvez trouver
d’autres raccourcis clavier dans cette aide-mémoire RStudio sur l’IDE
RStudio .
Lors de votre analyse, il est possible qu’à un moment donné vous
souhaitiez vérifier le contenu d’une variable ou la structure d’un
objet, sans nécessairement vouloir sauvergarder cette commande dans
votre script. Vous pouvez taper ces commandes et les exécuter
directement dans la console. RStudio fournit les raccourcis
Ctrl + 1 et Ctrl + 2
vous permettant de passer entre le script et les volets de la console
.
Si R est prêt à accepter les commandes, la console R affiche une
invite ‘>’. S’il reçoit une commande (en tappant, en faisant un
copié-collé ou en l’envoyant à partir de l’éditeur de script avec
Ctrl + Entrer), R va essayer de l’exécuter, et
lorsqu’il sera prêt, R affichera les résultats et une nouvelle invite
‘>’ apparaîtra.
Si R attend toujours que vous saisissiez plus de données parce que ce n’est pas encore terminé, la console affichera une invite « + ». Cela signifie que vous n’avez pas fini de saisir une commande complète. Ceci peut arriver s’il manque par exemple une parenthèse ou un guillemet. Lorsque cela se produit et que vous pensez avoir fini de taper votre commande, cliquez dans la fenêtre de la console et appuyez sur « Échap » ; cela annulera la commande incomplète et vous ramènera à l’invite ‘>’.
Comment en savoir plus pendant et après le cours ?
Le matériel que nous aborderons au cours de ce cours vous donnera un premier aperçu de la façon dont vous pouvez utiliser R pour analyser vos données. Cependant, vous devrez en apprendre davantage pour effectuer des opérations avancées telles que nettoyer votre jeu de données, utiliser des méthodes statistiques, ou créer de superbes graphiques5. La meilleure façon de devenir efficace et compétent en R, comme avec tout autre outil, est de l’utiliser pour répondre à de vraies questions de recherche. En tant que débutant, il peut sembler intimidant de devoir écrire un script à partir de zéro, et étant donné que de nombreuses personnes rendent leur code disponible en ligne, modifiant le code existant pour répondre à vos objectifs. cela pourrait vous permettre de démarrer plus facilement.

Cherche de l’aide
Utilisez l’interface d’aide intégrée de RStudio pour rechercher plus d’informations sur les fonctions R.
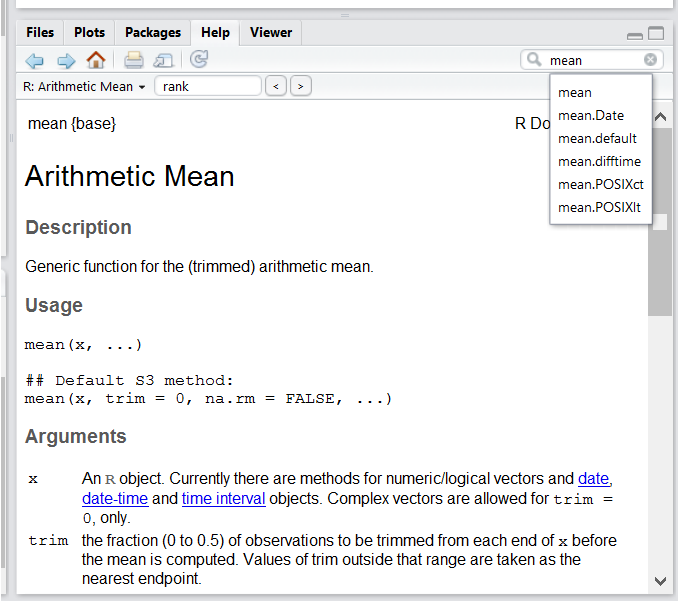
L’un des moyens les plus rapides d’obtenir de l’aide consiste à utiliser l’interface d’aide RStudio . Ce panneau par défaut se trouve dans le panneau inférieur droit de RStudio. Comme le montre la capture d’écran, en tapant le mot “Mean”, RStudio essaie également de donner un certain nombre de suggestions qui pourraient vous intéresser . La description s’affiche alors dans la fenêtre d’affichage .
Je connais le nom de la fonction que je souhaite utiliser, mais je ne sais pas comment l’utiliser
Si vous avez besoin d’aide à propos d’une fonction spécifique, par
exemple barplot(), vous pouvez taper :
R
?barplot
Si vous avez juste besoin de vous rappeler les noms des arguments, vous pouvez utiliser :
R
args(lm)
Je veux utiliser une fonction qui fait X, il doit y avoir une fonction pour ça mais je ne sais pas laquelle…
Si vous recherchez une fonction pour effectuer une tâche
particulière, vous pouvez utiliser la fonction
help.search(), qui est appelée par le double point
d’interrogation ??. Cependant, cela ne recherche dans les
packages installés que les pages d’aide avec une correspondance avec
votre demande de recherche.
R
??kruskal
Si vous ne trouvez pas ce que vous cherchez, vous pouvez utiliser le site Web rdocumentation.org qui recherche dans les fichiers d’aide de tous les packages disponibles.
Enfin, une recherche générique sur Google ou sur Internet “R <task>” vous enverra souvent soit à la documentation du package appropriée, soit à un forum utile où quelqu’un d’autre a déjà posé votre question.
Je suis coincé… Je reçois un message d’erreur que je ne comprends pas
Commencez par rechercher le message d’erreur sur Google. Cela ne fonctionne cependant pas toujours très bien car souvent, les développeurs de packages s’appuient sur la détection d’erreurs fournie par R. Vous vous retrouvez avec des messages d’erreur généraux qui pourraient ne pas être très utiles pour diagnostiquer un problème (par exemple “indice hors limites”). Si le message est très générique, vous pouvez également inclure le nom de la fonction ou du package que vous utilisez dans votre requête.
Cependant, vous devriez vérifier Stack Overflow. Recherchez en
utilisant la balise [r]. La plupart des questions ont déjà
reçu une réponse, mais le défi consiste à utiliser les bons mots clés
dans la recherche pour trouver les réponses :
http://stackoverflow.com/questions/tagged/r
L’Introduction à R peut sembler compliquée pour les personnes ayant peu d’expérience en programmation, mais c’est une bonne base pour tenter comprendre les fondements du langage R.
La section FAQ R est également assez technique mais elle est riche et regorge d’informations utiles.
Demander de l’aide
La clé pour recevoir de l’aide de quelqu’un est qu’il comprenne rapidement votre problème. Vous devez faire en sorte qu’il soit aussi simple que possible d’identifier où pourrait se situer le problème.
Essayez d’utiliser les mots corrects pour décrire votre problème. Par exemple, un package n’est pas la même chose qu’une librairie. La plupart des gens comprendront ce que vous vouliez dire, mais d’autres ont des sentiments très forts à propos de la différence de sens. Le point clé est que cela peut rendre les choses déroutantes pour les personnes qui essaient de vous aider. Soyez aussi précis que possible lorsque vous décrivez votre problème.
Si possible, essayez de réduire ce qui ne fonctionne pas à un exemple simple et reproductible. Si vous pouvez reproduire le problème en utilisant une petite table de données au lieu de celui de 50 000 lignes et 10 000 colonnes, fournissez le petit avec la description de votre problème. Essayez aussi de généraliser ce que vous faites afin que les personnes qui ne connaissent pas grand chose à votre domaine puissent également comprendre la question. Par exemple, au lieu d’utiliser un sous-ensemble de votre ensemble de données réel, créez un petit (3 colonnes, 5 lignes) générique. Pour plus d’informations sur la façon d’écrire un exemple reproductible, voir cet article de Hadley Wickham.
Pour partager un objet avec quelqu’un d’autre, s’il est relativement
petit, vous pouvez utiliser la fonction dput(). Elle
produira du code R qui pourra être utilisé pour recréer exactement le
même objet que celui en mémoire :
R
## iris is an example data frame that comes with R and head() is a
## function that returns the first part of the data frame
dput(head(iris))
OUTPUT
structure(list(Sepal.Length = c(5.1, 4.9, 4.7, 4.6, 5, 5.4),
Sepal.Width = c(3.5, 3, 3.2, 3.1, 3.6, 3.9), Petal.Length = c(1.4,
1.4, 1.3, 1.5, 1.4, 1.7), Petal.Width = c(0.2, 0.2, 0.2,
0.2, 0.2, 0.4), Species = structure(c(1L, 1L, 1L, 1L, 1L,
1L), levels = c("setosa", "versicolor", "virginica"), class = "factor")), row.names = c(NA,
6L), class = "data.frame")Si l’objet est plus grand, vous pouvez fournir le fichier brut (c’est-à-dire votre fichier CSV) avec votre script jusqu’au point d’erreur (après avoir supprimé tout ce qui n’est pas pertinent pour votre problème). Alternativement, si votre question n’est pas liée à un jeu de données en particulier, vous pouvez enregistrer n’importe quel objet R dans un fichier[^export] :
R
saveRDS(iris, file="/tmp/iris.rds")
Le contenu de ce fichier ne sera cependant pas lisible directement et
ne pourra pas être publié directement sur Stack Overflow. Il pourra par
contre être envoyé à quelqu’un par email qui pourra le lire avec la
commande readRDS() (dans ce cas-ci, le fichier téléchargé
est censé se trouver dans un dossier Téléchargements du
répertoire personnel de l’utilisateur) :
R
some_data <- readRDS(file="~/Downloads/iris.rds")
Dernier point, mais non des moindres, incluez toujours le
résultat de la fonction sessionInfo() car elle
fournit des informations essentielles concernant votre plate-forme, les
versions de R et des packages que vous avez utilisé ainsi que
d’autres informations qui peuvent être importantes pour comprendre votre
problème.
R
sessionInfo()
OUTPUT
R version 4.5.0 (2025-04-11)
Platform: x86_64-pc-linux-gnu
Running under: Ubuntu 24.04.2 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.12.0
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.12.0 LAPACK version 3.12.0
locale:
[1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
[4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
[7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
[10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
time zone: Asia/Tokyo
tzcode source: system (glibc)
attached base packages:
[1] stats graphics grDevices utils datasets methods base
loaded via a namespace (and not attached):
[1] compiler_4.5.0 tools_4.5.0 knitr_1.50 xfun_0.52 evaluate_1.0.3Où demander de l’aide ?
- La personne assise à côté de vous pendant le cours. N’hésitez pas à à comparer vos réponses, et demander de l’aide.
- De même si un gentil collègue a plus d’expérience que vous, n’hésitez pas à le solliciter, il pourra peut-être vous aider.
- Stack Overflow : si votre question n’a pas reçu de réponse auparavant et est bien conçue, il y a de fortes chances que vous obteniez un réponse en moins de 5 minutes. N’oubliez pas de suivre leurs directives sur la manière de poser une bonne question.
- La liste de diffusion R-help : elle est lue par un grand nombre de personnes (dont la plupart des l’équipe principale de R), beaucoup de gens y publient des messages, mais le ton peut être assez sec, et il n’est pas toujours très accueillant pour les nouveaux utilisateurs. Si votre question est valide, vous avez de bonnes chances d’obtenir une réponse très rapidement, mais ne vous attendez pas à ce que celle-ci arrive avec formules de politesse. Ici plus qu’ailleurs, veillez à utiliser un vocabulaire précis (sinon vous pourriez obtenir une réponse signalant l’utilisation de mots incorrects plutôt que la réponse attendue). Vous aurez également plus de succès si votre question concerne une fonction de base plutôt qu’un package spécifique.
- Si votre question concerne un package spécifique, vérifiez
s’il existe une liste de diffusion dédiée à celui-ci. Habituellement, il
est inclus dans le fichier DESCRIPTION du package et est accessible en
utilisant
packageDescription("name-of-package"). Vous pouvez également essayer d’envoyer un e-mail directement à l’auteur du package ou d’ouvrir un ticket sur le référentiel de code (par exemple, GitHub). - Il existe également quelques listes de diffusion thématiques (Système d’information géographique SIG, phylogénétique, etc…), la liste complète se trouve ici.
Autres ressources
Le Guide de publication pour les listes de diffusion R.
-
Comment demander de l’aide R
directives utiles.
Ce billet de blog de Jon Skeet contient des conseils relativement complets sur la façon de poser des questions liées à la programmation.
Le package reprex est très utile pour créer des exemples reproductibles lorsque vous demandez de l’aide. Le lien « Comment poser des questions pour qu’elles obtiennent de réponses » de la communauté rOpenSci (lien Github et enregistrement vidéo ) comprend une présentation du package reprex et de sa philosophie.
Packages R
Chargement des paquets
Comme nous l’avons vu plus haut, les packages R jouent un
rôle essentiel dans R. Pour bénéficier des fonctionnalités d’un
package, il faut qu’il soit préalablement installé et chargé.
Cela se fait avec la fonction library(). Ci-dessous, nous
chargeons ggplot2.
R
library("ggplot2")
Installation des packages
The Comprehensive R Archive Network (CRAN) heberge de
nombreux packages. Ceux qui sont disponibles sur CRAN peuvent
être installés avec la fonction install.packages().
Ci-dessous, nous installons par exemple le package
dplyr que nous découvrirons plus tard.
R
install.packages("dplyr")
Cette commande installera le package dplyr
ainsi que toutes ses dépendances, c’est à dire tous les
packages sur lesquels il s’appuie pour fonctionner.
Un autre source majeure de packages R est gérée par Bioconductor. Packages
Bioconductor sont gérés et installés à l’aide d’un package dédié, à
savoir BiocManager, qui peut être installé à partir de CRAN
avec
R
install.packages("BiocManager")
Des packages spécifiques tels que SummarizedExperiment
(nous l’utiliserons plus tard), DESeq2 (pour l’analyse
RNA-Seq) et tout autre package Bioconductor ou CRAN peuvent
ensuite être installés avec BiocManager::install.
R
BiocManager::install("SummarizedExperiment")
BiocManager::install("DESeq2")
Par défaut, BiocManager::install()examinera également
tous vos packages installés et vérifiera si des versions plus récentes
sont disponibles. S’il y en a, il vous les montrera et vous demandera si
vous souhaitez « Mettre à jour tout/certains/aucun ? . Bien que vous
deviez vous efforcer de disposer des dernières versions des
packages, en pratique, nous vous recommandons de ne les mettre
à jour que lors d’une nouvelle session R avant le chargement des
packages.
Key Points
- Commencez à utiliser R et RStudio
Au lieu d’utiliser R directement en ligne de commande à partir de la console . Il existe d’autres logiciels d’interface avec R, mais RStudio est particulièrement bien adapté aux débutants tout en proposant de nombreuses fonctionnalités très avancées.↩︎
Ce sont des modules complémentaires qui confèrent à R de nouvelles fonctionnalités, telles que l’analyse de données bioinformatiques.↩︎
Dans ce cours, nous considérons la bioinformatique comme une science des données appliquée aux données biologiques ou bio-médicales.↩︎
Cette personne pourrait être, et sera très probablement vous-même, quelques mois ou années après que les analyses aient été effectuées.↩︎
Nous présenterons ici la plupart d’entre eux (sauf les statistiques), mais nous ne parviendrons à explorer qu’une infime partie de ce qu’il est possible de faire avec R.↩︎
Content from Introduction à R
Last updated on 2025-05-05 | Edit this page
Estimated time: 120 minutes
Overview
Questions
- Premières commandes dans R
Objectives
- Définir les termes suivants relatifs à R : objet, affectation, appel, fonction, arguments, options.
- Attribuer des valeurs aux objets dans R.
- Apprendre à nommer des objets.
- Utiliser des commentaires pour informer le script.
- Résoudre des opérations arithmétiques simples dans R.
- Appeler des fonctions et utiliser des arguments pour modifier leurs options par défaut.
- Inspecter le contenu des vecteurs et manipulez leur contenu.
- Extraire un sous-ensemble ou des valeurs à partir de vecteurs.
- Analyser des vecteurs contenant des données manquantes.
Cet épisode est basé sur le cours Data Analysis and Visualization in R for Ecologists (Analyse de données et Visualisation en R pour les écologistes) de Data Carpentries.
Créer des objets dans R
En R, vous pouvez obtenir des résultats simplement en tapant des opérations mathématiques directement dans la console :
R
3 + 5
OUTPUT
[1] 8R
12 / 7
OUTPUT
[1] 1.714286Cependant, pour faire des analyses utiles et intéressantes, il est avantageux d’attribuer des valeurs à des objets. Pour créer un objet, nous devons lui donner un nom suivi de l’opérateur d’assignation `←
R
poids_kg <- 55
<- est l’opérateur d’assignation (affectation). Il
attribue des valeurs à droite aux objets à gauche. Ainsi, après avoir
exécuté x <- 3, la valeur de x est
3. La flèche peut être lue comme 3 entre
dans x. Pour des raisons historiques, vous pouvez
également utiliser = pour les assignations, mais pas dans
tous les contextes. En raison de légères
différences dans la syntaxe, une bonne pratique est de toujours
utiliser <- pour les assignations.
Dans RStudio, sur un PC, taper Alt + - (appuyer
sur Alt en même temps que la touche - ) écrira
<- en une seule frappe, tandis que taper
Option + - (appuyer sur Option en même
temps que la touche - ) fera de même sur un Mac.
Nommer les variables
Les objets peuvent avoir n’importe quel nom tel que « x », «
current_temperature » ou « subject_id ». Il est souhaitable que les noms
de vos objets soient explicites et pas trop longs. Ils ne peuvent pas
commencer par un nombre (2x n’est pas un nom valide, mais
x2 l’est). R est sensible à la casse (par exemple,
weight_kg est différent de Weight_kg).
Certains noms ne peuvent pas être utilisés car ils sont les noms de
fonctions fondamentales dans R (par exemple, if,
else, for, voir ici
pour une liste complète des noms réservés). En général, même si c’est
autorisé, il est préférable de de ne pas utiliser d’autres noms de
fonctions (par exemple, c, T,
mean, data, df,
weight). En cas de doute, consultez l’aide pour voir si le
nom est déjà utilisé. Il est également préférable d’éviter les points
(.) dans un nom d’objet comme dans my.dataset
(utilisez plutôt my_dataset par exemple). Vous remarquerez
cependant qu’il existe de nombreuses fonctions dans R avec des points
dans leurs noms. Ces noms de fonction sont conservés pour des raisons
historiques, mais comme les points ont une signification particulière en
R (pour les méthodes) et autres langages de programmation, il est
préférable de les éviter. Il est également recommandé d’utiliser des
noms pour les noms d’objets et des verbes pour les noms de fonctions. Il
est important d’être cohérent dans le style de votre code (où vous
placez les espaces, comment vous nommez les objets, etc.). L’utilisation
d’un style de codage cohérent rend votre code plus clair à lire pour vos
collaborateurs, mais aussi pour vous-même dans le futur (vous vous
remercierez plus tard). En R, il existe plusieurs guides de styles
populaires comme le guides de style de Google, du
tidyverse ou le Bioconductor
style guide. Le style Tidyverse est très complet mais peut sembler un
peu lourd au début. Vous pouvez installer le package lintr
qui vérifiera et corrigera automatiquement les problèmes ou incohérences
dans le style de votre code.
Objets et variables : ce que l’on appelle des « objets » en « R » sont connus sous le nom de « variables » dans de nombreux autres langages de programmation. Selon le contexte, « objet » et « variable » peuvent avoir des significations radicalement différentes. Cependant, dans cette leçon, les deux mots sont utilisés de manière synonyme. Pour plus d’informations voir ce lien.
Lors de l’attribution d’une valeur à un objet, R n’imprime rien dans la console. Vous pouvez forcer R à imprimer la valeur d’un objet en utilisant des parenthèses ou en tapant le nom de l’objet :
R
weight_kg <- 55 # n'imprime rien
(weight_kg <- 55) # mais mettre des parenthèses autour de l'appel imprime la valeur de `weight_kg`
OUTPUT
[1] 55R
weight_kg # et taper également le nom du objet
OUTPUT
[1] 55Maintenant que R a weight_kg en mémoire, nous pouvons
faire des opérations arithmétiques sur cet objet. Par exemple, nous
pouvons vouloir convertir ce poids en livres (le poids en livres est 2,2
fois le poids en kg) :
R
2.2 * weight_kg
OUTPUT
[1] 121On peut également changer la valeur d’un objet en lui attribuant une nouvelle valeur :
R
weight_kg <- 57.5
2.2 * weight_kg
OUTPUT
[1] 126.5L’attribution d’une valeur à un objet ne modifie pas les valeurs
d’autres objets. Par exemple, stockons le poids en livres dans un nouvel
objet weight_lb :
R
weight_lb <- 2.2 * weight_kg
puis remplacons weight_kg par 100.
R
weight_kg <- 100
Défi:
Selon vous, quel est maintenant le contenu de l’objet
weight_lb ? 126.5 ou 220?
Commentaires
En R, le caractère de commentaire est #. Tout ce qui se
trouve à droite d’un # dans un script sera ignoré par R.
Les commentaires sont utiles pour laisser des notes et explications dans
vos scripts.
RStudio permet de facilement commenter ou “décommenter” un paragraphe : après avoir sélectionné les lignes que vous souhaitez commenter (ou décommenter), appuyez simultanément sur les touches Ctrl + Shift + C. Si vous ne souhaitez commenter qu’une seule ligne, vous pouvez placer le curseur à n’importe quel emplacement de cette ligne (il n’est pas nécessaire de sélectionner la ligne entière), puis appuyez sur Ctrl + Shift + C.
Défi
Quelles sont les valeurs des objets après chaque instruction ci-dessous ?
R
mass <- 47.5 # mass?
age <- 122 # age?
mass <- mass * 2.0 # mass?
age <- age - 20 # age?
mass_index <- mass/age # mass_index?
Les fonctions et leurs arguments
Les fonctions sont des “scripts prédéfinis” qui automatisent des
ensembles de commandes plus complexes, y compris les affectations
d’opérations. De nombreuses fonctions sont prédéfinies ou peuvent être
rendues disponibles en important des packages R (nous en
parlerons plus tard). Une fonction “prend” généralement une ou plusieurs
entrées appelées arguments. Les fonctions renvoient souvent
(mais pas toujours) une valeur. Un exemple typique serait la
fonction sqrt(). L’entrée (l’argument) doit être un nombre
et la valeur de retour (la “sortie”) est la racine carrée de ce nombre.
Exécuter une fonction est appelé appeler la fonction (“call
a function” en anglais). Un exemple d’appel de fonction est :
R
b <- sqrt(a)
Ici, la valeur de a est donnée à la fonction
sqrt(), la fonction sqrt() en calcule la
racine carrée, et renvoie cette valeur qui est ensuite attribuée à
l’objet b. Cette fonction est simple car elle ne prend
qu’un seul argument.
La valeur de retour d’une fonction (sa sortie) n’est pas
nécessairement numérique (comme celle de sqrt()), et elle
n’est pas forcément un élément unique : une sortie peut être un ensemble
de choses, ou même un jeu de données. Nous en verrons un exemple lorsque
nous lirons des fichiers de données dans R.
Les arguments peuvent aussi être divers, pas uniquement des nombres ou noms de fichiers, mais aussi d’autres objets (listes, jeux de données, etc.). La signification exacte de chaque argument diffère selon la fonction et doit être recherchée dans la documentation (voir ci-dessous). Certaines fonctions ont des arguments qui peuvent être spécifiés par l’utilisateur ou prendre une valeur par défaut : ces arguments optionnels sont appelés options. Les options sont généralement utilisées pour modifier le fonctionnement de la fonction, par exemple si elle doit ignorer les « mauvaises valeurs » ou quel symbole utiliser dans un graphique. Si vous souhaitez un comportement spécifique pour une fonction, vous pouvez spécifier une valeur de votre choix qui sera utilisée à la place de la valeur par défaut.
Essayons maintenant une fonction qui peut prendre plusieurs arguments
: round().
R
round(3.14159)
OUTPUT
[1] 3Ici, nous avons appelé round() avec un seul argument,
3.14159, et il a renvoyé la valeur 3. En
effet, le comportement par défaut de la fonction round()
est d’arrondir au nombre entier le plus proche. Si nous souhaitons
conserver quelques chiffres décimaux, nous pouvons voir comment procéder
en obtenant des informations sur la fonction round.
args(round) ou ?round nous permettront
d’obternir des informations sur les arguments (optionnels) de la
fonction round.
R
args(round)
OUTPUT
function (x, digits = 0, ...)
NULLR
?round
Nous voyons que si nous souhaitons deux chiffres décimaux, nous
pouvons taper digits=2.
R
round(3.14159, digits = 2)
OUTPUT
[1] 3.14Si vous fournissez les arguments exactement dans le même ordre que celui dans lequel ils sont définis, vous n’avez pas besoin de les nommer :
R
round(3.14159, 2)
OUTPUT
[1] 3.14Et si vous nommez les arguments, vous pouvez changer leur ordre :
R
round(digits = 2, x = 3.14159)
OUTPUT
[1] 3.14Il est recommandé de placer les arguments non facultatifs (comme le nombre que vous arrondissez) en premier dans votre appel de fonction et de spécifier les noms de tous les arguments facultatifs. Si vous ne le faites pas, quelqu’un qui lit votre code devra peut-être rechercher la définition d’une fonction avec des arguments inconnus pour comprendre ce que vous faites. En spécifiant le nom des arguments, vous protégez également votre code contre d’éventuelles modifications futures dans l’interface de la fonction, qui peuvent potentiellement ajouter de nouveaux arguments entre ceux existants.
Vecteurs et types de données
Le vecteur est le type de données le plus courant, basique et central
de R. Un vecteur est composé d’une série de valeurs, telles que des
nombres ou caractères. Nous pouvons attribuer une série de valeurs à un
vecteur en utilisant la fonction c(). Par exemple, nous
pouvons créer un vecteur de poids d’animaux et l’attribuer à un nouvel
objet weight_g :
R
weight_g <- c(50, 60, 65, 82)
weight_g
OUTPUT
[1] 50 60 65 82Un vecteur peut également contenir des caractères :
R
molecules <- c("dna", "rna", "protein")
molecules
OUTPUT
[1] "dna" "rna" "protein"Les guillemets autour de "dna", "rna", etc.
sont ici essentiels. Sans les guillemets, R supposera qu’il existe des
objets appelés dna, rna et
protein. Comme ces objets n’existent pas dans la mémoire de
R, il y aura un message d’erreur.
Il existe de nombreuses fonctions qui vous permettent d’inspecter le
contenu d’un vecteur. length() vous indique combien
d’éléments se trouvent dans un vecteur particulier :
R
length(weight_g)
OUTPUT
[1] 4R
length(molecules)
OUTPUT
[1] 3Une caractéristique importante d’un vecteur est que tous les éléments
sont du même type de données. La fonction class() indique
la classe (le type d’élément) d’un objet :
R
class(weight_g)
OUTPUT
[1] "numeric"R
class(molecules)
OUTPUT
[1] "character"La fonction str() fournit un aperçu de la structure d’un
objet et de ses éléments. C’est une fonction utile lorsque vous
travaillez avec des objets volumineux et complexes :
R
str(weight_g)
OUTPUT
num [1:4] 50 60 65 82R
str(molecules)
OUTPUT
chr [1:3] "dna" "rna" "protein"Vous pouvez utiliser la fonction c() pour ajouter
d’autres éléments à votre vecteur :
R
weight_g <- c(weight_g, 90) # ajout à la fin du vecteur
weight_g <- c(30, weight_g) # ajout au début du vecteur
weight_g
OUTPUT
[1] 30 50 60 65 82 90Dans la première ligne, nous prenons le vecteur d’origine
weight_g, y ajoutons la valeur 90 à la fin et
enregistrons le résultat dans weight_g. Dans la deuxième
ligne, nous ajoutons la valeur « 30 » au début, en enregistrant à
nouveau le résultat dans « weight_g ».
Nous pouvons continuer à compléter ainsi un vecteur ou utiliser cette syntaxe pour assembler des données. Cela peut être utile pour ajouter les résultats que nous collectons ou calculons au fur et à mesure de notre analyse.
Un vecteur atomique est le type de
données R le plus simple; il s’agit d’un vecteur linéaire
composé d’éléments du même type. Plus tôt, nous avons vu 2 des 6
principaux types de vecteurs atomiques que R utilise :
"character" (caractères) et "numeric"
(chiffres, décimaux ou entiers) (ou "double" (réels)). Ce
sont les éléments de base à partir desquels tous les objets R sont
construits. Les 4 autres types de vecteurs atomiques
sont :
-
"logical"pourTRUEetFALSE(le type de données booléen) -
"integer"pour les nombres entiers (par exemple,2L, leLindique à R que c’est un entier) -
"complex"pour représenter des nombres complexes avec des parties réelles et imaginaires (par exemple,1 + 4i); et c’est tout ce que dirons à leur sujet -
"raw"pour les “flux de bits” (bitstreams) dont nous ne parlerons pas davantage
Vous pouvez vérifier le type de votre vecteur en utilisant la
fonction typeof() et en saisissant votre vecteur comme
argument.
Les vecteurs sont l’une des nombreuses structures de
données utilisées par R. Les autres structures importantes sont
les listes (list), les matrices (matrix), les
tables de données (data.frame), les facteurs
(factor) et les tableaux (array ).
Défi:
Nous avons vu que les vecteurs atomiques peuvent être de type caractère, numérique (ou double), entier et logique. Que se passe-t-il si nous essayons de mélanger ces types dans un seul vecteur ?
R les convertit implicitement pour qu’ils soient tous du même type
Défi:
Que se passera-t-il dans chacun de ces exemples ? (indice : utilisez
la fonction class() pour vérifier le type de données des
objets) :
R
num_char <- c(1, 2, 3, "a")
num_logical <- c(1, 2, 3, TRUE, FALSE)
char_logical <- c("a", "b", "c", TRUE)
tricky <- c(1, 2, 3, "4")
R
class(num_char)
OUTPUT
[1] "character"R
num_char
OUTPUT
[1] "1" "2" "3" "a"R
class(num_logical)
OUTPUT
[1] "numeric"R
num_logical
OUTPUT
[1] 1 2 3 1 0R
class(char_logical)
OUTPUT
[1] "character"R
char_logical
OUTPUT
[1] "a" "b" "c" "TRUE"R
class(tricky)
OUTPUT
[1] "character"R
tricky
OUTPUT
[1] "1" "2" "3" "4"Défi:
Pourquoi pensez-vous que cela arrive ?
Les éléments des vecteurs ne peuvent appartenir qu’à un seul type de données. R essaie donc de convertir le contenu de ce vecteur pour trouver un dénominateur commun qui n’amène à aucune perte d’information.
Défi:
Combien de valeurs dans combined_logical sont
"TRUE" (sous forme de caractère) dans l’exemple
suivant :
R
num_logical <- c(1, 2, 3, TRUE)
char_logical <- c("a", "b", "c", TRUE)
combined_logical <- c(num_logical, char_logical)
Seulement un. Il n’y a pas de mémoire des types de données passés et
la conversion (“coercition”) se produit la première fois que le vecteur
est évalué. Par conséquent, le TRUE dans
num_logical est converti en 1 avant d’être
converti en "1" dans combined_logical.
R
combined_logical
OUTPUT
[1] "1" "2" "3" "1" "a" "b" "c" "TRUE"Défi:
Dans R, nous appelons la conversion d’objets d’une classe vers une autre classe coercition. Ces conversions se produisent selon une hiérarchie, selon laquelle certains types sont préférentiellement contraints vers d’autres types. Pouvez-vous dessiner un diagramme qui représente la hiérarchie de la façon dont ces types de données sont forcés ?
logique → numérique → caractère ← logique
Extraire des valeurs d’un vecteur (Subsetting)
Si l’on veut extraire une ou plusieurs valeurs d’un vecteur, il faut fournir un ou plusieurs indices entre crochets. Par exemple:
R
molecules <- c("dna", "rna", "peptide", "protein")
molecules[2]
OUTPUT
[1] "rna"R
molecules[c(3, 2)]
OUTPUT
[1] "peptide" "rna" On peut également répéter les indices pour créer un objet avec plus d’éléments que celui d’origine :
R
more_molecules <- molecules[c(1, 2, 3, 2, 1, 4)]
more_molecules
OUTPUT
[1] "dna" "rna" "peptide" "rna" "dna" "protein"En R, les indices commencent à 1. Les langages de programmation comme Fortran, MATLAB, Julia et R commencent à compter à 1, car c’est ce que font généralement les êtres humains. Les langages de la famille C (y compris C++, Java, Perl, et Python) comptent à partir de 0 car c’est plus simple à faire pour les ordinateurs.
En utilisant des indices négatifs, on peut obtenir tous les éléments d’un vecteur sauf ceux spécifiés par les indices négatifs :
R
molecules ## all molecules
OUTPUT
[1] "dna" "rna" "peptide" "protein"R
molecules[-1] ## all but the first one
OUTPUT
[1] "rna" "peptide" "protein"R
molecules[-c(1, 3)] ## all but 1st/3rd ones
OUTPUT
[1] "rna" "protein"R
molecules[c(-1, -3)] ## all but 1st/3rd ones
OUTPUT
[1] "rna" "protein"Sous-ensemble conditionnel
Une autre méthode courante de sous-ensemble consiste à utiliser un
vecteur logique. TRUE sélectionnera l’élément avec le même
index, tandis que FALSE ne le fera pas :
R
weight_g <- c(21, 34, 39, 54, 55)
weight_g[c(TRUE, FALSE, TRUE, TRUE, FALSE)]
OUTPUT
[1] 21 39 54Généralement, ces vecteurs logiques ne sont pas tapés à la main, mais sont le résultat d’autres fonctions ou tests logiques. Par exemple, si vous souhaitez sélectionner uniquement les valeurs supérieures à 50 :
R
## will return logicals with TRUE for the indices that meet
## the condition
weight_g > 50
OUTPUT
[1] FALSE FALSE FALSE TRUE TRUER
## so we can use this to select only the values above 50
weight_g[weight_g > 50]
OUTPUT
[1] 54 55Vous pouvez combiner plusieurs tests en utilisant &
(les deux conditions sont vraies, AND) ou | (au moins une
des conditions est vraie, OR) :
R
weight_g[weight_g < 30 | weight_g > 50]
OUTPUT
[1] 21 54 55R
weight_g[weight_g >= 30 & weight_g == 21]
OUTPUT
numeric(0)Ici, < signifie “inférieur à”, >
signifie “supérieur à”, >= signifie “supérieur ou égal
à” et == signifie “égal à”. Le double signe égal
== est un test d’égalité numérique entre les côtés gauche
et droit, et ne doit pas être confondu avec le signe simple
=, qui effectue une affectation de variable (similaire à
<-).
Une tâche courante consiste à rechercher certaines chaînes de
caractères dans un vecteur. On pourrait utiliser l’opérateur “ou”
| pour tester l’égalité de plusieurs valeurs, mais cela
peut rapidement devenir fastidieux. La fonction %in% permet
de tester si l’un des éléments d’un vecteur de recherche est trouvé
:
R
molecules <- c("dna", "rna", "protein", "peptide")
molecules[molecules == "rna" | molecules == "dna"] # returns both rna and dna
OUTPUT
[1] "dna" "rna"R
molecules %in% c("rna", "dna", "metabolite", "peptide", "glycerol")
OUTPUT
[1] TRUE TRUE FALSE TRUER
molecules[molecules %in% c("rna", "dna", "metabolite", "peptide", "glycerol")]
OUTPUT
[1] "dna" "rna" "peptide"Défi:
À votre avis, pourquoi est-ce "four" > "five"
("quatre" > "cinq") renvoie TRUE ?
R
"four" > "five"
OUTPUT
[1] TRUELorsque vous utilisez > ou < sur des
chaînes de caractère, R compare leur ordre alphabétique. Ici,
"four" (quatre) vient alphabétiquement après
"five" (cinq), et est donc supérieur à cinq.
Noms d’éléments d’un vecteur
Il est possible de nommer chaque élément d’un vecteur. Le code ci-dessous montre un exemple d’un vecteur dont les éléments n’ont initialement aucun nom, et comment on peut ensuite définir et récupérer les noms des éléments.
R
x <- c(1, 5, 3, 5, 10)
names(x) ## no names
OUTPUT
NULLR
names(x) <- c("A", "B", "C", "D", "E")
names(x) ## now we have names
OUTPUT
[1] "A" "B" "C" "D" "E"Lorsqu’un vecteur possède des noms, il est possible d’accéder aux éléments par leur nom, en plus de par leur index.
R
x[c(1, 3)]
OUTPUT
A C
1 3 R
x[c("A", "C")]
OUTPUT
A C
1 3 Données manquantes
Comme R a été conçu pour analyser des jeux de données, il inclut le
concept de données manquantes (ce qui est rare dans d’autres langages de
programmation). Les données manquantes sont représentées dans les
vecteurs par NA (pour not applicable).
Lorsque vous effectuez des opérations sur des nombres, la plupart des
fonctions renverront NA si les données avec lesquelles vous
travaillez incluent des valeurs manquantes. Cette fonctionnalité par
défaut rend plus difficile l’ignorance des cas où vous avez affaire à
des données manquantes. Vous pouvez ajouter l’argument
na.rm = TRUE pour calculer le résultat en ignorant les
valeurs manquantes (na.rm peut se traduire par “remove
NA”, où “remove” signifie “enlever” en anglais).
R
heights <- c(2, 4, 4, NA, 6)
mean(heights)
OUTPUT
[1] NAR
max(heights)
OUTPUT
[1] NAR
mean(heights, na.rm = TRUE)
OUTPUT
[1] 4R
max(heights, na.rm = TRUE)
OUTPUT
[1] 6Si vos données incluent des valeurs manquantes, vous souhaiterez
peut-être vous familiariser avec les fonctions is.na(),
na.omit() et complete.cases(). Voici quelques
exemples.
R
## Extrait les éléments qui ne sont pas manquants.
heights[!is.na(heights)]
OUTPUT
[1] 2 4 4 6R
## Renvois un objet dont les cas incomplets ont été supprimés.
## L'objet renvoyé est un vecteur atomique du type "numeric"
## (ou "double").
na.omit(heights)
OUTPUT
[1] 2 4 4 6
attr(,"na.action")
[1] 4
attr(,"class")
[1] "omit"R
## Extrait les éléments qui représentent des cas complets.
## L'objet renvoyé est un vecteur atomique du type "numeric"
## (ou "double").
heights[complete.cases(heights)]
OUTPUT
[1] 2 4 4 6Défi:
- En utilisant ce vecteur de hauteurs en pouces (inches), créez un nouveau vecteur en supprimant les NA.
R
heights <- c(63, 69, 60, 65, NA, 68, 61, 70, 61, 59, 64, 69, 63, 63, NA, 72, 65, 64, 70, 63, 65)
- Utilisez la fonction
median()pour calculer la médiane du vecteurheights. - Utilisez R pour déterminer combien de personnes dans l’échantillon mesurent plus de 67 pouces.
R
heights_no_na <- heights[!is.na(heights)]
## or
heights_no_na <- na.omit(heights)
R
median(heights, na.rm = TRUE)
OUTPUT
[1] 64R
heights_above_67 <- heights_no_na[heights_no_na > 67]
length(heights_above_67)
OUTPUT
[1] 6Génération de vecteurs
Constructeurs
Il existe quelques fonctions pour générer des vecteurs de différents
types. Pour générer un vecteur de valeurs numériques, on peut utiliser
le constructeur numeric(), en lui fournissant la longueur
du vecteur de sortie comme paramètre. Les valeurs seront initialisées à
0.
R
numeric(3)
OUTPUT
[1] 0 0 0R
numeric(10)
OUTPUT
[1] 0 0 0 0 0 0 0 0 0 0Notez que si l’on demande un vecteur de numériques de longueur 0, on obtient exactement cela :
R
numeric(0)
OUTPUT
numeric(0)Il existe des constructeurs similaires pour les caractères et les
logiques, nommés respectivement character() et
logical().
Défi:
Quelles sont les valeurs par défaut pour les vecteurs de caractères et les vecteurs logiques ?
R
character(2) ## the empty character
OUTPUT
[1] "" ""R
logical(2) ## FALSE
OUTPUT
[1] FALSE FALSERépliquer des éléments
La fonction rep permet de répéter une valeur un certain
nombre de fois. Si nous voulons initier un vecteur de numériques de
longueur 5 avec la valeur -1, par exemple, nous pourrions faire ce qui
suit :
R
rep(-1, 5)
OUTPUT
[1] -1 -1 -1 -1 -1De même, pour générer un vecteur rempli de valeurs manquantes, ce qui est souvent une bonne façon de commencer, sans poser d’hypothèses sur les données qui seront collectées :
R
rep(NA, 5)
OUTPUT
[1] NA NA NA NA NArep peut prendre en entrée des vecteurs de n’importe
quelle longueur (ci-dessus, nous avons utilisé des vecteurs de longueur
1) et de n’importe quel type. Par exemple, si nous voulions répéter cinq
fois les valeurs 1, 2 et 3, nous procéderions comme suit :
R
rep(c(1, 2, 3), 5)
OUTPUT
[1] 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3Défi:
Et si nous voulions répéter les valeurs 1, 2 et 3 cinq fois, mais
obtenir cinq 1, cinq 2 et cinq 3 dans cet ordre, comment devrions-nous
procéder ? Il existe deux possibilités: voir ?rep ou
?sort pour obtenir de l’aide.
R
rep(c(1, 2, 3), each = 5)
OUTPUT
[1] 1 1 1 1 1 2 2 2 2 2 3 3 3 3 3R
sort(rep(c(1, 2, 3), 5))
OUTPUT
[1] 1 1 1 1 1 2 2 2 2 2 3 3 3 3 3Génération de séquences
Une autre fonction très utile est seq, pour générer une
séquence de nombres. Par exemple, pour générer une séquence d’entiers de
1 à 20 par pas de 2, on utiliserait :
R
seq(from = 1, to = 20, by = 2)
OUTPUT
[1] 1 3 5 7 9 11 13 15 17 19La valeur par défaut de by est 1 et, étant donné que la
génération d’une séquence d’une valeur à une autre avec des pas de 1 est
fréquemment utilisée, il existe un raccourci :
R
seq(1, 5, 1)
OUTPUT
[1] 1 2 3 4 5R
seq(1, 5) ## default by
OUTPUT
[1] 1 2 3 4 5R
1:5
OUTPUT
[1] 1 2 3 4 5Pour générer une séquence de nombres de 1 à 20 de longueur finale de 3, on utiliserait :
R
seq(from = 1, to = 20, length.out = 3)
OUTPUT
[1] 1.0 10.5 20.0Échantillons aléatoires et permutations
Un dernier groupe de fonctions utiles sont celles qui génèrent des
données aléatoires. La première, sample, génère une
permutation aléatoire d’un autre vecteur. Par exemple, pour tirer au
sort un ordre aléatoire de 10 étudiants pour leur examen oral,
j’attribue d’abord à chaque étudiant·e un numéro de 1 à dix (par exemple
en fonction de l’ordre alphabétique de leurs noms) puis :
R
sample(1:10)
OUTPUT
[1] 9 4 7 1 2 5 3 10 6 8Sans autres arguments, sample renverra une permutation
de tous les éléments du vecteur. Si je veux un échantillon aléatoire
d’une certaine taille, je définirais cette valeur comme deuxième
argument. Ci-dessous, j’échantillonne 5 lettres aléatoires de l’alphabet
contenu dans le vecteur letters prédéfini :
R
sample(letters, 5)
OUTPUT
[1] "s" "a" "u" "x" "j"Si je voulais une sortie plus grande que le vecteur d’entrée, ou
pouvoir tirer au sort certains éléments plusieurs fois, je devrais
définir l’argument replace à TRUE :
R
sample(1:5, 10, replace = TRUE)
OUTPUT
[1] 2 1 5 5 1 1 5 5 2 2Défi:
En essayant les fonctions ci-dessus, vous aurez réalisé que les
échantillons sont effectivement aléatoires et qu’on n’obtient pas deux
fois la même permutation. Pour pouvoir reproduire ces tirages
aléatoires, on peut définir manuellement la “graine d’échantillonage” de
nombres aléatoires avec la fonction set.seed() avant de
tirer l’échantillon aléatoire.
Testez cette fonctionnalité avec votre voisin. Tirez d’abord deux permutations aléatoires de « 1:10 » indépendamment et observez que vous obtenez résultats différents.
Définissez maintenant la graine avec, par exemple,
set.seed(123) et répétez le tirage au sort. Observez que
vous obtenez désormais les mêmes tirages.
Répétez en définissant une graine différente.
Différentes permutations
R
sample(1:10)
OUTPUT
[1] 9 1 4 3 6 2 5 8 10 7R
sample(1:10)
OUTPUT
[1] 4 9 7 6 1 10 8 3 2 5Mêmes permutations avec la graine 123
R
set.seed(123)
sample(1:10)
OUTPUT
[1] 3 10 2 8 6 9 1 7 5 4R
set.seed(123)
sample(1:10)
OUTPUT
[1] 3 10 2 8 6 9 1 7 5 4Une graine différente
R
set.seed(1)
sample(1:10)
OUTPUT
[1] 9 4 7 1 2 5 3 10 6 8R
set.seed(1)
sample(1:10)
OUTPUT
[1] 9 4 7 1 2 5 3 10 6 8Échantillonner à partir d’une distribution normale
La dernière fonction que nous allons voir est rnorm, qui
tire un échantillon aléatoire à partir d’une distribution normale. Deux
distributions normales de moyennes 0 et 100 et d’écarts types 1 et 5,
notées N(0, 1) et N(100, 5), sont présentées
graphiquement ci-dessous.
Les trois arguments, n, mean et
sd, définissent la taille de l’échantillon, et les
paramètres de la distribution normale, c’est-à-dire sa moyenne et son
écart type. Les valeurs par défaut de ces derniers sont 0 et 1.
R
rnorm(5)
OUTPUT
[1] 0.69641761 0.05351568 -1.31028350 -2.12306606 -0.20807859R
rnorm(5, 2, 2)
OUTPUT
[1] 1.3744268 -0.1164714 2.8344472 1.3690969 3.6510983R
rnorm(5, 100, 5)
OUTPUT
[1] 106.45636 96.87448 95.62427 100.71678 107.12595Maintenant que nous avons appris à écrire des scripts et connaissons les bases des structures de données de R, nous sommes prêts à commencer à travailler avec des données plus volumineuses et à en apprendre davantage sur les “data frames” (tables de données).
Key Points
- Comment interagir avec R
Content from Commencer par les données
Last updated on 2025-05-05 | Edit this page
Estimated time: 60 minutes
Overview
Questions
- Première analyse de données dans R.
Objectives
- Décrire ce qu’est un data frame.
- Charger des données externes à partir d’un fichier .csv dans un data frame.
- Résumer le contenu d’un data frame.
- Décrire ce qu’est un facteur.
- Convertissez entre les chaînes de caractère et les facteurs.
- Réorganiser et renommer les facteurs.
- Formatez les dates.
- Exporter et enregistrez les données.
Cet épisode est basé sur la leçon des Data Carpentries intitulée : Analyse des données et Visualisation dans R pour les écologistes.
Présentation des données d’expression des gènes
Nous allons utiliser une partie des données publiées par Blackmore , The effect of upper-respiratory infection on transcriptomic changes in the CNS. Le but de l’étude était de déterminer l’effet d’une infection des voies respiratoires supérieures sur les modifications de la transcription de l’ARN se produisant dans le cervelet et la moelle épinière après l’infection. Des souris C57BL/6, âgées de huit semaines et appariées selon le genre, ont été inoculées avec une solution saline ou avec la grippe A par voie intranasale et les changements transcriptomiques dans les tissus du cervelet et de la moelle épinière ont été évalués par RNA-seq aux jours 0 (non infectées), 4 et 8.
L’ensemble de données est stocké sous forme de fichier CSV (comma-separated values ou valeurs séparées par des virgules). Chaque ligne contient des informations pour une seule mesure d’expression d’ARN. Les onze premières colonnes représentent :
| Colonne | Description |
|---|---|
| gene | Le nom du gène qui a été mesuré. |
| sample | Le nom de l’échantillon dans lequel l’expression du gène a été mesurée. |
| expression | La valeur de l’expression des gènes. |
| organism | L’organisme/l’espèce - ici toutes les données proviennent de souris. |
| age | L’âge de la souris (ici toutes les souris ont 8 semaines) |
| sex | Le sexe de la souris. |
| infection | L’état d’infection de la souris, c’est-à-dire infectée par la grippe A ou non infectée. |
| strain | La souche grippale A. |
| time | La durée de l’infection (en jours). |
| tissue | Le tissu utilisé pour l’expérience d’expression génique, c’est-à-dire le cervelet (cerebellum) ou la moelle épinière (spinal cord). |
| mouse | L’identifiant unique de la souris. |
Nous allons utiliser la fonction R download.file() pour
télécharger le fichier CSV contenant les données d’expression génique.
Nous utiliserons ensuite read.csv() pour charger en mémoire
le contenu du fichier CSV en tant qu’objet de classe
data.frame. Dans la commande download.file, la
première entrée est une chaîne de caractères avec l’URL source. Cette
URL télécharge un fichier CSV à partir d’un dépôt GitHub (GitHub
repository). Le second argument :
destfile = "data/rnaseq.csv" (texte après la virgule)
correspond à la destination du fichier sur votre machine locale. Vous
aurez besoin d’un dossier sur votre ordinateur appelé
"data" dans lequel vous téléchargerez le fichier. Pour
récapituler, cette commande télécharge le fichier distant, le nomme
"rnaseq.csv" et l’ajoute à un dossier préexistant nommé
"data".
R
download.file(url = "https://github.com/carpentries-incubator/bioc-intro/raw/main/episodes/data/rnaseq.csv",
destfile = "data/rnaseq.csv" )
Vous êtes maintenant prêt à charger les données dans
R:
R
arn <- read.csv("data/rnaseq.csv")
Cette instruction ne produit aucune sortie dans la console car, comme vous vous en souvenez peut-être, les commandes d’assignation n’affichent rien. Si nous voulons vérifier que nos données ont bien été chargées, nous pouvons voir le contenu du data frame (tableau de données) en en tapant son nom :
R
arn
Ouah… cela fait beaucoup de lignes de sorties. Cela signifie que les
données ont été chargées correctement dans l’environnement de travail.
Vérifions le haut (les 6 premières lignes) de ce data frame en utilisant
la fonction head() :
R
head(rna)
ERROR
Error: object 'rna' not foundR
## Essayez aussi
## View(rna)
Note
read.csv() suppose que les champs soient délimités par
des virgules. Cependant, dans plusieurs pays et notamment en France, la
virgule est utilisée comme séparateur décimal et le point-virgule (;)
est utilisé comme délimiteur de champ. Si vous souhaitez lire ce type de
fichiers dans R, vous pouvez utiliser la fonction
read.csv2(). Il se comporte exactement comme
read.csv() mais utilise des paramètres différents pour la
décimale et les séparateurs de champ. Si vous travaillez avec un autre
format de données , ces paramètres peuvent tous deux être spécifiés
explicitement par l’utilisateur. Consultez l’aide de la fonction
read.csv() en tapant ?read.csv pour en savoir
plus. Il existe également la fonction read.delim() pour
lire des fichiers de données séparées par des tabulations. Il est
important de noter que toutes ces fonctions sont en fait des fonctions
wrapper pour la fonction principale read.table() avec
différents arguments. Par exemple, les données ci-dessus auraient
également pu être chargées en utilisant read.table() avec
l’argument de séparation (sep) égal à ","
selon le code suivant :
R
rna <- read.table(file = "data/rnaseq.csv",
sep = ",",
header = TRUE)
L’argument header (en-tête) doit être défini comme étant
TRUE pour pouvoir lire les en-têtes du fichier CSV, puisque
par défaut dans read.table(), l’argument
header défini comme étant FALSE.
Qu’est-ce qu’un data frame ?
Le data frame (tableau de données) est une structure de données de facto pour la plupart des données tabulaires et ce que nous utilisons pour calculer des statistiques et faire des graphiques.
Un data frame peut être créé à la main, mais le plus souvent celui-ci
est générés par les fonctions read.csv() ou
read.table(), c’est-à-dire lors de l’importation de
feuilles de calcul depuis votre disque dur (ou le web).
Le data frame représente les données sous la forme d’un tableau où
les colonnes sont des vecteurs qui ont tous la même longueur. Étant
donné que les colonnes sont des vecteurs (de classe
vector), chaque colonne doit contenir un seul type de
données (par exemple, des caractères, des entiers, des facteurs). Par
exemple, voici une figure représentant un data frame comprenant trois
vecteurs : un numérique, un caractère et un logique.

Nous pouvons le voir lors de l’inspection de la structure d’un
data frame avec la fonction str() :
R
str(arn)
OUTPUT
'data.frame': 32428 obs. of 19 variables:
$ gene : chr "Asl" "Apod" "Cyp2d22" "Klk6" ...
$ sample : chr "GSM2545336" "GSM2545336" "GSM2545336" "GSM2545336" ...
$ expression : int 1170 36194 4060 287 85 782 1619 288 43217 1071 ...
$ organism : chr "Mus musculus" "Mus musculus" "Mus musculus" "Mus musculus" ...
$ age : int 8 8 8 8 8 8 8 8 8 8 ...
$ sex : chr "Female" "Female" "Female" "Female" ...
$ infection : chr "InfluenzaA" "InfluenzaA" "InfluenzaA" "InfluenzaA" ...
$ strain : chr "C57BL/6" "C57BL/6" "C57BL/6" "C57BL/6" ...
$ time : int 8 8 8 8 8 8 8 8 8 8 ...
$ tissue : chr "Cerebellum" "Cerebellum" "Cerebellum" "Cerebellum" ...
$ mouse : int 14 14 14 14 14 14 14 14 14 14 ...
$ ENTREZID : int 109900 11815 56448 19144 80891 20528 97827 118454 18823 14696 ...
$ product : chr "argininosuccinate lyase, transcript variant X1" "apolipoprotein D, transcript variant 3" "cytochrome P450, family 2, subfamily d, polypeptide 22, transcript variant 2" "kallikrein related-peptidase 6, transcript variant 2" ...
$ ensembl_gene_id : chr "ENSMUSG00000025533" "ENSMUSG00000022548" "ENSMUSG00000061740" "ENSMUSG00000050063" ...
$ external_synonym : chr "2510006M18Rik" NA "2D22" "Bssp" ...
$ chromosome_name : chr "5" "16" "15" "7" ...
$ gene_biotype : chr "protein_coding" "protein_coding" "protein_coding" "protein_coding" ...
$ phenotype_description : chr "abnormal circulating amino acid level" "abnormal lipid homeostasis" "abnormal skin morphology" "abnormal cytokine level" ...
$ hsapiens_homolog_associated_gene_name: chr "ASL" "APOD" "CYP2D6" "KLK6" ...Inspection des objets data.frame
Nous avons déjà vu comment les fonctions head() et
str() peuvent être utiles pour vérifier le contenu et la
structure d’un data frame. Voici une liste non exhaustive de fonctions
pour avoir une idée du contenu ou de la structure des données.
Essayons-les !
Dimension :
-
dim(rna)- renvoie un vecteur avec le nombre de lignes comme premier élément et le nombre de colonnes comme deuxième élément (les dimensions de l’objet). -
nrow(rna)- renvoie le nombre de lignes. -
ncol(rna)- renvoie le nombre de colonnes.
Contenu :
-
head(rna)- affiche les 6 premières lignes. -
tail(rna)- affiche les 6 dernières lignes.
Noms :
-
names(rna)- renvoie les noms de colonnes (synonyme decolnames()pour les objetsdata.frame). -
rownames(rna)- renvoie les noms de lignes.
Résumé :
-
str(rna)- structure de l’objet et informations sur la classe , longueur et contenu de chaque colonne. -
summary(rna)- statistiques récapitulatives pour chaque colonne.
Remarque : la plupart de ces fonctions sont “génériques”,
c’est-à-dire qu’elles peuvent être utilisées sur d’autres types d’objets
en plus des objets data.frame.
Défi
Sur la base du résultat de str(rna), pouvez-vous
répondre aux questions suivantes ?
- Quelle est la classe de l’objet
rna? - Combien de lignes et combien de colonnes y a-t-il dans cet objet ?
- classe : data frame
- Nombre de lignes : 66465, Nombre de colonnes : 11
Indexation et création de sous-ensembles de data frames
Notre data frame « rna » comporte des lignes et des colonnes (il a 2 dimensions) ; si nous voulons en extraire des données spécifiques, nous devons spécifier les “coordonnées” que nous voulons. Les numéros de ligne viennent en premier, suivis des numéros de colonne. Cependant, notez qu’il y a différentes manières de spécifier ces coordonnées, conduisant à des résultats avec des classes différentes.
R
# premier élément de la première colonne du bloc de données (sous forme de vecteur)
rna[1, 1]
# premier élément de la 6ème colonne (sous forme de vecteur)
rna [1, 6]
# première colonne du bloc de données (sous forme de vecteur)
rna[, 1]
# première colonne du bloc de données (sous forme de data.frame )
rna[1]
# les trois premiers éléments de la 7ème colonne (en tant que vecteur)
rna[1:3, 7]
# la 3ème ligne de la trame de données (en tant que data.frame)
rna[3, ]
# équivalent à head_rna <- head(rna)
head_rna <- rna[1:6, ]
head_rna
: est une fonction spéciale qui crée des vecteurs
numériques d’entiers dans un ordre croissant ou décroissant. Testez
1:10 et 10:1 par exemple. Voir section @ref(sec:genvec) pour plus de détails.
Vous pouvez également exclure certains indices d’un data frame à
l’aide du signe “-” :
R
rna[, -1] ## La trame de données entière, sauf la première colonne
rna[-c(7:66465), ] ## Équivalent à head(rna)
L’on peut créer des sous-ensembles à partir des data frames en utilisant des indices (comme vu précédemment), mais aussi en appelant directement les noms de colonnes à extraire :
R
rna["gene"] # Result is a data.frame
rna[, "gene"] # Result is a vector
rna[["gene"]] # Result is a vector
rna$gene # Result is a vector
Dans RStudio, vous pouvez utiliser la fonctionnalité de saisie automatique pour obtenir les noms complets et corrects des colonnes.
Défi
Créez un
data.frame(rna_200) contenant uniquement les données de la ligne 200 du jeu de donnéesrna.Notez comment
nrow()vous a donné le nombre de lignes dans undata.frame?
Utilisez ce chiffre pour extraire uniquement la dernière ligne du data frame initial
rna.Comparez ceci avec la dernière ligne du data frame en utilisant
tail()pour s’assurer d’obtenir des résultats identiques.Extrayez à présent cette dernière ligne en utilisant
nrow()au lieu du numéro de ligne.Créez un nouveau data frame (
rna_last) à partir de cette dernière ligne.
Utilisez
nrow()pour extraire la ligne qui se trouve au milieu du data framerna. Stockez le contenu de cette ligne dans un objet nommérna_middle.Combinez
nrow()avec la notation-ci-dessus pour reproduire le comportement dehead(rna), en conservant uniquement les lignes 1 à 6 du data framerna.
R
## 1.
rna_200 <- rna[200, ]
## 2.
## Sauvegarde de `n_rows` pour améliorer la lisibilité et réduire la duplication
n_rows < - nrow(rna)
ERROR
Error: object 'n_rows' not foundR
rna_last <- rna[n_rows, ]
ERROR
Error: object 'n_rows' not foundR
## 3.
rna_middle <- rna[n_rows / 2, ]
ERROR
Error: object 'n_rows' not foundR
## 4 .
rna_head <- rna[-(7:n_rows), ]
ERROR
Error: object 'n_rows' not foundFacteurs
Les facteurs représentent des données catégorielles. Ils sont stockés sous forme d’entiers (integer) avec des étiquettes associées et ils peuvent être ordonnés ou non. Alors que les facteurs ressemblent (et se comportent souvent) comme des vecteurs de caractères, ils sont en réalité traités comme des vecteurs entiers par R. Vous devez donc être très prudent lorsque vous les traitez comme des chaînes.
Une fois créés, les facteurs ne peuvent contenir qu’un ensemble prédéfini de valeurs ou niveaux. Par défaut, R trie toujours les niveaux par ordre alphabétique. Par exemple, si vous avez un facteur à 2 niveaux :
R
sexe <- factor(c("mâle", "femelle", "femelle", "mâle", "femelle"))
R va assigner 1 au niveau "female" et
2 au niveau "male" (puisque f
vient avant m, même si le premier élément de ce vecteur est
"male"). Vous pouvez le vérifier en utilisant la fonction
levels() et vous pouvez trouver le nombre de niveaux en
utilisant nlevels() :
R
niveaux(sexe)
ERROR
Error in niveaux(sexe): could not find function "niveaux"R
nniveaux(sexe)
ERROR
Error in nniveaux(sexe): could not find function "nniveaux"Parfois, l’ordre des facteurs n’a pas d’importance, d’autres fois
vous pourriez vouloir spécifier l’ordre car il est pertinent (par
exemple, “faible”, “moyen”, “élevé”), il améliore votre visualisation,
ou il est requis par un type particulier d’analyse. Ici, une façon de
réorganiser nos niveaux dans le vecteur sex serait :
R
sex ## commande actuelle
ERROR
Error: object 'sex' not foundR
sex <- factor(sex,levels = c("male", "female"))
ERROR
Error: object 'sex' not foundR
sex ## après la nouvelle commande
ERROR
Error: object 'sex' not foundCes facteurs sont représentés par des entiers (ex: 1, 2, 3) dans la
mémoire de R mais ils sont plus informatifs que les entiers car les
facteurs se décrivent d’eux-mêmes : "female",
"male" est plus descriptif que 1,
2. Lequel est « male » ? Vous ne seriez pas en mesure de le
savoir uniquement à partir des données entières . Les facteurs, en
revanche, intègrent cette information. Ceci est particulièrement utile
lorsqu’il existe de nombreux niveaux (comme le biotype du gène dans
notre exemple d’ensemble de données).
Lorsque vos données sont stockées sous forme de facteur, vous pouvez
utiliser la fonction plot() pour obtenir un aperçu rapide
du nombre d’observations représenté par chaque niveau de facteur.
Regardons le nombre d’hommes et de femmes dans nos données.
R
intrigue (sexe)
ERROR
Error in intrigue(sexe): could not find function "intrigue"Conversion en chaîne de caractères
Un facteur peut être converti en vecteur caractère, vous pouvez
utiliser la fonction as.character(x).
R
as.personnage (sexe)
ERROR
Error in as.personnage(sexe): could not find function "as.personnage"Renommer les facteurs
Si l’on veut renommer ces facteurs, il suffit de changer ses niveaux
avec la fonction levels() :
R
niveaux(sexe)
ERROR
Error in niveaux(sexe): could not find function "niveaux"R
niveaux(sexe) <- c("M", "F")
ERROR
Error in niveaux(sexe) <- c("M", "F"): could not find function "niveaux<-"R
sexe
OUTPUT
[1] mâle femelle femelle mâle femelle
Levels: femelle mâleR
intrigue(sexe)
ERROR
Error in intrigue(sexe): could not find function "intrigue"Défi
- Renommez
FetMrespectivement enFemaleetMale.
R
niveaux(sexe)
ERROR
Error in niveaux(sexe): could not find function "niveaux"R
niveaux(sexe) <- c("Homme", "Femme")
ERROR
Error in niveaux(sexe) <- c("Homme", "Femme"): could not find function "niveaux<-"Défi
Nous avons vu comment les data frame sont créés avec
read.csv(), mais ils peuvent également être créés à la main
avec la fonction data.frame(). Il y a quelques erreurs dans
ce data.frame construit manuellement. Pouvez-vous les
repérer et les corriger ? N’hésitez pas à expérimenter !
- Les guillemets sont manquants autour des noms des animaux.
- Il manque une entrée dans la colonne
feel(probablement pour l’un des animaux à fourrure). - Il manque une virgule dans la colonne
weight.
Défi
Pouvez-vous prédire la classe de chacune des colonnes dans l’exemple suivant ?
Vérifiez vos suppositions en utilisant
str(country_climate) :
Sont-ils ce à quoi vous vous attendiez ? Pourquoi? Pourquoi pas?
Réessayez en ajoutant
stringsAsFactors = TRUEaprès la dernière variable lors de la création du data frame. Que se passe-t-il à présent ?stringsAsFactorspeut également être défini lors de la lecture de feuilles de calcul basées sur du texte dans R à l’aide deread.csv().
R
country_climate <- data.frame(
country = c("Canada", "Panama", "Afrique du Sud", "Australie"),
climat = c("froid", "chaud" , "tempéré", "chaud/tempéré"),
température = c(10, 30, 18, "15"),
hémisphère_nord = c(VRAI, VRAI, FAUX, "FAUX" ),
has_kangaroo = c(FALSE, FALSE, FALSE, 1)
)
R
country_climate <- data.frame(
country = c("Canada", "Panama", "Afrique du Sud", "Australie"),
climat = c("froid", "chaud" , "tempéré", "chaud/tempéré"),
température = c(10, 30, 18, "15"),
hémisphère_nord = c(VRAI, VRAI, FAUX, "FAUX" ),
has_kangaroo = c(FALSE, FALSE, FALSE, 1)
)
ERROR
Error: object 'VRAI' not foundR
str(country_climate)
ERROR
Error: object 'country_climate' not foundLa conversion automatique du type de données est parfois une bénédiction, parfois un désagrément. Sachez que cela existe, apprenez les règles et vérifiez que les données que vous importez dans R sont du bon type dans votre data frame. Sinon, utilisez-le à votre avantage pour détecter les erreurs qui auraient pu être introduites lors de la saisie des données (une lettre dans une colonne qui ne doit contenir que des chiffres par exemple).
Apprenez-en plus dans ce tutoriel RStudio
Matrices
Avant de continuer, maintenant que nous avons découvert les data
frames, récapitulons l’installation de packages et découvrons un nouveau
type de données, à savoir la classe matrix. Comme un objet
de classe data.frame, une matrice a deux dimensions, des
lignes et colonnes. La différence majeure est que toutes les cellules
d’une matrice doivent être du même type : « numérique », « caractère »,
« logique », … À cet égard, les matrices sont plus proches d’un vecteur
que d’un data frame.
Le constructeur par défaut d’une matrice est « matrix ». Le
remplissage de la matrice nécessite un vecteur de valeurs et de fixer le
nombre de lignes et/ou colonnes[^ncol]. Les valeurs sont
triées le long des colonnes, comme illustré ci-dessous.
R
m <- matrice (1:9, ncol = 3, nrow = 3)
ERROR
Error in matrice(1:9, ncol = 3, nrow = 3): could not find function "matrice"R
m
ERROR
Error: object 'm' not foundDéfi
À l’aide de la fonction installed.packages(), créez une
matrice caractère contenant les informations sur tous les packages
actuellement installés sur votre ordinateur. Explorez-la.
Il est souvent utile de créer de grandes matrices de données
aléatoires comme données de test. L’exercice ci-dessous vous demande de
créer une telle matrice avec des données aléatoires tirées d’une
distribution normale de moyenne 0 et d’écart type 1, ce qui peut être
fait avec la fonction rnorm().
Défi
Construire une matrice de dimension 1000 (nombre de lignes) par 3 (nombre de colonnes) de données normalement distribuées (moyenne 0, écart type 1).
R
set.seed(123)
m <- matrice(rnorm(3000), ncol = 3)
ERROR
Error in matrice(rnorm(3000), ncol = 3): could not find function "matrice"R
dim(m)
ERROR
Error: object 'm' not foundR
tête(m)
ERROR
Error in tête(m): could not find function "tête"Formatage des dates
L’un des problèmes les plus courants rencontrés par les nouveaux (et les plus expérimentés !) utilisateurs de R concerne la conversion des informations de date et d’heure en une variable appropriée et utilisable lors des analyses.
Remarque sur les dates dans les tableurs
Les dates dans les feuilles de calcul sont généralement stockées dans une seule colonne. Bien que cela semble la manière la plus naturelle d’enregistrer des dates, ce ne fait en réalité pas partie des bonnes pratiques. Un tableur affichera les dates d’une manière apparemment correcte (pour un observateur humain), mais la façon dont il gère et stocke réellement les dates peut être problématique. Il est souvent plus sûr de stocker les dates avec ANNÉE, MOIS et JOUR dans des colonnes séparées ou comme ANNÉE et JOUR DE L’ANNÉE dans des colonnes séparées.
Des tableurs tels que LibreOffice, Microsoft Excel, OpenOffice, Gnumeric, … ont des manières différentes (et souvent incompatibles) d’encoder les dates (même pour le même programme entre les versions et les systèmes d’exploitation). De plus, Excel peut transformer des éléments qui ne sont pas des dates en dates (@Zeeberg:2004), par exemple des noms ou des identifiants comme MAR1, DEC1, OCT4. Donc, si vous évitez de façon générale le format date, il est plus facile d’identifier ces problèmes.
La section Dates as data de la leçon Data Carpentry fournit des informations supplémentaires sur les pièges des dates avec des feuilles de calcul.
Nous allons utiliser la fonction ymd() du package
lubridate (qui appartient au
tidyverse ; en savoir plus [ici] (https://www.tidyverse.org/)). .
lubridate est automatiquement installé
lors de l’installation de tidyverse.
Lorsque vous chargez le tidyverse
(commande library(tidyverse)), les packages de base (les
packages utilisés dans la plupart des analyses de données) sont chargés.
lubridate n’appartient cependant pas aux
fonctionnalités de base de tidyverse, vous devez donc le charger
explicitement avec library(lubridate).
Commencez par charger le package requis :
R
bibliothèque("lubrifier")
ERROR
Error in bibliothèque("lubrifier"): could not find function "bibliothèque"ymd() prend un vecteur représentant l’année, le mois et
le jour, et le convertit en un vecteur Date.
Date est une classe de données reconnue par R comme étant
une date et peut être manipulée comme telle. L’argument requis par la
fonction est flexible, mais, à titre de bonnes pratiques, il s’agit d’un
vecteur de caractère au format “AAAA-MM-JJ”.
Créons un objet date et inspectons la structure :
R
ma_date <- ymd("2015-01-01")
ERROR
Error in ymd("2015-01-01"): could not find function "ymd"R
str(ma_date)
ERROR
Error: object 'ma_date' not foundCollons maintenant l’année, le mois et le jour séparément - nous obtenons le même résultat :
R
# sep indique le caractère à utiliser pour séparer chaque composant
my_date <- ymd(paste("2015", "1", "1", sep = "-"))
ERROR
Error in ymd(paste("2015", "1", "1", sep = "-")): could not find function "ymd"R
str(my_date )
ERROR
Error: object 'my_date' not foundFamiliarisons-nous maintenant avec un pipeline typique de manipulation de date . Le data frame ci-dessous a stocké des dates dans différentes colonnes « year », « month » et « jour ».
R
x <- data.frame(année = c(1996, 1992, 1987, 1986, 2000, 1990, 2002, 1994, 1997, 1985),
mois = c(2, 3, 3, 10, 1 , 8, 3, 4, 5, 5),
jour = c(24, 8, 1, 5, 8, 17, 13, 10, 11, 24),
valeur = c (4, 5, 1, 9, 3, 8, 10, 2, 6, 7))
x
OUTPUT
année mois jour valeur
1 1996 2 24 4
2 1992 3 8 5
3 1987 3 1 1
4 1986 10 5 9
5 2000 1 8 3
6 1990 8 17 8
7 2002 3 13 10
8 1994 4 10 2
9 1997 5 11 6
10 1985 5 24 7Nous appliquons maintenant cette fonction à l’ensemble du jeu de
données « x ». Nous créons d’abord un vecteur de caractères à partir des
colonnes year, month et day de
x en utilisant paste() :
R
coller(x$year, x$month, x$day, sep = "-")
ERROR
Error in coller(x$year, x$month, x$day, sep = "-"): could not find function "coller"Ce vecteur de caractères peut être utilisé comme argument pour
ymd() :
R
ymd(coller(x$year, x$month, x$day, sep = "-"))
ERROR
Error in ymd(coller(x$year, x$month, x$day, sep = "-")): could not find function "ymd"Le vecteur Date résultant peut être ajouté à
x en tant que nouvelle colonne appelée
date :
R
x$date <- ymd(paste(x$year, x$month, x$day, sep = "-"))
ERROR
Error in ymd(paste(x$year, x$month, x$day, sep = "-")): could not find function "ymd"R
str(x) # remarquez la nouvelle colonne, avec 'date' comme classe
OUTPUT
'data.frame': 10 obs. of 4 variables:
$ année : num 1996 1992 1987 1986 2000 ...
$ mois : num 2 3 3 10 1 8 3 4 5 5
$ jour : num 24 8 1 5 8 17 13 10 11 24
$ valeur: num 4 5 1 9 3 8 10 2 6 7Assurons-nous que tout a fonctionné correctement. Une façon
d’inspecter la nouvelle colonne est d’utiliser la fonction
summary() :
R
résumé(x$date)
ERROR
Error in résumé(x$date): could not find function "résumé"Notez que ymd() s’attend à avoir successivement l’année,
le mois et le jour. Si vous avez par exemple le jour, le mois et
l’année, vous aurez besoin de la fonction dmy().
R
dmy(coller(x$day, x$month, x$year, sep = "-"))
ERROR
Error in dmy(coller(x$day, x$month, x$year, sep = "-")): could not find function "dmy"lubdridate a de nombreuses fonctions pour gérer toutes
les variantes de date.
Résumé des objets R
Jusqu’à présent, nous avons vu plusieurs types d’objets R variant selon le nombre de dimensions et s’ils pouvaient stocker un ou plusieurs types de données :
-
vector: une dimension (ils ont une longueur), un seul type de données. -
matrix: deux dimensions, un seul type de données. -
data.frame: deux dimensions, un type par colonne.
Listes
Un type de données que nous n’avons pas encore vu, mais qu’il est
utile de connaître, et découle du résumé que nous venons de voir sont
des listes (classe list) :
-
list: une dimension, chaque élément peut être d’un type de données différent .
Ci-dessous, créons une liste contenant un vecteur de nombres, de caractères, une matrice, un data frame et une autre liste :
R
l <- list(1:10, ## numérique
lettres, ## caractère
installé.packages(), ## une matrice
voitures, ## un data.frame
liste(1, 2, 3)) ## une liste
ERROR
Error: object 'lettres' not foundR
longueur(l)
ERROR
Error in longueur(l): could not find function "longueur"R
str(l)
ERROR
Error: object 'l' not foundL’indiçage (i.e. la réalisation d’un sous-ensemble) de liste est
effectué en utilisant [] pour créer une nouvelle sous-liste
ou [[]] pour extraire un seul élément de cette liste (en
utilisant des indices ou des noms si la liste possède un attribut de
nom).
R
l[[1]] ## premier élément
ERROR
Error: object 'l' not foundR
l[1:2] ## une liste de longueur 2
ERROR
Error: object 'l' not foundR
l[1] ## une liste de longueur 1
ERROR
Error: object 'l' not foundExportation et sauvegarde de données tabulaires
Nous avons vu comment lire une feuille de calcul textuelle dans R à
l’aide de la famille de fonctions read.table. Pour exporter
un data.frame vers une feuille de calcul texte , nous
pouvons utiliser l’ensemble de fonctions write.table
(write.csv, write.delim, …). Ils ont tous pour
arguments la variable à exporter et le fichier vers lequel exporter. Par
exemple, pour exporter les données rna vers le fichier
my_rna.csv dans le répertoire data_output,
nous exécuterions :
R
write.csv(rna, file = "data_output/my_rna.csv")
Ce nouveau fichier csv peut maintenant être partagé avec d’autres
collaborateurs qui ne sont pas familiers avec R. Notez que même s’il y a
des virgules dans certains des champs dans le data.frame
(voir par exemple la colonne “product”), R entourera par défaut chaque
champ de texte avec des guillemets. Nous serons donc en mesure de le
lire à nouveau dans R correctement, malgré l’utilisation de virgules
comme séparateurs de colonnes.
Key Points
- Données tabulaires dans R
Content from Manipulation et analyse de données avec dplyr
Last updated on 2025-05-05 | Edit this page
Estimated time: 150 minutes
Overview
Questions
- Analyse de données en R à l’aide du méta-package (paquet) tidyverse
Objectives
- Décrire l’objectif des packages
dplyrettidyr. - Décrire plusieurs fonctions extrêmement utiles pour manipuler des données.
- Décrire le concept d’un tableau large et long, et comment remodeler un tableau d’un format à l’autre.
- Montrer comment joindre des tables.
Cet épisode est basé sur la leçon Data Analysis and Visualisation in R for Ecologists de Data Carpentries.
Manipulation des données avec dplyr et
tidyr
Extraire un sous-ensemble avec les crochets est pratique, mais peut être fastidieux et difficile à lire, en particulier pour les opérations compliquées.
Certains packages peuvent grandement faciliter notre tâche lorsque
nous manipulons des données. Les packages dans R sont essentiellement
des ensembles de fonctions supplémentaires qui vous permettent de faire
plus de choses. Les fonctions que nous avons utilisées jusqu’à présent,
comme str() ou data.frame(), sont intégrées à
R ; le chargement de packages donne accès à d’autres fonctions
spécifiques. Avant d’utiliser un package pour la première fois, vous
devez l’installer sur votre machine, puis vous devez l’importer à chaque
session R suivante lorsque vous en avez besoin.
Le package
dplyrfournit des outils puissants pour les tâches de manipulation de données. Il est conçu pour fonctionner directement avec des data frames, avec de nombreuses tâches de manipulation optimisées.Comme nous le verrons plus loin, nous souhaitons parfois qu’un data frame soit remodelé pour pouvoir effectuer des analyses spécifiques ou pour la visualisation. Le package
tidyrrésout ce problème courant de remodelage des données et fournit des outils pour une manipulation tidy des données, c’est-à-dire selon les principes du tidyverse.
Pour en savoir plus sur dplyr et
tidyr, vous voudrez consulter l’
aide-mémoire sur la transformation de données pratique avec ** et celui
sur .
- Le package
tidyverseest un “package parapluie” qui installe plusieurs packages utiles pour l’analyse des données qui fonctionnent bien ensemble, tels quetidyr, * *dplyr**,ggplot2,tibble, etc. Ces packages nous aident à travailler et à interagir avec les données. Ils nous permettent de faire beaucoup de choses avec nos données, comme en extraire des sous-ensembles, les transformer, les visualiser, etc.
Si vous avez configuré RStudio, vous devriez déjà avoir installé le package tidyverse. Vérifiez si vous l’avez en essayant de le charger depuis la librarie (library) :
R
## load the tidyverse packages, incl. dplyr
library("tidyverse")
Si vous recevez un message d’erreur
aucun package nommé 'tidyverse' n'est trouvé alors vous
n’avez pas installé le package pour cette version de R. Pour installer
le package tidyverse, tapez :
R
BiocManager::install("tidyverse")
Si vous avez dû installer le package
tidyverse, n’oubliez pas de le charger
dans cette session R en utilisant la commande library()
ci-dessus !
Chargement de données avec le tidyverse
Au lieu d’utiliser la fonction read.csv(), nous allons
lire nos données avec la fonction read_csv() (notez le
_ au lieu du .) du package
readr du tidyverse.
R
rna <- read_csv("data/rnaseq.csv")
## view the data
rna
OUTPUT
# A tibble: 32,428 × 19
gene sample expression organism age sex infection strain time tissue
<chr> <chr> <dbl> <chr> <dbl> <chr> <chr> <chr> <dbl> <chr>
1 Asl GSM254… 1170 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
2 Apod GSM254… 36194 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
3 Cyp2d22 GSM254… 4060 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
4 Klk6 GSM254… 287 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
5 Fcrls GSM254… 85 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
6 Slc2a4 GSM254… 782 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
7 Exd2 GSM254… 1619 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
8 Gjc2 GSM254… 288 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
9 Plp1 GSM254… 43217 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
10 Gnb4 GSM254… 1071 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
# ℹ 32,418 more rows
# ℹ 9 more variables: mouse <dbl>, ENTREZID <dbl>, product <chr>,
# ensembl_gene_id <chr>, external_synonym <chr>, chromosome_name <chr>,
# gene_biotype <chr>, phenotype_description <chr>,
# hsapiens_homolog_associated_gene_name <chr>Notez que la classe de la variable est désormais appelée “tibble”.
Les tibbles modifient certains comportements des objets data frame que nous avons introduits précédemment. La structure des données est très similaire à un data frame. Pour nos besoins, les seules différences sont les suivantes :
Il affiche le type de données de chaque colonne sous son nom. Notez que <
dbl> est un type de données défini pour contenir des valeurs numériques décimales.Il imprime uniquement les premières lignes de données et seulement les colonnes affichables à l’écran.
Nous allons maintenant apprendre les fonctions
dplyr les plus courantes :
-
select(): extraire des sous-ensembles de colonnes -
filter(): extraire des sous-ensembles de lignes -
mutate(): crée de nouvelles colonnes en utilisant les informations de colonnes préexistantes -
group_by()etsummarise(): créent des statistiques récapitulatives sur des données groupées -
arrange(): trier les résultats -
count(): compte des valeurs discrètes
Sélection de colonnes et filtrage de lignes
Pour sélectionner les colonnes d’un bloc de données, utilisez
select(). Le premier argument de cette fonction est le
dataframe (rna), et les arguments suivants reprennent les
colonnes à conserver.
R
select(rna, gene, sample, tissue, expression)
OUTPUT
# A tibble: 32,428 × 4
gene sample tissue expression
<chr> <chr> <chr> <dbl>
1 Asl GSM2545336 Cerebellum 1170
2 Apod GSM2545336 Cerebellum 36194
3 Cyp2d22 GSM2545336 Cerebellum 4060
4 Klk6 GSM2545336 Cerebellum 287
5 Fcrls GSM2545336 Cerebellum 85
6 Slc2a4 GSM2545336 Cerebellum 782
7 Exd2 GSM2545336 Cerebellum 1619
8 Gjc2 GSM2545336 Cerebellum 288
9 Plp1 GSM2545336 Cerebellum 43217
10 Gnb4 GSM2545336 Cerebellum 1071
# ℹ 32,418 more rowsPour sélectionner toutes les colonnes sauf certaines, mettez un “-” devant la variable à exclure.
R
select(rna, -tissue, -organism)
OUTPUT
# A tibble: 32,428 × 17
gene sample expression age sex infection strain time mouse ENTREZID
<chr> <chr> <dbl> <dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl>
1 Asl GSM2545… 1170 8 Fema… Influenz… C57BL… 8 14 109900
2 Apod GSM2545… 36194 8 Fema… Influenz… C57BL… 8 14 11815
3 Cyp2d22 GSM2545… 4060 8 Fema… Influenz… C57BL… 8 14 56448
4 Klk6 GSM2545… 287 8 Fema… Influenz… C57BL… 8 14 19144
5 Fcrls GSM2545… 85 8 Fema… Influenz… C57BL… 8 14 80891
6 Slc2a4 GSM2545… 782 8 Fema… Influenz… C57BL… 8 14 20528
7 Exd2 GSM2545… 1619 8 Fema… Influenz… C57BL… 8 14 97827
8 Gjc2 GSM2545… 288 8 Fema… Influenz… C57BL… 8 14 118454
9 Plp1 GSM2545… 43217 8 Fema… Influenz… C57BL… 8 14 18823
10 Gnb4 GSM2545… 1071 8 Fema… Influenz… C57BL… 8 14 14696
# ℹ 32,418 more rows
# ℹ 7 more variables: product <chr>, ensembl_gene_id <chr>,
# external_synonym <chr>, chromosome_name <chr>, gene_biotype <chr>,
# phenotype_description <chr>, hsapiens_homolog_associated_gene_name <chr>Cela sélectionnera toutes les variables de rna sauf
tissue et organism.
Pour choisir des lignes en fonction d’un critère spécifique, utilisez
filter() :
R
filter(rna, sex == "Male")
OUTPUT
# A tibble: 14,740 × 19
gene sample expression organism age sex infection strain time tissue
<chr> <chr> <dbl> <chr> <dbl> <chr> <chr> <chr> <dbl> <chr>
1 Asl GSM254… 626 Mus mus… 8 Male Influenz… C57BL… 4 Cereb…
2 Apod GSM254… 13021 Mus mus… 8 Male Influenz… C57BL… 4 Cereb…
3 Cyp2d22 GSM254… 2171 Mus mus… 8 Male Influenz… C57BL… 4 Cereb…
4 Klk6 GSM254… 448 Mus mus… 8 Male Influenz… C57BL… 4 Cereb…
5 Fcrls GSM254… 180 Mus mus… 8 Male Influenz… C57BL… 4 Cereb…
6 Slc2a4 GSM254… 313 Mus mus… 8 Male Influenz… C57BL… 4 Cereb…
7 Exd2 GSM254… 2366 Mus mus… 8 Male Influenz… C57BL… 4 Cereb…
8 Gjc2 GSM254… 310 Mus mus… 8 Male Influenz… C57BL… 4 Cereb…
9 Plp1 GSM254… 53126 Mus mus… 8 Male Influenz… C57BL… 4 Cereb…
10 Gnb4 GSM254… 1355 Mus mus… 8 Male Influenz… C57BL… 4 Cereb…
# ℹ 14,730 more rows
# ℹ 9 more variables: mouse <dbl>, ENTREZID <dbl>, product <chr>,
# ensembl_gene_id <chr>, external_synonym <chr>, chromosome_name <chr>,
# gene_biotype <chr>, phenotype_description <chr>,
# hsapiens_homolog_associated_gene_name <chr>R
filter(rna, sex == "Male" & infection == "NonInfected")
OUTPUT
# A tibble: 4,422 × 19
gene sample expression organism age sex infection strain time tissue
<chr> <chr> <dbl> <chr> <dbl> <chr> <chr> <chr> <dbl> <chr>
1 Asl GSM254… 535 Mus mus… 8 Male NonInfec… C57BL… 0 Cereb…
2 Apod GSM254… 13668 Mus mus… 8 Male NonInfec… C57BL… 0 Cereb…
3 Cyp2d22 GSM254… 2008 Mus mus… 8 Male NonInfec… C57BL… 0 Cereb…
4 Klk6 GSM254… 1101 Mus mus… 8 Male NonInfec… C57BL… 0 Cereb…
5 Fcrls GSM254… 375 Mus mus… 8 Male NonInfec… C57BL… 0 Cereb…
6 Slc2a4 GSM254… 249 Mus mus… 8 Male NonInfec… C57BL… 0 Cereb…
7 Exd2 GSM254… 3126 Mus mus… 8 Male NonInfec… C57BL… 0 Cereb…
8 Gjc2 GSM254… 791 Mus mus… 8 Male NonInfec… C57BL… 0 Cereb…
9 Plp1 GSM254… 98658 Mus mus… 8 Male NonInfec… C57BL… 0 Cereb…
10 Gnb4 GSM254… 2437 Mus mus… 8 Male NonInfec… C57BL… 0 Cereb…
# ℹ 4,412 more rows
# ℹ 9 more variables: mouse <dbl>, ENTREZID <dbl>, product <chr>,
# ensembl_gene_id <chr>, external_synonym <chr>, chromosome_name <chr>,
# gene_biotype <chr>, phenotype_description <chr>,
# hsapiens_homolog_associated_gene_name <chr>Imaginons maintenant que nous nous intéressions aux homologues
humains des gènes de souris analysés dans ces données. Ces informations
se trouvent dans la dernière colonne du tibble rna, nommée
hsapiens_homolog_associated_gene_name. Pour le visualiser
facilement, nous allons créer un nouveau tableau contenant uniquement
les 2 colonnes gene et
hsapiens_homolog_associated_gene_name.
R
genes <- select(rna, gene, hsapiens_homolog_associated_gene_name)
genes
OUTPUT
# A tibble: 32,428 × 2
gene hsapiens_homolog_associated_gene_name
<chr> <chr>
1 Asl ASL
2 Apod APOD
3 Cyp2d22 CYP2D6
4 Klk6 KLK6
5 Fcrls FCRL2
6 Slc2a4 SLC2A4
7 Exd2 EXD2
8 Gjc2 GJC2
9 Plp1 PLP1
10 Gnb4 GNB4
# ℹ 32,418 more rowsCertains gènes de souris n’ont pas d’homologues humains. Ceux-ci
peuvent être récupérés en utilisant filter() et la fonction
is.na(), qui détermine si quelque chose est un
NA.
R
filter(genes, is.na(hsapiens_homolog_associated_gene_name))
OUTPUT
# A tibble: 4,290 × 2
gene hsapiens_homolog_associated_gene_name
<chr> <chr>
1 Prodh <NA>
2 Tssk5 <NA>
3 Vmn2r1 <NA>
4 Gm10654 <NA>
5 Hexa <NA>
6 Sult1a1 <NA>
7 Gm6277 <NA>
8 Tmem198b <NA>
9 Adam1a <NA>
10 Ebp <NA>
# ℹ 4,280 more rowsSi on veut conserver uniquement les gènes de souris qui ont un
homologue humain, on peut utiliser “!” qui inverse le résultat logique
pour demander chaque ligne où
hsapiens\_homolog\_associated\_gene\_name n’est
pas un NA.
R
filter(genes, !is.na(hsapiens_homolog_associated_gene_name))
OUTPUT
# A tibble: 28,138 × 2
gene hsapiens_homolog_associated_gene_name
<chr> <chr>
1 Asl ASL
2 Apod APOD
3 Cyp2d22 CYP2D6
4 Klk6 KLK6
5 Fcrls FCRL2
6 Slc2a4 SLC2A4
7 Exd2 EXD2
8 Gjc2 GJC2
9 Plp1 PLP1
10 Gnb4 GNB4
# ℹ 28,128 more rowsPipes
Comment faire si vous souhaitez sélectionner et filtrer en même temps ? Il existe trois façons de procéder : utiliser des étapes intermédiaires, des fonctions imbriquées ou des pipes.
Avec des étapes intermédiaires, vous créez un data frame temporaire et l’utilisez comme entrée de la fonction suivante, comme ceci :
R
rna2 <- filter(rna, sex == "Male")
rna3 <- select(rna2, gene, sample, tissue, expression)
rna3
OUTPUT
# A tibble: 14,740 × 4
gene sample tissue expression
<chr> <chr> <chr> <dbl>
1 Asl GSM2545340 Cerebellum 626
2 Apod GSM2545340 Cerebellum 13021
3 Cyp2d22 GSM2545340 Cerebellum 2171
4 Klk6 GSM2545340 Cerebellum 448
5 Fcrls GSM2545340 Cerebellum 180
6 Slc2a4 GSM2545340 Cerebellum 313
7 Exd2 GSM2545340 Cerebellum 2366
8 Gjc2 GSM2545340 Cerebellum 310
9 Plp1 GSM2545340 Cerebellum 53126
10 Gnb4 GSM2545340 Cerebellum 1355
# ℹ 14,730 more rowsCeci est lisible, mais peut encombrer votre espace de travail avec de nombreux objets intermédiaires que vous devez nommer individuellement. Avec beaucoup d’étapes, cette approche devient difficile à suivre.
Vous pouvez également imbriquer des fonctions (c’est-à-dire une fonction dans une autre), comme ceci :
R
rna3 <- select(filter(rna, sex == "Male"), gene, sample, tissue, expression)
rna3
OUTPUT
# A tibble: 14,740 × 4
gene sample tissue expression
<chr> <chr> <chr> <dbl>
1 Asl GSM2545340 Cerebellum 626
2 Apod GSM2545340 Cerebellum 13021
3 Cyp2d22 GSM2545340 Cerebellum 2171
4 Klk6 GSM2545340 Cerebellum 448
5 Fcrls GSM2545340 Cerebellum 180
6 Slc2a4 GSM2545340 Cerebellum 313
7 Exd2 GSM2545340 Cerebellum 2366
8 Gjc2 GSM2545340 Cerebellum 310
9 Plp1 GSM2545340 Cerebellum 53126
10 Gnb4 GSM2545340 Cerebellum 1355
# ℹ 14,730 more rowsCette approche est pratique, mais peut être difficile à lire si trop de fonctions sont imbriquées, car R évalue l’expression de l’intérieur vers l’extérieur (dans ce cas, filtrer, puis sélectionner).
La dernière option, le pipe, est un ajout plus récent à R. Un pipe permet de prendre la sortie d’une fonction et de la passer directement à la suivante. Cette approche est utile lorsque vous devez faire beaucoup d’opérations sur le même jeu de données.
Les pipes dans R s’écrivent à %>% (mis à
disposition via le package magrittr) ou |>
(via R). Si vous utilisez RStudio, vous pouvez afficher un pipe
avec Ctrl + Shift + M sur un PC ou
Cmd + Shift + M sur un Mac.
Dans le code ci-dessus, nous utilisons le pipe pour passer
les données rna d’abord dans filter() pour
conserver les lignes où sex est égal à "Male",
puis dans select() pour conserver uniquement les colonnes
gene, sample, tissue et
expression.
Le pipe %>% prend l’objet à sa gauche et le
passe directement en tant que premier argument à la fonction à sa
droite. Nous n’avons donc plus besoin d’inclure explicitement les
données comme un argument pour les fonctions filter() et
select().
R
rna |>
filter(sex == "Male") |>
select(gene, sample, tissue, expression)
OUTPUT
# A tibble: 14,740 × 4
gene sample tissue expression
<chr> <chr> <chr> <dbl>
1 Asl GSM2545340 Cerebellum 626
2 Apod GSM2545340 Cerebellum 13021
3 Cyp2d22 GSM2545340 Cerebellum 2171
4 Klk6 GSM2545340 Cerebellum 448
5 Fcrls GSM2545340 Cerebellum 180
6 Slc2a4 GSM2545340 Cerebellum 313
7 Exd2 GSM2545340 Cerebellum 2366
8 Gjc2 GSM2545340 Cerebellum 310
9 Plp1 GSM2545340 Cerebellum 53126
10 Gnb4 GSM2545340 Cerebellum 1355
# ℹ 14,730 more rowsCertains trouveront peut-être utile de lire le pipe comme le
mot “ensuite”. Par exemple, dans l’exemple ci-dessus, nous avons pris le
data frame rna, ensuite nous avons
filtré pour les lignes avec sex == "Male",
ensuite nous avons sélectionné les colonnes gene
sample, tissue, et
expression.
Les fonctions de dplyr sont
relativement simples, mais en les combinant avec le pipe, nous
pouvons accomplir des manipulations plus complexes.
Si nous voulons créer un nouvel objet avec cette version plus petite des données, il suffit de lui attribuer un nouveau nom :
R
rna3 <- rna |>
filter(sex == "Male") |>
select(gene, sample, tissue, expression)
rna3
OUTPUT
# A tibble: 14,740 × 4
gene sample tissue expression
<chr> <chr> <chr> <dbl>
1 Asl GSM2545340 Cerebellum 626
2 Apod GSM2545340 Cerebellum 13021
3 Cyp2d22 GSM2545340 Cerebellum 2171
4 Klk6 GSM2545340 Cerebellum 448
5 Fcrls GSM2545340 Cerebellum 180
6 Slc2a4 GSM2545340 Cerebellum 313
7 Exd2 GSM2545340 Cerebellum 2366
8 Gjc2 GSM2545340 Cerebellum 310
9 Plp1 GSM2545340 Cerebellum 53126
10 Gnb4 GSM2545340 Cerebellum 1355
# ℹ 14,730 more rowsDéfi:
À l’aide de pipes, extraire un sous-ensemble de
rna pour ne conserver que les observations des souris
femelles au temps 0, où le gène a une expression supérieure à 50000, et
ne conservez que les colonnes gene, sample,
time, expression et age.
R
rna |>
filter(expression > 50000,
sex == "Female",
time == 0 ) |>
select(gene, sample, time, expression, age)
OUTPUT
# A tibble: 9 × 5
gene sample time expression age
<chr> <chr> <dbl> <dbl> <dbl>
1 Plp1 GSM2545337 0 101241 8
2 Atp1b1 GSM2545337 0 53260 8
3 Plp1 GSM2545338 0 96534 8
4 Atp1b1 GSM2545338 0 50614 8
5 Plp1 GSM2545348 0 102790 8
6 Atp1b1 GSM2545348 0 59544 8
7 Plp1 GSM2545353 0 71237 8
8 Glul GSM2545353 0 52451 8
9 Atp1b1 GSM2545353 0 61451 8Mutate
Vous souhaiterez fréquemment créer de nouvelles colonnes basées sur
les valeurs des colonnes existantes, par exemple pour effectuer des
conversions d’unités ou pour trouver le rapport des valeurs dans deux
colonnes . Pour cela, nous utiliserons la fonction
mutate().
Pour créer une nouvelle colonne de temps en heures :
R
rna |>
mutate(time_hours = time * 24) |>
select(time, time_hours)
OUTPUT
# A tibble: 32,428 × 2
time time_hours
<dbl> <dbl>
1 8 192
2 8 192
3 8 192
4 8 192
5 8 192
6 8 192
7 8 192
8 8 192
9 8 192
10 8 192
# ℹ 32,418 more rowsVous pouvez également créer une deuxième nouvelle colonne basée sur
la première nouvelle colonne dans le même appel de
mutate() :
R
rna |>
mutate(time_hours = time * 24,
time_mn = time_hours * 60) |>
select(time, time_hours, time_mn)
OUTPUT
# A tibble: 32,428 × 3
time time_hours time_mn
<dbl> <dbl> <dbl>
1 8 192 11520
2 8 192 11520
3 8 192 11520
4 8 192 11520
5 8 192 11520
6 8 192 11520
7 8 192 11520
8 8 192 11520
9 8 192 11520
10 8 192 11520
# ℹ 32,418 more rowsDéfi
Créez un nouveau data frane à partir de rna qui répond
aux critères suivants : contient uniquement les colonnes
gene, chromosome_name,
phenotype_description, sample et
expression. Les valeurs d’expression doivent être
transformées en log. Ce data frame doit contenir uniquement des gènes
situés sur les chromosomes sexuels, ayant bien un
phenotype \_description, et une expression en log
supérieure à 5.
Astuce : réfléchissez bien à la façon dont les commandes doivent être ordonnées !
R
rna |>
mutate(expression = log(expression)) |>
select(gene, chromosome_name, phenotype_description, sample, expression) |>
filter(chromosome_name == "X" | chromosome_name == "Y") |>
filter(!is.na(phenotype_description)) |>
filter(expression > 5)
OUTPUT
# A tibble: 649 × 5
gene chromosome_name phenotype_description sample expression
<chr> <chr> <chr> <chr> <dbl>
1 Plp1 X abnormal CNS glial cell morphology GSM25… 10.7
2 Slc7a3 X decreased body length GSM25… 5.46
3 Plxnb3 X abnormal coat appearance GSM25… 6.58
4 Rbm3 X abnormal liver morphology GSM25… 9.32
5 Cfp X abnormal cardiovascular system phys… GSM25… 6.18
6 Ebp X abnormal embryonic erythrocyte morp… GSM25… 6.68
7 Cd99l2 X abnormal cellular extravasation GSM25… 8.04
8 Piga X abnormal brain development GSM25… 6.06
9 Pim2 X decreased T cell proliferation GSM25… 7.11
10 Itm2a X no abnormal phenotype detected GSM25… 7.48
# ℹ 639 more rowsAnalyse de données “split-apply-combine”
De nombreuses tâches d’analyse de données peuvent être abordées à
l’aide du paradigme split-apply-combine : divisez les données
en groupes, appliquez une analyse à chaque groupe, puis combinez les
résultats. dplyr rend cela très facile
grâce à l’utilisation de la fonction group_by().
R
rna |>
group_by(gene)
OUTPUT
# A tibble: 32,428 × 19
# Groups: gene [1,474]
gene sample expression organism age sex infection strain time tissue
<chr> <chr> <dbl> <chr> <dbl> <chr> <chr> <chr> <dbl> <chr>
1 Asl GSM254… 1170 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
2 Apod GSM254… 36194 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
3 Cyp2d22 GSM254… 4060 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
4 Klk6 GSM254… 287 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
5 Fcrls GSM254… 85 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
6 Slc2a4 GSM254… 782 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
7 Exd2 GSM254… 1619 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
8 Gjc2 GSM254… 288 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
9 Plp1 GSM254… 43217 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
10 Gnb4 GSM254… 1071 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
# ℹ 32,418 more rows
# ℹ 9 more variables: mouse <dbl>, ENTREZID <dbl>, product <chr>,
# ensembl_gene_id <chr>, external_synonym <chr>, chromosome_name <chr>,
# gene_biotype <chr>, phenotype_description <chr>,
# hsapiens_homolog_associated_gene_name <chr>La fonction group_by() n’effectue aucun traitement de
données, elle regroupe simplement les données en sous-ensembles : dans
l’exemple ci-dessus, notre tibble initial de 32428
observations est divisé en 1474 groupes selon la variable
gene.
On pourrait de même décider de regrouper le tibble par échantillons :
R
rna |>
group_by(sample)
OUTPUT
# A tibble: 32,428 × 19
# Groups: sample [22]
gene sample expression organism age sex infection strain time tissue
<chr> <chr> <dbl> <chr> <dbl> <chr> <chr> <chr> <dbl> <chr>
1 Asl GSM254… 1170 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
2 Apod GSM254… 36194 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
3 Cyp2d22 GSM254… 4060 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
4 Klk6 GSM254… 287 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
5 Fcrls GSM254… 85 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
6 Slc2a4 GSM254… 782 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
7 Exd2 GSM254… 1619 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
8 Gjc2 GSM254… 288 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
9 Plp1 GSM254… 43217 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
10 Gnb4 GSM254… 1071 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
# ℹ 32,418 more rows
# ℹ 9 more variables: mouse <dbl>, ENTREZID <dbl>, product <chr>,
# ensembl_gene_id <chr>, external_synonym <chr>, chromosome_name <chr>,
# gene_biotype <chr>, phenotype_description <chr>,
# hsapiens_homolog_associated_gene_name <chr>Ici, notre tibble initial de 32428 observations est
divisé en 22 groupes selon la variable sample.
Une fois les données regroupées, les opérations qui suivent sont appliquées sur chaque groupe indépendamment.
La fonction summarise()
group_by() est souvent utilisé avec
summarise(), qui réduit chaque groupe en un résumé d’une
seule ligne.
group_by() prend comme arguments les noms de colonnes
qui contiennent les variables catégorielles pour
lesquelles vous souhaitez calculer les statistiques récapitulatives.
Donc, pour calculer l’expression moyenne par gène :
R
rna |>
group_by(gene) |>
summarise(mean_expression = mean(expression))
OUTPUT
# A tibble: 1,474 × 2
gene mean_expression
<chr> <dbl>
1 AI504432 1053.
2 AW046200 131.
3 AW551984 295.
4 Aamp 4751.
5 Abca12 4.55
6 Abcc8 2498.
7 Abhd14a 525.
8 Abi2 4909.
9 Abi3bp 1002.
10 Abl2 2124.
# ℹ 1,464 more rowsNous pourrions également vouloir calculer les niveaux d’expression moyens de tous les gènes dans chaque échantillon :
R
rna |>
group_by(sample) |>
summarise(mean_expression = mean(expression))
OUTPUT
# A tibble: 22 × 2
sample mean_expression
<chr> <dbl>
1 GSM2545336 2062.
2 GSM2545337 1766.
3 GSM2545338 1668.
4 GSM2545339 1696.
5 GSM2545340 1682.
6 GSM2545341 1638.
7 GSM2545342 1594.
8 GSM2545343 2107.
9 GSM2545344 1712.
10 GSM2545345 1700.
# ℹ 12 more rowsOn peut également regrouper les observations par plusieurs colonnes :
R
rna |>
group_by(gene, infection, time) |>
summarise(mean_expression = mean(expression))
OUTPUT
`summarise()` has grouped output by 'gene', 'infection'. You can override using
the `.groups` argument.OUTPUT
# A tibble: 4,422 × 4
# Groups: gene, infection [2,948]
gene infection time mean_expression
<chr> <chr> <dbl> <dbl>
1 AI504432 InfluenzaA 4 1104.
2 AI504432 InfluenzaA 8 1014
3 AI504432 NonInfected 0 1034.
4 AW046200 InfluenzaA 4 152.
5 AW046200 InfluenzaA 8 81
6 AW046200 NonInfected 0 155.
7 AW551984 InfluenzaA 4 302.
8 AW551984 InfluenzaA 8 342.
9 AW551984 NonInfected 0 238
10 Aamp InfluenzaA 4 4870
# ℹ 4,412 more rowsUne fois les données regroupées, vous pouvez également résumer plusieurs variables en même temps (et pas nécessairement sur la même variable). Par exemple, nous pourrions ajouter une colonne indiquant l’expression médiane par gène et par condition :
R
rna |>
group_by(gene, infection, time) |>
summarise(mean_expression = mean(expression),
median_expression = median(expression))
OUTPUT
`summarise()` has grouped output by 'gene', 'infection'. You can override using
the `.groups` argument.OUTPUT
# A tibble: 4,422 × 5
# Groups: gene, infection [2,948]
gene infection time mean_expression median_expression
<chr> <chr> <dbl> <dbl> <dbl>
1 AI504432 InfluenzaA 4 1104. 1094.
2 AI504432 InfluenzaA 8 1014 985
3 AI504432 NonInfected 0 1034. 1016
4 AW046200 InfluenzaA 4 152. 144.
5 AW046200 InfluenzaA 8 81 82
6 AW046200 NonInfected 0 155. 163
7 AW551984 InfluenzaA 4 302. 245
8 AW551984 InfluenzaA 8 342. 287
9 AW551984 NonInfected 0 238 265
10 Aamp InfluenzaA 4 4870 4708
# ℹ 4,412 more rowsDéfi
Calculer le niveau d’expression moyen du gène “Dok3” pour chaque temps.
R
rna |>
filter(gene == "Dok3") |>
group_by(time) |>
summarise(mean = mean(expression))
OUTPUT
# A tibble: 3 × 2
time mean
<dbl> <dbl>
1 0 169
2 4 156.
3 8 61 Count
Lorsque nous travaillons avec des données, nous souhaitons souvent
connaître le nombre d’observations trouvées pour chaque facteur ou
combinaison de facteurs. Pour cette tâche,
dplyr fournit la fonction
count(). Par exemple, si nous voulons compter le nombre
d’observations pour chaque échantillon infecté et non infecté :
R
rna |>
count(infection)
OUTPUT
# A tibble: 2 × 2
infection n
<chr> <int>
1 InfluenzaA 22110
2 NonInfected 10318La fonction count() est un raccourci pour quelque chose
que nous avons déjà vu : regrouper par une variable et la résumer en
comptant le nombre d’observations dans ce groupe. En d’autres termes,
rna %>% count(infection) équivaut à :
R
rna |>
group_by(infection) |>
summarise(n = n())
OUTPUT
# A tibble: 2 × 2
infection n
<chr> <int>
1 InfluenzaA 22110
2 NonInfected 10318L’exemple précédent montre l’utilisation de count() pour
compter le nombre de lignes/observations pour un facteur
(c’est-à-dire infection). Pour compter une combinaison
de facteurs, telle que infection et time,
il suffit de spécifier les deux facteurs comme arguments de
count() :
R
rna |>
count(infection, time)
OUTPUT
# A tibble: 3 × 3
infection time n
<chr> <dbl> <int>
1 InfluenzaA 4 11792
2 InfluenzaA 8 10318
3 NonInfected 0 10318ce qui équivaut à ceci :
R
rna |>
group_by(infection, time) |>
summarise(n = n())
OUTPUT
`summarise()` has grouped output by 'infection'. You can override using the
`.groups` argument.OUTPUT
# A tibble: 3 × 3
# Groups: infection [2]
infection time n
<chr> <dbl> <int>
1 InfluenzaA 4 11792
2 InfluenzaA 8 10318
3 NonInfected 0 10318Il est parfois utile de trier le résultat pour faciliter les
comparaisons. Nous pouvons utiliser arrange() pour trier le
tableau. Par exemple, nous pourrions vouloir organiser le tableau
ci-dessus par temps :
R
rna |>
count(infection, time) |>
arrange(time)
OUTPUT
# A tibble: 3 × 3
infection time n
<chr> <dbl> <int>
1 NonInfected 0 10318
2 InfluenzaA 4 11792
3 InfluenzaA 8 10318ou par comptage :
R
rna |>
count(infection, time) |>
arrange(n)
OUTPUT
# A tibble: 3 × 3
infection time n
<chr> <dbl> <int>
1 InfluenzaA 8 10318
2 NonInfected 0 10318
3 InfluenzaA 4 11792Pour trier par ordre décroissant, nous devons ajouter la fonction
desc() :
R
rna |>
count(infection, time) |>
arrange(desc(n))
OUTPUT
# A tibble: 3 × 3
infection time n
<chr> <dbl> <int>
1 InfluenzaA 4 11792
2 InfluenzaA 8 10318
3 NonInfected 0 10318Défi
- Combien de gènes ont été analysés dans chaque échantillon ?
- Utilisez
group_by()etsummarise()pour évaluer la profondeur de séquençage (la somme de tous les comptes) dans chaque échantillon. Quel échantillon a la profondeur de séquençage la plus élevée ? - Choisissez un échantillon et évaluez le nombre de gènes par biotype.
- Identifiez les gènes associés à la description du phénotype “abnormal DNA methylation” et calculez leur expression moyenne (en log) au temps 0, 4 et 8.
R
## 1.
rna |>
count(sample)
OUTPUT
# A tibble: 22 × 2
sample n
<chr> <int>
1 GSM2545336 1474
2 GSM2545337 1474
3 GSM2545338 1474
4 GSM2545339 1474
5 GSM2545340 1474
6 GSM2545341 1474
7 GSM2545342 1474
8 GSM2545343 1474
9 GSM2545344 1474
10 GSM2545345 1474
# ℹ 12 more rowsR
## 2.
rna |>
group_by(sample) |>
summarise(seq_depth = sum(expression)) |>
arrange(desc(seq_depth))
OUTPUT
# A tibble: 22 × 2
sample seq_depth
<chr> <dbl>
1 GSM2545350 3255566
2 GSM2545352 3216163
3 GSM2545343 3105652
4 GSM2545336 3039671
5 GSM2545380 3036098
6 GSM2545353 2953249
7 GSM2545348 2913678
8 GSM2545362 2913517
9 GSM2545351 2782464
10 GSM2545349 2758006
# ℹ 12 more rowsR
## 3.
rna |>
filter(sample == "GSM2545336") |>
count(gene_biotype) |>
arrange(desc(n))
OUTPUT
# A tibble: 13 × 2
gene_biotype n
<chr> <int>
1 protein_coding 1321
2 lncRNA 69
3 processed_pseudogene 59
4 miRNA 7
5 snoRNA 5
6 TEC 4
7 polymorphic_pseudogene 2
8 unprocessed_pseudogene 2
9 IG_C_gene 1
10 scaRNA 1
11 transcribed_processed_pseudogene 1
12 transcribed_unitary_pseudogene 1
13 transcribed_unprocessed_pseudogene 1R
## 4.
rna |>
filter(phenotype_description == "abnormal DNA methylation") |>
group_by(gene, time) |>
summarise(mean_expression = mean(log(expression))) |>
arrange()
OUTPUT
`summarise()` has grouped output by 'gene'. You can override using the
`.groups` argument.OUTPUT
# A tibble: 6 × 3
# Groups: gene [2]
gene time mean_expression
<chr> <dbl> <dbl>
1 Xist 0 6.95
2 Xist 4 6.34
3 Xist 8 7.13
4 Zdbf2 0 6.27
5 Zdbf2 4 6.27
6 Zdbf2 8 6.19Remodeler les données
Dans le tibble rna, les lignes contiennent des valeurs
d’expression qui sont associées à une combinaison de 2 autres variables
: gene et sample.
Toutes les autres colonnes correspondent à des variables décrivant soit l’échantillon (organisme, âge, sexe, …) soit le gène (‘gene_biotype’, ‘ENTREZ_ID’, ‘product’, …). Les variables qui ne changent pas avec les gènes ou avec les échantillons auront la même valeur dans toutes les lignes.
R
rna |>
arrange(gene)
OUTPUT
# A tibble: 32,428 × 19
gene sample expression organism age sex infection strain time tissue
<chr> <chr> <dbl> <chr> <dbl> <chr> <chr> <chr> <dbl> <chr>
1 AI504432 GSM25… 1230 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
2 AI504432 GSM25… 1085 Mus mus… 8 Fema… NonInfec… C57BL… 0 Cereb…
3 AI504432 GSM25… 969 Mus mus… 8 Fema… NonInfec… C57BL… 0 Cereb…
4 AI504432 GSM25… 1284 Mus mus… 8 Fema… Influenz… C57BL… 4 Cereb…
5 AI504432 GSM25… 966 Mus mus… 8 Male Influenz… C57BL… 4 Cereb…
6 AI504432 GSM25… 918 Mus mus… 8 Male Influenz… C57BL… 8 Cereb…
7 AI504432 GSM25… 985 Mus mus… 8 Fema… Influenz… C57BL… 8 Cereb…
8 AI504432 GSM25… 972 Mus mus… 8 Male NonInfec… C57BL… 0 Cereb…
9 AI504432 GSM25… 1000 Mus mus… 8 Fema… Influenz… C57BL… 4 Cereb…
10 AI504432 GSM25… 816 Mus mus… 8 Male Influenz… C57BL… 4 Cereb…
# ℹ 32,418 more rows
# ℹ 9 more variables: mouse <dbl>, ENTREZID <dbl>, product <chr>,
# ensembl_gene_id <chr>, external_synonym <chr>, chromosome_name <chr>,
# gene_biotype <chr>, phenotype_description <chr>,
# hsapiens_homolog_associated_gene_name <chr>Cette structure est appelée “format long”, car une colonne contient toutes les valeurs, et d’autres colonnes répertorient le contexte de la valeur.
Dans certains cas, le “format long” n’est pas facile à lire, et un autre format, un “format large” est préféré, comme manière plus compacte de représenter les données. Cela est typiquement le cas pour des données d’expression de gènes, qui sont généralement représentées sous forme de matrice où les gènes sont repris le long des lignes et les échantillons le long des colonnes.
Dans ce format, il devient donc simple d’explorer la relation entre les niveaux d’expression génique au sein et entre les échantillons.
OUTPUT
# A tibble: 1,474 × 23
gene GSM2545336 GSM2545337 GSM2545338 GSM2545339 GSM2545340 GSM2545341
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Asl 1170 361 400 586 626 988
2 Apod 36194 10347 9173 10620 13021 29594
3 Cyp2d22 4060 1616 1603 1901 2171 3349
4 Klk6 287 629 641 578 448 195
5 Fcrls 85 233 244 237 180 38
6 Slc2a4 782 231 248 265 313 786
7 Exd2 1619 2288 2235 2513 2366 1359
8 Gjc2 288 595 568 551 310 146
9 Plp1 43217 101241 96534 58354 53126 27173
10 Gnb4 1071 1791 1867 1430 1355 798
# ℹ 1,464 more rows
# ℹ 16 more variables: GSM2545342 <dbl>, GSM2545343 <dbl>, GSM2545344 <dbl>,
# GSM2545345 <dbl>, GSM2545346 <dbl>, GSM2545347 <dbl>, GSM2545348 <dbl>,
# GSM2545349 <dbl>, GSM2545350 <dbl>, GSM2545351 <dbl>, GSM2545352 <dbl>,
# GSM2545353 <dbl>, GSM2545354 <dbl>, GSM2545362 <dbl>, GSM2545363 <dbl>,
# GSM2545380 <dbl>Pour convertir les valeurs d’expression génique de rna
en un format large, nous devons créer une nouvelle table où les valeurs
de la colonne sample deviendraient les noms des variables
de colonne.
Nous remodellons les données en fonction des observations d’intérêt, tout en continant à suivre les principles des données tidy: niveaux d’expression par gène au lieu des les afficher par gènes et par échantillons.
La transformation inverse serait de transformer les noms de colonnes en valeurs d’une nouvelle variable.
Nous pouvons effectuer ces deux transformations avec deux fonctions
du package tidyr, à savoir pivot_longer() et
pivot_wider() (voir ici
pour détails).
Pivoter les données en format large
Sélectionnons les 3 premières colonnes de rna et
utilisons pivot_wider() pour transformer les données en
format large.
R
rna_exp <- rna |>
select(gene, sample, expression)
rna_exp
OUTPUT
# A tibble: 32,428 × 3
gene sample expression
<chr> <chr> <dbl>
1 Asl GSM2545336 1170
2 Apod GSM2545336 36194
3 Cyp2d22 GSM2545336 4060
4 Klk6 GSM2545336 287
5 Fcrls GSM2545336 85
6 Slc2a4 GSM2545336 782
7 Exd2 GSM2545336 1619
8 Gjc2 GSM2545336 288
9 Plp1 GSM2545336 43217
10 Gnb4 GSM2545336 1071
# ℹ 32,418 more rowspivot_wider prend trois arguments principaux :
- les données à transformer ;
- le
names_from: la colonne dont les valeurs deviendront les nouveaux noms de colonne ; - les
values_from: la colonne dont les valeurs rempliront les nouvelles colonnes.
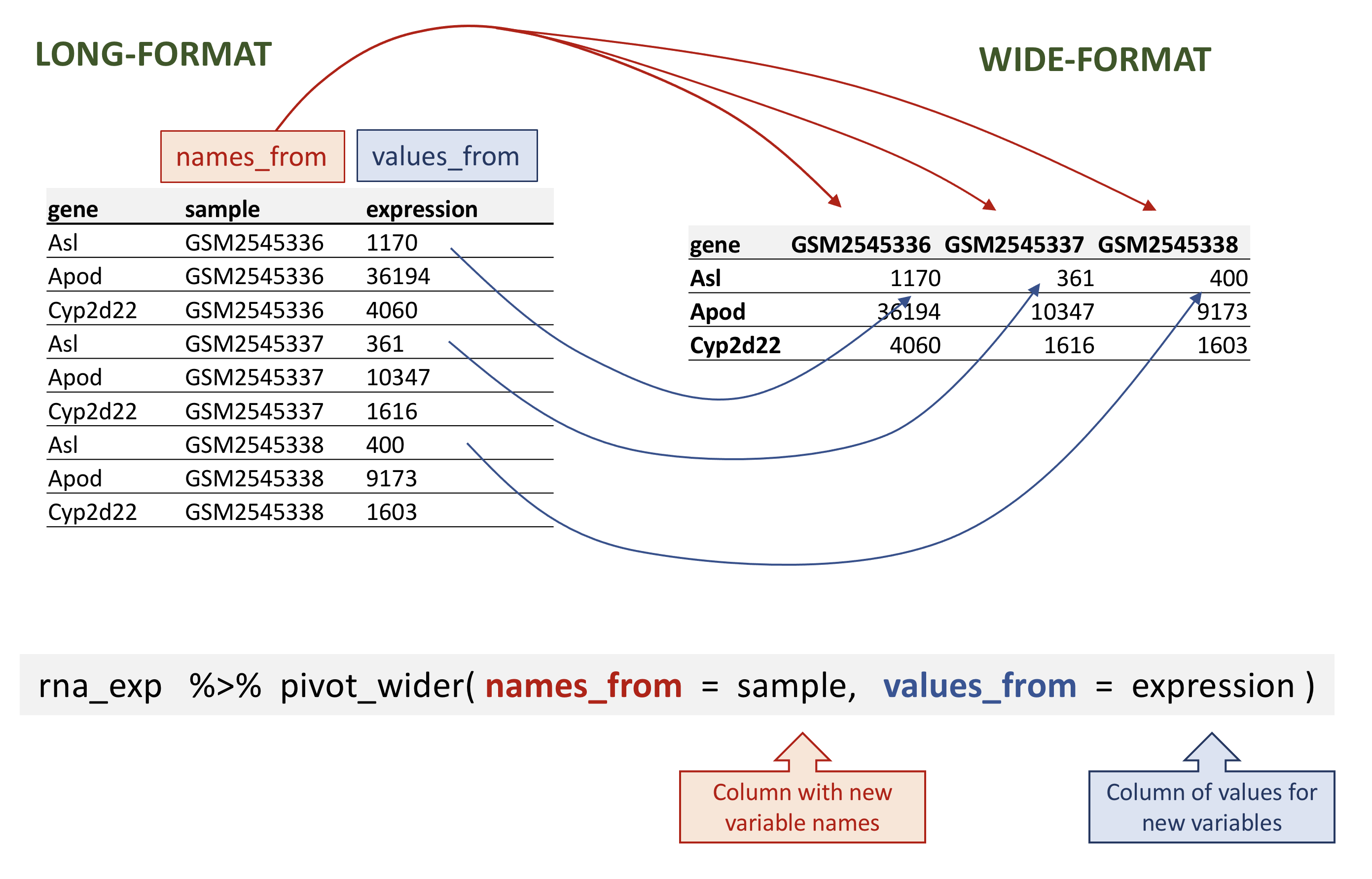
rna.
R
rna_wide <- rna_exp |>
pivot_wider(names_from = sample,
values_from = expression)
rna_wide
OUTPUT
# A tibble: 1,474 × 23
gene GSM2545336 GSM2545337 GSM2545338 GSM2545339 GSM2545340 GSM2545341
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Asl 1170 361 400 586 626 988
2 Apod 36194 10347 9173 10620 13021 29594
3 Cyp2d22 4060 1616 1603 1901 2171 3349
4 Klk6 287 629 641 578 448 195
5 Fcrls 85 233 244 237 180 38
6 Slc2a4 782 231 248 265 313 786
7 Exd2 1619 2288 2235 2513 2366 1359
8 Gjc2 288 595 568 551 310 146
9 Plp1 43217 101241 96534 58354 53126 27173
10 Gnb4 1071 1791 1867 1430 1355 798
# ℹ 1,464 more rows
# ℹ 16 more variables: GSM2545342 <dbl>, GSM2545343 <dbl>, GSM2545344 <dbl>,
# GSM2545345 <dbl>, GSM2545346 <dbl>, GSM2545347 <dbl>, GSM2545348 <dbl>,
# GSM2545349 <dbl>, GSM2545350 <dbl>, GSM2545351 <dbl>, GSM2545352 <dbl>,
# GSM2545353 <dbl>, GSM2545354 <dbl>, GSM2545362 <dbl>, GSM2545363 <dbl>,
# GSM2545380 <dbl>Notez que par défaut, la fonction pivot_wider() ajoutera
NA pour les valeurs manquantes.
Imaginons que nous ayons des valeurs d’expression manquantes pour certains gènes dans certains échantillons. Dans cet exemple, le gène Cyp2d22 n’aune donnée d’expression que pour l’echantillon GSM2545338.
Par défaut, la fonction pivot_wider() ajoutera
NA pour les valeurs manquantes. Ceci peut être paramétré
avec l’argument values_fill de la fonction
pivot_wider().
R
rna_with_missing_values %>%
pivot_wider(names_from = échantillon,
values_from = expression)
ERROR
Error: object 'rna_with_missing_values' not foundR
rna_with_missing_values %>%
pivot_wider(names_from = échantillon,
values_from = expression,
valeurs_fill = 0)
ERROR
Error: object 'rna_with_missing_values' not foundPivoter les données en format long
Dans la situation inverse, nous utilisons les noms de colonnes et les transformons en deux nouvelles variables. Une variable représente le nom de colonne contenant les valeurs, et l’autre contenant les valeurs précédemment associées aux noms de colonnes.
pivot_longer() prend quatre arguments principaux :
- les données à transformer ;
-
names_to: le nouveau nom de colonne que nous souhaitons créer et remplir avec les noms de colonnes actuels ; -
values_to: le nouveau nom de colonne que nous souhaitons créer et remplir avec valeurs actuelles ; - les noms des colonnes à utiliser pour renseigner les variables
names_toetvalues_to(ou à ignorer).
{r, fig.cap="Pivot long des données `rna`.", echo=FALSE, message=FALSE} knitr::include_graphics("fig/pivot_longer.png")
Pour créer `rna_long` à partir de `rna_wide`, nous créons une première variable `"sample"` qui conteindra les noms des échantillons repris comme noms de colonnes (hormi `gene`), et une seconde, `"expression"`, qui contiendra les valeurs de la table. Nous ommettons la colonne `gene` pour la transformation en y ajoutant le signe moins.
Notez que les nouveaux noms de colonnes sont repris entre guillemets.
``` r
rna_long <- rna_wide %>%
pivot_longer(names_to = "sample",
values_to = "expression",
-gene)
rna_longOUTPUT
# A tibble: 32,428 × 3
gene sample expression
<chr> <chr> <dbl>
1 Asl GSM2545336 1170
2 Asl GSM2545337 361
3 Asl GSM2545338 400
4 Asl GSM2545339 586
5 Asl GSM2545340 626
6 Asl GSM2545341 988
7 Asl GSM2545342 836
8 Asl GSM2545343 535
9 Asl GSM2545344 586
10 Asl GSM2545345 597
# ℹ 32,418 more rowsNous aurions également pu spécifier les colonnes à inclure. Quand il
faut inclure un grand nombre de colonnes, et il est plus facile de
spécifier ce qu’il faut rassembler que ce qu’il faut ignorer. Ici, la
fonction starts_with() peut aider à récupérer des colonnes
sans avoir à toutes les énumérer ! Une autre possibilité serait
d’utiliser l’opérateur : !
R
rna_wide %>%
pivot_longer(names_to = "sample",
values_to = "expression",
cols = start_with("GSM"))
ERROR
Error in `pivot_longer()`:
ℹ In argument: `start_with("GSM")`.
Caused by error in `start_with()`:
! could not find function "start_with"R
rna_wide %> %
pivot_longer(names_to = "sample",
valeurs_to = "expression",
GSM2545336:GSM2545380)
ERROR
Error in rna_wide %> % pivot_longer(names_to = "sample", valeurs_to = "expression", : could not find function "%> %"Notez que si nous avions des valeurs manquantes dans le format large,
le NA serait inclus dans le nouveau format long.
Souvenez-vous de notre précédent tibble fictif contenant des valeurs manquantes :
R
rna_with_missing_values
ERROR
Error: object 'rna_with_missing_values' not foundR
wide_with_NA <- rna_with_missing_values %>%
pivot_wider(names_from = sample,
values_from = expression)
ERROR
Error: object 'rna_with_missing_values' not foundR
wide_with_NA
ERROR
Error: object 'wide_with_NA' not foundR
wide_with_NA %>%
pivot_longer(names_to = "sample",
values_to = "expression",
-gene)
ERROR
Error: object 'wide_with_NA' not foundPasser à des formats larges et longs peut être un moyen utile d’équilibrer un ensemble de données afin que chaque réplique ait la même composition.
Question
A partir de la table rna, utilisez la fonction
pivot_wider() pour créer un tableau au format large donnant
les niveaux d’expression génique chez chaque souris. Utilisez ensuite la
fonction pivot_longer() pour restaurer le tableau au format
long.
R
rna1 <- rna %>%
select(gene, mouse, expression) %>%
pivot_wider(names_from = mouse, values_from = expression)
rna1
OUTPUT
# A tibble: 1,474 × 23
gene `14` `9` `10` `15` `18` `6` `5` `11` `22` `13` `23`
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Asl 1170 361 400 586 626 988 836 535 586 597 938
2 Apod 36194 10347 9173 10620 13021 29594 24959 13668 13230 15868 27769
3 Cyp2d22 4060 1616 1603 1901 2171 3349 3122 2008 2254 2277 2985
4 Klk6 287 629 641 578 448 195 186 1101 537 567 327
5 Fcrls 85 233 244 237 180 38 68 375 199 177 89
6 Slc2a4 782 231 248 265 313 786 528 249 266 357 654
7 Exd2 1619 2288 2235 2513 2366 1359 1474 3126 2379 2173 1531
8 Gjc2 288 595 568 551 310 146 186 791 454 370 240
9 Plp1 43217 101241 96534 58354 53126 27173 28728 98658 61356 61647 38019
10 Gnb4 1071 1791 1867 1430 1355 798 806 2437 1394 1554 960
# ℹ 1,464 more rows
# ℹ 11 more variables: `24` <dbl>, `8` <dbl>, `7` <dbl>, `1` <dbl>, `16` <dbl>,
# `21` <dbl>, `4` <dbl>, `2` <dbl>, `20` <dbl>, `12` <dbl>, `19` <dbl>R
rna1 %>%
pivot_longer(names_to = "mouse_id", values_to = "counts", -gene)
OUTPUT
# A tibble: 32,428 × 3
gene mouse_id counts
<chr> <chr> <dbl>
1 Asl 14 1170
2 Asl 9 361
3 Asl 10 400
4 Asl 15 586
5 Asl 18 626
6 Asl 6 988
7 Asl 5 836
8 Asl 11 535
9 Asl 22 586
10 Asl 13 597
# ℹ 32,418 more rowsQuestion
Extraire les gènes situés sur les chromosomes X et Y du data frame
rna et remodeler les données avec la variable
sex en colonnes et la varibale chromosome_name
en lignes et l’expression moyenne des gènes localisés dans chaque
chromosome comme valeurs, comme dans le tableau suivant :
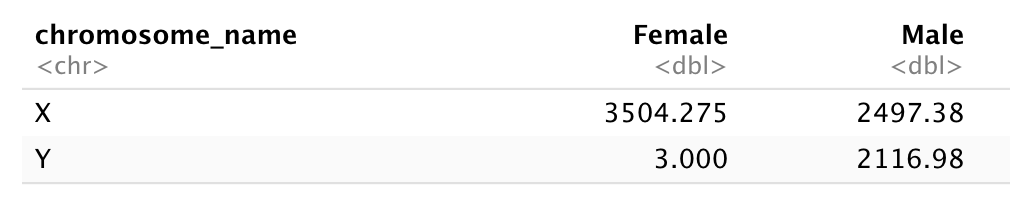
Il faudra résumer avant de remodeler !
Calculons d’abord le niveau d’expression moyen des gènes des chromosomes X et Y pour les échantillons mâles et femelles…
R
arn %>%
filter(chromosome_name == "Y" | chromosome_name == "X") %>%
group_by(sex, chromosome_name) %>%
résumé(moyenne = moyenne(expression))
ERROR
Error in résumé(., moyenne = moyenne(expression)): could not find function "résumé"Et pivotons le tableau au format large
R
rna_1 <- rna %>%
filter(chromosome_name == "Y" | chromosome_name == "X") %>%
group_by(sex, chromosome_name) %>%
summarise(mean = moyenne(expression)) %>%
pivot_wider(names_from = sexe,
valeurs_from = moyenne)
ERROR
Error in `summarise()`:
ℹ In argument: `mean = moyenne(expression)`.
ℹ In group 1: `sex = "Female"` `chromosome_name = "X"`.
Caused by error in `moyenne()`:
! could not find function "moyenne"R
rna_1
ERROR
Error: object 'rna_1' not foundMaintenant, prenez cette trame de données et transformez-la avec
pivot_longer() afin que chaque ligne soit une combinaison
unique de chromosome_name par gender.
R
rna_1 %>%
pivot_longer(names_to = "gender",
valeurs_to = "mean",
-chromosome_name)
ERROR
Error: object 'rna_1' not foundERROR
Error in `pivot_longer()`:
! Arguments in `...` must be used.
✖ Problematic argument:
• valeurs_to = "mean"
ℹ Did you misspell an argument name?Question
Utilisez l’ensemble de données rna pour créer une
matrice d’expression où chaque ligne représente les niveaux d’expression
moyens des gènes et les colonnes représentent les différents temps.
Calculons d’abord l’expression moyenne par gène et par temps
R
arn %>%
group_by(gène, temps) %>%
résumé(mean_exp = moyenne(expression))
ERROR
Error in résumé(., mean_exp = moyenne(expression)): could not find function "résumé"avant d’utiliser la fonction pivot_wider()
R
rna_time <- rna |>
group_by(gene, time) |>
summarise(mean_exp = mean(expression)) |>
pivot_wider(names_from = time,
values_from = mean_exp)
OUTPUT
`summarise()` has grouped output by 'gene'. You can override using the
`.groups` argument.R
rna_time
OUTPUT
# A tibble: 1,474 × 4
# Groups: gene [1,474]
gene `0` `4` `8`
<chr> <dbl> <dbl> <dbl>
1 AI504432 1034. 1104. 1014
2 AW046200 155. 152. 81
3 AW551984 238 302. 342.
4 Aamp 4603. 4870 4763.
5 Abca12 5.29 4.25 4.14
6 Abcc8 2576. 2609. 2292.
7 Abhd14a 591. 547. 432.
8 Abi2 4881. 4903. 4945.
9 Abi3bp 1175. 1061. 762.
10 Abl2 2170. 2078. 2131.
# ℹ 1,464 more rowsNotez que cela génère un tibble avec certains noms de colonnes commençant par un nombre. Si nous voulions sélectionner la colonne correspondant aux points temporels, nous ne pourrions pas utiliser directement les noms des colonnes… Que se passe-t-il lorsque l’on sélectionne la colonne 4 ?
R
rna |>
group_by(gene, time) |>
summarise(mean_exp = mean(expression)) |>
pivot_wider(names_from = time,
values_from = mean_exp) |>
select(gene, 4)
OUTPUT
`summarise()` has grouped output by 'gene'. You can override using the
`.groups` argument.OUTPUT
# A tibble: 1,474 × 2
# Groups: gene [1,474]
gene `8`
<chr> <dbl>
1 AI504432 1014
2 AW046200 81
3 AW551984 342.
4 Aamp 4763.
5 Abca12 4.14
6 Abcc8 2292.
7 Abhd14a 432.
8 Abi2 4945.
9 Abi3bp 762.
10 Abl2 2131.
# ℹ 1,464 more rowsPour sélectionner le temp 4, il faudrait citer le nom de la colonne, avec des backticks “\`”
R
rna |>
group_by(gene, time) |>
summarise(mean_exp = mean(expression)) |>
pivot_wider(names_from = time,
values_from = mean_exp) |>
select(gene, `4`)
OUTPUT
`summarise()` has grouped output by 'gene'. You can override using the
`.groups` argument.OUTPUT
# A tibble: 1,474 × 2
# Groups: gene [1,474]
gene `4`
<chr> <dbl>
1 AI504432 1104.
2 AW046200 152.
3 AW551984 302.
4 Aamp 4870
5 Abca12 4.25
6 Abcc8 2609.
7 Abhd14a 547.
8 Abi2 4903.
9 Abi3bp 1061.
10 Abl2 2078.
# ℹ 1,464 more rowsUne autre possibilité serait de renommer les colonnes, en choisissant des noms qui ne commencent pas par un chiffre :
R
rna |>
group_by(gene, time) |>
summarise(mean_exp = mean(expression)) |>
pivot_wider(names_from = time,
values_from = mean_exp) |>
rename("time0" = `0`, "time4" = `4`, "time8" = `8`) |>
select(gene, time4)
OUTPUT
`summarise()` has grouped output by 'gene'. You can override using the
`.groups` argument.OUTPUT
# A tibble: 1,474 × 2
# Groups: gene [1,474]
gene time4
<chr> <dbl>
1 AI504432 1104.
2 AW046200 152.
3 AW551984 302.
4 Aamp 4870
5 Abca12 4.25
6 Abcc8 2609.
7 Abhd14a 547.
8 Abi2 4903.
9 Abi3bp 1061.
10 Abl2 2078.
# ℹ 1,464 more rowsQuestion
Utilisez le data frame précédent contenant les niveaux d’expression moyens par temps et créez une nouvelle colonne contenant les fold-changes entre les temps 8 et 0, et les temps 8 et 4. Convertissez ce tableau en un tableau au format long regroupant les fold-changes calculés.
À partir du tibble rna_time :
R
arn_time
ERROR
Error: object 'arn_time' not foundCalculer les fold-changes :
R
rna_time %>%
muter (time_8_vs_0 = `8` / `0`, time_8_vs_4 = `8` / `4`)
ERROR
Error in muter(., time_8_vs_0 = `8`/`0`, time_8_vs_4 = `8`/`4`): could not find function "muter"Et utilisez la fonction pivot_longer() :
R
rna_time |>
mutate(time_8_vs_0 = `8` / `0`, time_8_vs_4 = `8` / `4`) |>
pivot_longer(names_to = "comparisons",
values_to = "Fold_changes",
time_8_vs_0:time_8_vs_4)
OUTPUT
# A tibble: 2,948 × 6
# Groups: gene [1,474]
gene `0` `4` `8` comparisons Fold_changes
<chr> <dbl> <dbl> <dbl> <chr> <dbl>
1 AI504432 1034. 1104. 1014 time_8_vs_0 0.981
2 AI504432 1034. 1104. 1014 time_8_vs_4 0.918
3 AW046200 155. 152. 81 time_8_vs_0 0.522
4 AW046200 155. 152. 81 time_8_vs_4 0.532
5 AW551984 238 302. 342. time_8_vs_0 1.44
6 AW551984 238 302. 342. time_8_vs_4 1.13
7 Aamp 4603. 4870 4763. time_8_vs_0 1.03
8 Aamp 4603. 4870 4763. time_8_vs_4 0.978
9 Abca12 5.29 4.25 4.14 time_8_vs_0 0.784
10 Abca12 5.29 4.25 4.14 time_8_vs_4 0.975
# ℹ 2,938 more rowsJointures de tables
Dans de nombreuses situations réelles, les données sont réparties sur plusieurs tables. Cela se produit généralement parce que différents types d’informations sont collectés à partir de différentes sources.
Il peut être souhaitable que certaines analyses combinent les données de deux ou plusieurs tables en un seul data frame basé sur une colonne commune à toutes les tables.
Le package dplyr fournit un ensemble de fonctions de
jointure pour combiner deux data frames en fonction des correspondances
entre les colonnes spécifiées. Ici, nous fournissons une brève
introduction aux jointures. Pour en savoir plus, veuillez vous référer
au chapitre sur les jointures
de table. Le Data Transformation Cheat Sheet fournit également un
bref aperçu sur les jointures de table.
Nous allons illustrer la jointure en utilisant une petite table,
rna_mini que nous allons créer en extrayant de la table
rna d’origine 3 colonnes et 10 lignes.
R
rna_mini <- rna %>%
select(gène, échantillon, expression) %>%
head(10)
ERROR
Error in `select()`:
! Can't select columns that don't exist.
✖ Column `gène` doesn't exist.R
rna_mini
ERROR
Error: object 'rna_mini' not foundLe deuxième tableau, annot1, contient 2 colonnes,
gene et gene_description. Vous pouvez soit télécharger
annot1.csv en cliquant sur le lien puis en déplaçant le fichier dans
le dossier data/, ou vous pouvez utiliser le code R
ci-dessous pour le télécharger directement dans le dossier
data.
R
download.file(url = "https://carpentries-incubator.github.io/bioc-intro/data/annot1.csv",
destfile = "data/annot1.csv")
annot1 <- read_csv(file = "data/annot1.csv")
annot1
OUTPUT
# A tibble: 10 × 2
gene gene_description
<chr> <chr>
1 Cyp2d22 cytochrome P450, family 2, subfamily d, polypeptide 22 [Source:MGI S…
2 Klk6 kallikrein related-peptidase 6 [Source:MGI Symbol;Acc:MGI:1343166]
3 Fcrls Fc receptor-like S, scavenger receptor [Source:MGI Symbol;Acc:MGI:19…
4 Plp1 proteolipid protein (myelin) 1 [Source:MGI Symbol;Acc:MGI:97623]
5 Exd2 exonuclease 3'-5' domain containing 2 [Source:MGI Symbol;Acc:MGI:192…
6 Apod apolipoprotein D [Source:MGI Symbol;Acc:MGI:88056]
7 Gnb4 guanine nucleotide binding protein (G protein), beta 4 [Source:MGI S…
8 Slc2a4 solute carrier family 2 (facilitated glucose transporter), member 4 …
9 Asl argininosuccinate lyase [Source:MGI Symbol;Acc:MGI:88084]
10 Gjc2 gap junction protein, gamma 2 [Source:MGI Symbol;Acc:MGI:2153060] Nous voulons maintenant joindre ces deux tables en une seule
contenant toutes les variables en utilisant la fonction
full_join() du package dplyr. La fonction
trouvera automatiquement la variable commune correspondant aux colonnes
de la première et de la deuxième table. Dans ce cas, gene
est la seule variable commune. De telles variables sont appelées clés.
Les clés sont utilisées pour faire correspondre les observations dans
différentes tables.
R
full_join(rna_mini, annot1)
ERROR
Error: object 'rna_mini' not foundEn recherche, les gènes sont parfois només différemment.
La table annot2 est exactement la même que
annot1 sauf que la variable contenant les noms de gènes est
nommée différemment. Encore une fois, téléchargez
annot2.csv vous-même et déplacez-le vers data/ ou
utilisez le code R ci-dessous.
R
download.file(url = "https://carpentries-incubator.github.io/bioc-intro/data/annot2.csv",
destfile = "data/annot2.csv")
annot2 <- read_csv(file = "data/annot2.csv")
annot2
OUTPUT
# A tibble: 10 × 2
external_gene_name description
<chr> <chr>
1 Cyp2d22 cytochrome P450, family 2, subfamily d, polypeptide 22 [S…
2 Klk6 kallikrein related-peptidase 6 [Source:MGI Symbol;Acc:MGI…
3 Fcrls Fc receptor-like S, scavenger receptor [Source:MGI Symbol…
4 Plp1 proteolipid protein (myelin) 1 [Source:MGI Symbol;Acc:MGI…
5 Exd2 exonuclease 3'-5' domain containing 2 [Source:MGI Symbol;…
6 Apod apolipoprotein D [Source:MGI Symbol;Acc:MGI:88056]
7 Gnb4 guanine nucleotide binding protein (G protein), beta 4 [S…
8 Slc2a4 solute carrier family 2 (facilitated glucose transporter)…
9 Asl argininosuccinate lyase [Source:MGI Symbol;Acc:MGI:88084]
10 Gjc2 gap junction protein, gamma 2 [Source:MGI Symbol;Acc:MGI:…Si aucun des noms de variables ne correspond, nous pouvons définir
manuellement les variables à utiliser pour la correspondance. Ces
variables peuvent être définies en utilisant l’argument by,
comme indiqué ci-dessous avec les tables rna_mini et
annot2.
R
full_join(rna_mini, annot2, by = c("gene" = "external_gene_name"))
ERROR
Error: object 'rna_mini' not foundComme on peut le voir ci-dessus, le nom de variable de la première table est lors de la jointure.
Défi:
Téléchargez la table annot3 en cliquant ici
et placez la table dans votre dossier data. À l’aide de la
fonction full_join(), joignez les tables
rna_mini et annot3. Que s’est-il passé pour
les gènes Klk6, mt-Tf, mt-Rnr1,
mt-Tv, mt-Rnr2 et mt-Tl1 ?
R
annot3 <- read_csv("data/annot3.csv")
full_join(rna_mini, annot3)
ERROR
Error: object 'rna_mini' not foundLes gènes Klk6 ne sont présents que dans
rna_mini, tandis que les gènes mt-Tf,
mt-Rnr1, mt-Tv, mt-Rnr2 et mt-Tl1
sont présent uniquement dans la table annot3. Leurs valeurs
respectives pour les variables du tableau ont été codées comme
manquantes.
Exporter des données
Maintenant que vous avez appris à utiliser dplyr pour
extraire des informations de ou résumer vos données, vous souhaiterez
peut-être exporter ces nouveaux jeux de données pour les partager avec
vos collaborateurs ou pour les archiver.
Tout comme à la fonction read_csv() utilisée pour
lire/importer les fichiers CSV dans R, il existe une fonction
write_csv() qui génère des fichiers CSV à partir de data
frames.
Avant d’utiliser write_csv(), nous allons créer un
nouveau dossier, data_output, dans notre répertoire de
travail, pour y sauvegarder nos nouveaux de données. Nous ne voulons pas
écrive les ensembles de données générés dans le même répertoire que nos
données brutes. C’est en effet une bonne pratique de les garder séparés.
Le dossier data ne doit contenir que les données brutes et
non modifiées, et doit être laissé tel quel pour nous assurer que nous
ne les supprimons ou modifions pas. En revanche, notre script générera
le contenu du répertoire data_output, donc même si les
fichiers qu’il contient sont supprimés, nous pourrons toujours les
regénérer.
Utilisons write_csv() pour sauvegarder la table
rna_wide que nous avons créée précédemment.
R
write_csv(rna_wide, file = "data_output/rna_wide.csv")
Key Points
- Données tabulaires dans R utilisant le méta-package tidyverse.
Content from Visualisation de données
Last updated on 2025-05-05 | Edit this page
Estimated time: 120 minutes
Overview
Questions
- Visualisation en R
Objectives
- Produire des scatter plots (nuages de points), des boxplots (boîtes à moustache), des line plots (tracés linéaires), etc. en utilisant ggplot.
- Définir les paramètres universels des graphiques.
- Décrire ce qu’est le faceting (facettage) et appliquez le faceting dans ggplot.
- Modifiez les éléments esthétiques d’un tracé
ggplotexistant (y compris les étiquettes et la couleur des axes). - Créer des graphiques complexes et personnalisés à prtir de données dans un data frame.
Cet épisode est basé sur la leçon Data Analysis and Visualisation in R for Ecologists des Data Carpentries.
Visualisation de données
Nous commençons par charger les packages requis.
ggplot2 est inclus dans le package
tidyverse.
R
bibliothèque("tidyverse")
ERROR
Error in bibliothèque("tidyverse"): could not find function "bibliothèque"Si vous n’êtes pas encore dans l’espace de travail, chargez les données que nous avons enregistrées dans la leçon précédente.
R
arn <- read.csv("data/rnaseq.csv")
La Data Visualization Cheat
couvrira les bases et les fonctionnalités plus avancées de
ggplot2 et servira non seulement de pense-bête, mais
donnera aussi un aperçu des nombreuses représentations de données
disponibles dans le package. Les didacticiels vidéo suivants (partie 1 et 2) de Thomas
Lin Pedersen sont également très instructifs.
Tracer avec ggplot2
ggplot2 est un package graphique qui simplifie la
création de graphiques complexes à partir de données dans un data
frame. Il fournit une interface de programmation pour spécifier les
variables à représenter sur le graphique, comment elles sont
représentées, ainsi que les propriétés visuelles générales. Les concepts
théoriques qui sont à la base de ggplot2 sont décrits dans
le livre Grammar of Graphics (@Wilkinson :2005). En utilisant cette approche ,
nous n’avons besoin que de changements minimes si les données
sous-jacentes changent ou si nous décidons de passer d’un bar
plot à un scatter plot, par exemple. Cela aide à créer des
graphiques de qualité professionnelle avec un minimum d’ajustements.
Il existe aussi un livre décrivant ggplot2 (@ggplot2book) qui en fournit un bon aperçu, mais
il est obsolète. La 3ème édition est en préparation et sera disponible gratuitement en ligne.
La page Web ggplot2 (https://ggplot2.tidyverse.org)
fournit une documentation abondante.
ggplot2 fonctionne avec des données au format « long »,
c’est-à-dire une colonne pour chaque variable et une ligne pour chaque
observation. Des données bien structurées vous feront gagner beaucoup de
temps lors de la création de figures avec ggplot2.
Les graphiques ggplot sont construits étape par étape en ajoutant de nouveaux éléments appelés couches. L’ajout progressif de couches permet une grande flexibilité et une personnalisation des graphiques.
L’idée derrière la “Grammar of Graphics” est que vous pouvez construire chaque graphique à partir des 3 mêmes composants : (1) un jeu de données, (2) un système de coordonnées, et (3) des “geoms” — c’est-à-dire des marques visuelles qui représentent des points de données [^trois\_comp\_ggplot2]
Pour construire un ggplot, nous utiliserons le modèle de base suivant qui peut être utilisé pour différents types de graphiques :
ggplot(data = <DATA>, mapping = aes(<MAPPINGS>)) + <GEOM_FUNCTION>()- utiliser la fonction
ggplot()et lier un data frame spécifique en utilisant l’argumentdata
R
ggplot(data = rna)
- définir un mapping (en utilisant la fonction
d’esthétique (
aes)), qui consiste à: (1) sélectionner les variables du data frame à réprésenter et (2) les lier à des caractéristiques du graphique comme les coordonnées x ou y, ou encore la taille, la couleur, la forme, etc.
R
ggplot(data = rna, mapping = aes(x = expression))
- ajouter des ‘geoms’ - géométries ou représentations
graphiques des données dans le graphique (points, lignes, barres).
ggplot2propose de nombreux geom différents. Ici nous utiliserons les plus courantes, par exemple :
* `geom_point()` pour les *scatter plots* (nuages de points), les *dot plots* (diagrammes de points), etc.
* `geom_histogram()` pour les histogrammes
* `geom_boxplot()` pour, eh bien, les *boxplots* !
* `geom_line()` pour les lignes de tendance, les séries chronologiques, etc.Pour ajouter un geom au graphique, utilisez l’opérateur
+. Utilisons d’abord geom_histogram() :
R
ggplot(data = rna, mapping = aes(x = expression)) +
geom_histogram()
ERROR
Error in ggplot(data = rna, mapping = aes(x = expression)): could not find function "ggplot"Le symbole + dans le package ggplot2 est
particulièrement utile car il vous permet de modifier les objets
ggplot existants. Cela signifie que vous pouvez facilement
configurer des modèles de graphique et explorer facilement différents
types de graphiques. En procédant de la sorte, le graphique obtenu
précédemment peut également être généré avec un code comme
celui-ci :
R
# Assign plot to a variable
rna_plot <- ggplot(data = rna,
mapping = aes(x = expression))
# Draw the plot
rna_plot + geom_histogram()
Défi
Vous avez probablement remarqué un message automatique qui apparaît lorsqu’on trace un histogramme :
ERROR
Error in ggplot(rna, aes(x = expression)): could not find function "ggplot"Définissez un mapping (en utilisant la fonction esthétique
(aes)), qui consiste à: (1) sélectionner les variables du
data frame à réprésenter et (2) les lier à des caractéristiques
du graphique comme les coordonnées x ou y, ou encore la taille, la
couleur, la forme, etc.
R
# change bins
ggplot(rna, aes(x = expression)) +
geom_histogram(bins = 15)
ERROR
Error in ggplot(rna, aes(x = expression)): could not find function "ggplot"R
# change binwidth
ggplot(rna, aes(x = expression)) +
geom_histogram(binwidth = 2000)
ERROR
Error in ggplot(rna, aes(x = expression)): could not find function "ggplot"Nous pouvons observer ici que les données présentent un right
skew (asymétrie vers la droite). Nous pouvons appliquer la
transformation log2 pour obtenir une distribution plus symétrique. Notez
que nous ajoutons ici une petite valeur constante (+1) pour
éviter que -Inf soit renvoyée pour des expressions égales à
0.
R
arn <- arn %>%
muter(expression_log = log2(expression + 1))
ERROR
Error in arn %>% muter(expression_log = log2(expression + 1)): could not find function "%>%"Si l’on dessine maintenant l’histogramme des expressions transformées en log2, la distribution est en effet plus proche d’une distribution normale.
R
ggplot(rna, aes(x = expression_log)) + geom_histogram()
ERROR
Error in ggplot(rna, aes(x = expression_log)): could not find function "ggplot"À partir de maintenant, nous travaillerons sur les valeurs d’expression transformées en log.
Défi
Une autre façon de visualiser cette transformation, plutôt que de transformer les données elles-mêmes, est de garder les données inchangées mais de choisir une autre échelle des observations. Par exemple, il peut être intéressant de changer l’échelle de l’axe pour mieux répartir les observations dans le graphique. Changer l’échelle des axes se fait de la même manière que pour ajouter/modifier d’autres composants (c’est-à-dire en ajoutant progressivement des commandes). Essayez de modifier le graphique précédent de la manière suivante:
- Représenter l’expression non transformée sur l’échelle log10 ; voir
scale_x_log10(). Comparer le résultat avec le graphique précédent. Pourquoi des warnings (messages d’avertissement) apparaissent-ils maintenant ?
R
ggplot(data = rna,mapping = aes(x = expression))+
geom_histogram() +
scale_x_log10()
ERROR
Error in ggplot(data = rna, mapping = aes(x = expression)): could not find function "ggplot"Remarques
- Tout ce que vous mentionnez dans la fonction
ggplot()peut être vu par n’importe quelle couche geom que vous ajoutez par la suite (c’est-à-dire qu’il s’agit de paramètres de graphiques globaux). Ceci y compris le mapping des axes x et y que vous avez configuré dansaes(). - Vous pouvez également spécifier des mappings pour un geom
donné, indépendamment des mappings définis globalement dans la fonction
ggplot(). - Le signe
+, utilisé pour ajouter de nouvelles couches, doit être placé à la fin de la ligne contenant la couche précédente. Si , au contraire, le signe+est ajouté au début d’une ligne contenant la nouvelle couche,ggplot2n’ajoutera pas la nouvelle couche et retournera un message d’erreur.
R
# This is the correct syntax for adding layers
rna_plot +
geom_histogram()
# This will not add the new layer and will return an error message
rna_plot
+ geom_histogram()
Construire vos graphiques de manière itérative
Nous allons maintenant dessiner un scatter plot avec deux
variables continues et la fonction geom_point(). Ce
graphique représentera les log2 fold changes (ratio de
valeurs convertis en log) des expressions, entre le temps 8
et le temps 0 d’une part, et entre le temps 4 et le temps 0 d’autre
part. Pour ce faire, nous devons d’abord calculer les moyennes des
valeurs d’expression transformées en log par gène et par temps, puis les
log fold changes souhaités. Notez que nous incluons également
ici le biotype du gène, que nous utiliserons plus tard pour représenter
les gènes. Nous enregistrerons les log fold changes dans un
nouveau data frame appelé rna_fc.
R
rna_fc <- rna %>% select(gene, time,
gene_biotype, expression_log) %>%
group_by(gene, time, gene_biotype) %>%
summary(mean_exp = moyenne (expression_log)) %>%
pivot_wider(names_from = temps,
valeurs_from = moyenne_exp) %>%
mutate(time_8_vs_0 = `8` - `0`, time_4_vs_0 = `4` - `0`)
ERROR
Error in rna %>% select(gene, time, gene_biotype, expression_log) %>% : could not find function "%>%"Nous pouvons ensuite construire un ggplot avec le jeu de données
nouvellement créé rna_fc. Construire des graphiques avec
ggplot2 est généralement un processus itératif. Nous
commençons par définir le jeu de données que nous allons utiliser,
tracer les axes et choisir une geom :
R
ggplot(data = rna_fc, mapping = aes(x = time_4_vs_0, y = time_8_vs_0)) +
geom_point()
ERROR
Error in ggplot(data = rna_fc, mapping = aes(x = time_4_vs_0, y = time_8_vs_0)): could not find function "ggplot"Ensuite, nous commençons à modifier ce graphique pour en extraire davantage d’informations. Par exemple, nous pouvons ajouter de la transparence (« alpha ») pour éviter la surcharge du graphique:
R
ggplot(data = rna_fc, mapping = aes(x = time_4_vs_0, y = time_8_vs_0)) +
geom_point(alpha = 0.3)
ERROR
Error in ggplot(data = rna_fc, mapping = aes(x = time_4_vs_0, y = time_8_vs_0)): could not find function "ggplot"On peut également ajouter des couleurs pour tous les points :
R
ggplot(data = rna_fc, mapping = aes(x = time_4_vs_0, y = time_8_vs_0)) +
geom_point(alpha = 0.3, color = "blue")
ERROR
Error in ggplot(data = rna_fc, mapping = aes(x = time_4_vs_0, y = time_8_vs_0)): could not find function "ggplot"Ou pour colorer différemment chaque gène du graphique, vous pouvez
utiliser un vecteur comme input dans l’argument color.
ggplot2 assignera une couleur différente à chaques valeurs
dans le vecteur. Voici un exemple où nous colorons avec la variable
gene_biotype :
R
ggplot(data = rna_fc, mapping = aes(x = time_4_vs_0, y = time_8_vs_0)) +
geom_point(alpha = 0.3, aes(color = gene_biotype))
ERROR
Error in ggplot(data = rna_fc, mapping = aes(x = time_4_vs_0, y = time_8_vs_0)): could not find function "ggplot"Nous pouvons également spécifier les couleurs directement à
l’intérieur du mapping fourni dans la fonction ggplot().
Cela sera visible par toutes les couches de geom et le mapping
sera déterminé par les axes x et y définis dans aes().
R
ggplot(data = rna_fc, mapping = aes(x = time_4_vs_0, y = time_8_vs_0,
color = gene_biotype)) +
geom_point(alpha = 0.3)
ERROR
Error in ggplot(data = rna_fc, mapping = aes(x = time_4_vs_0, y = time_8_vs_0, : could not find function "ggplot"Enfin, nous pourrions également ajouter une ligne diagonale avec la
fonction geom_abline() :
R
ggplot(data = rna_fc, mapping = aes(x = time_4_vs_0, y = time_8_vs_0,
color = gene_biotype)) +
geom_point(alpha = 0.3) +
geom_abline(intercept = 0)
ERROR
Error in ggplot(data = rna_fc, mapping = aes(x = time_4_vs_0, y = time_8_vs_0, : could not find function "ggplot"Notez que nous pouvons remplacer geom_point par
geom_jitter et les couleurs seront toujours déterminées par
gene_biotype.
R
ggplot(data = rna_fc, mapping = aes(x = time_4_vs_0, y = time_8_vs_0,
color = gene_biotype)) +
geom_jitter(alpha = 0.3) +
geom_abline(intercept = 0)
ERROR
Error in ggplot(data = rna_fc, mapping = aes(x = time_4_vs_0, y = time_8_vs_0, : could not find function "ggplot"ERROR
Error in bibliothèque("hexbin"): could not find function "bibliothèque"Défi
Les scatter plots peuvent être des outils d’exploration
utiles pour de petits jeux de données. Pour les jeux de données avec un
grand nombre d’observations, tels que le jeu de données
rna_fc , l’accumulation de points peut surcharger le
graphique, ce qui constitue une limitation des scatter plots.
Une stratégie possible dans de tels cas consiste à utiliser le
regroupement hexagonal d’observations. Dans ce cas, l’espace du
graphique est divisé en hexagones. Chaque hexagone se voit attribuer une
couleur en fonction du nombre d’observations qui se trouvent à
l’intérieur.
Pour utiliser le regroupement hexagonal dans
ggplot2, installez d’abord le package Rhexbindepuis CRAN et chargez-le.Utilisez ensuite la fonction
geom_hex()pour produire la figure hexbin.Quelles sont les avantages et inconvénients d’un diagramme hexagonal, par rapport à un scatter plot ? Examinez le scatter plot ci-dessus et comparez-le avec le diagramme hexagonal que vous avez créé.
R
install.packages("hexbin")
R
library("hexbin")
ERROR
Error in library("hexbin"): there is no package called 'hexbin'R
ggplot(data = rna_fc, mapping = aes(x = time_4_vs_0, y = time_8_vs_0)) +
geom_hex() +
geom_abline(intercept = 0)
ERROR
Error in ggplot(data = rna_fc, mapping = aes(x = time_4_vs_0, y = time_8_vs_0)): could not find function "ggplot"Défi
Utilisez ce que vous venez d’apprendre pour créer un scatter
plot de la variable expression_log en fonction de la
variable sample, à partir du jeu de données
rna, avec l’heure affichée dans différentes couleurs.
Est-ce une bonne façon d’afficher ce type de données ?
R
ggplot(data = rna, mapping = aes(y = expression_log, x = sample)) +
geom_point(aes(color = time))
ERROR
Error in ggplot(data = rna, mapping = aes(y = expression_log, x = sample)): could not find function "ggplot"Boxplot (boîte à moustaches)
Nous pouvons utiliser des boxplots pour visualiser la distribution des expressions géniques au sein de chaque échantillon :
R
ggplot(data = rna,
mapping = aes(y = expression_log, x = sample)) +
geom_boxplot()
ERROR
Error in ggplot(data = rna, mapping = aes(y = expression_log, x = sample)): could not find function "ggplot"En ajoutant des points au boxplot, on peut avoir une meilleure idée du nombre de mesures et de leur distribution :
R
ggplot(data = rna,
mapping = aes(y = expression_log, x = sample)) +
geom_jitter(alpha = 0.2, color = "tomato") +
geom_boxplot(alpha = 0)
ERROR
Error in ggplot(data = rna, mapping = aes(y = expression_log, x = sample)): could not find function "ggplot"Défi
Avez-vous remarqué que la couche boxplot se trouve devant la couche jitter ? Que devez-vous modifier dans le code pour placer le boxplot sous les points ?
Nous devrions inverser l’ordre de ces deux geom:
R
ggplot(data = rna,
mapping = aes(y = expression_log, x = sample)) +
geom_boxplot(alpha = 0) +
geom_jitter(alpha = 0.2, color = "tomato")
ERROR
Error in ggplot(data = rna, mapping = aes(y = expression_log, x = sample)): could not find function "ggplot"Vous remarquerez peut-être que les valeurs sur l’axe des x ne sont toujours pas lisibles correctement. Modifions l’orientation des étiquettes et ajustons-les verticalement et horizontalement afin qu’elles ne se chvauchent pas. Vous pouvez utiliser un angle de 90 degrés ou expérimenter pour trouver l’angle approprié pour des étiquettes orientées en diagonale :
R
ggplot(data = rna,
mapping = aes(y = expression_log, x = sample)) +
geom_jitter(alpha = 0.2, color = "tomato") +
geom_boxplot(alpha = 0) +
theme(axis.text.x = element_text(angle = 90, hjust = 0.5, vjust = 0.5))
ERROR
Error in ggplot(data = rna, mapping = aes(y = expression_log, x = sample)): could not find function "ggplot"Défi
Ajoutez de la couleur aux points de données sur votre boxplot en fonction de la durée de l’infection (« time »).
Indice : Vérifiez la classe pour la variable time.
Envisagez de changer la classe de time d’entier à
factor directement dans le mapping ggplot. Pourquoi cela
change-t-il la façon dont R crée le graphique ?
R
# time as integer
ggplot(data = rna,
mapping = aes(y = expression_log,
x = sample)) +
geom_jitter(alpha = 0.2, aes(color = time)) +
geom_boxplot(alpha = 0) +
theme(axis.text.x = element_text(angle = 90, hjust = 0.5, vjust = 0.5))
ERROR
Error in ggplot(data = rna, mapping = aes(y = expression_log, x = sample)): could not find function "ggplot"R
# time as factor
ggplot(data = rna,
mapping = aes(y = expression_log,
x = sample)) +
geom_jitter(alpha = 0.2, aes(color = as.factor(time))) +
geom_boxplot(alpha = 0) +
theme(axis.text.x = element_text(angle = 90, hjust = 0.5, vjust = 0.5))
ERROR
Error in ggplot(data = rna, mapping = aes(y = expression_log, x = sample)): could not find function "ggplot"Défi
Les boxplots sont des résumés utiles, mais ils ne révèlent pas la forme de la distribution. Par exemple, si la distribution est bi-modale, nous ne le verrions pas dans un boxplot. Une alternative au boxplot est le violin plot (graphiques en violon) , où la forme de la densité de points est dessinée.
- Remplacez la box plot par un violin plot ; voir
geom_violin(). Liez la couleur de remplissage des violons à la variabletime, grâce à l’argumentfill.
R
ggplot(data = rna,
mapping = aes(y = expression_log, x = sample)) +
geom_violin(aes(fill = as.factor(time))) +
theme(axis.text.x = element_text(angle = 90, hjust = 0.5, vjust = 0.5))
ERROR
Error in ggplot(data = rna, mapping = aes(y = expression_log, x = sample)): could not find function "ggplot"Défi
- Modifiez le violin plot pour lier la couleur de remplissage des violons à la variable “sex”.
R
ggplot(data = rna,
mapping = aes(y = expression_log, x = sample)) +
geom_violin(aes(fill = sex)) +
theme(axis.text.x = element_text(angle = 90, hjust = 0.5, vjust = 0.5))
ERROR
Error in ggplot(data = rna, mapping = aes(y = expression_log, x = sample)): could not find function "ggplot"Line plots (graphiques linéaires)
Calculons l’expression moyenne par durée de l’infection pour les 10
gènes ayant les log fold changes comparant le temps 8 au temps
0 les plus élevés. Tout d’abord, nous devons sélectionner les gènes et
créer un sous-ensemble de rna appelé sub_rna
contenant les 10 gènes sélectionnés, puis nous devons regrouper les
données et calculer l’expression moyenne des gènes dans chaque groupe
:
R
rna_fc <- rna_fc |> arrange(desc(time_8_vs_0))
ERROR
Error in arrange(rna_fc, desc(time_8_vs_0)): could not find function "arrange"R
genes_selected <- rna_fc$gene[1:10]
ERROR
Error: object 'rna_fc' not foundR
sub_rna <- rna |>
filter(gene %in% genes_selected)
ERROR
Error: object 'rna' not foundR
mean_exp_by_time <- sub_rna |>
group_by(gene,time) |>
summarize(mean_exp = mean(expression_log))
ERROR
Error in summarize(group_by(sub_rna, gene, time), mean_exp = mean(expression_log)): could not find function "summarize"R
mean_exp_by_time
ERROR
Error: object 'mean_exp_by_time' not foundNous pouvons construire le line plot avec la durée de l’infection sur l’axe des x et l’expression moyenne sur l’axe des y :
R
ggplot(data = moyenne_exp_by_time, mapping = aes(x = temps, y = moyenne_exp)) +
geom_line()
ERROR
Error in ggplot(data = moyenne_exp_by_time, mapping = aes(x = temps, y = moyenne_exp)): could not find function "ggplot"Malheureusement, cela ne fonctionne pas car nous avons représenté
ensemble les données de tous les gènes . Nous devons dire à ggplot de
tracer une ligne pour chaque gène en modifiant la fonction esthétique
pour inclure group = gene :
R
ggplot(data = moyenne_exp_by_time,
mapping = aes(x = temps, y = moyenne_exp, groupe = gène)) +
geom_line()
ERROR
Error in ggplot(data = moyenne_exp_by_time, mapping = aes(x = temps, y = moyenne_exp, : could not find function "ggplot"Nous pourrons distinguer les gènes dans le graphique si nous ajoutons
des couleurs (l’utilisation de color regroupe également
automatiquement les données) :
R
ggplot(data = moyenne_exp_by_time,
mapping = aes(x = temps, y = moyenne_exp, couleur = gène)) +
geom_line()
ERROR
Error in ggplot(data = moyenne_exp_by_time, mapping = aes(x = temps, y = moyenne_exp, : could not find function "ggplot"Faceting (diviser en facettes)
ggplot2 a une technique spéciale appelée
faceting qui permet à l’utilisateur de diviser un graphique en
plusieurs (sous) graphiques en fonction d’un facteur inclus dans le jeu
de données. Ces différents sous-graphiques héritent des mêmes propriétés
(limites des axes, graduations, …) pour faciliter leur comparaison
directe. Nous allons l’utiliser pour créer un line plot en
fonction du temps pour chaque gène :
R
ggplot(data = moyenne_exp_by_time,
mapping = aes(x = temps, y = moyenne_exp)) + geom_line() +
facet_wrap(~ gène)
ERROR
Error in ggplot(data = moyenne_exp_by_time, mapping = aes(x = temps, y = moyenne_exp)): could not find function "ggplot"Ici, les axes x et y ont la même échelle pour tous les
sous-graphiques. Vous pouvez changer ce comportement par défaut en
modifiant scales afin d’autoriser une échelle libre pour
l’axe y :
R
ggplot(data = moyenne_exp_by_time,
mapping = aes(x = temps, y = moyenne_exp)) +
geom_line() +
facet_wrap(~ gene, scales = "free_y")
ERROR
Error in ggplot(data = moyenne_exp_by_time, mapping = aes(x = temps, y = moyenne_exp)): could not find function "ggplot"Nous aimerions maintenant diviser la ligne dans chaque graphiques selon le sexe des souris. Pour ce faire, nous devons calculer l’expression moyenne dans le data frame regroupé par “gene”, “time” et “sex” :
R
Mean_exp_by_time_sex <- sub_rna %>%
group_by(gene, time, sex) %>%
summary(mean_exp = Mean(expression_log))
ERROR
Error in sub_rna %>% group_by(gene, time, sex) %>% summary(mean_exp = Mean(expression_log)): could not find function "%>%"R
Mean_exp_by_time_sex
ERROR
Error: object 'Mean_exp_by_time_sex' not foundNous pouvons maintenant créer le graphique à facettes. Nous ajoutons encore de l’information en divisant le line plot par sexe en y associant des couleurs (au sein d’un seul graphique) :
R
ggplot(data = moyenne_exp_by_time_sex,
mapping = aes(x = temps, y = moyenne_exp, couleur = sexe)) +
geom_line() +
facet_wrap(~ gène, échelles = "free_y")
ERROR
Error in ggplot(data = moyenne_exp_by_time_sex, mapping = aes(x = temps, : could not find function "ggplot"Généralement, les graphiques sur fond blanc sont plus lisibles une
fois imprimés. Nous pouvons définir l’arrière-plan en blanc en utilisant
la fonction theme_bw(). De plus, nous pouvons supprimer la
grille :
R
ggplot(data = moyenne_exp_by_time_sex,
mapping = aes(x = temps, y = moyenne_exp, couleur = sexe)) +
geom_line() +
facet_wrap(~ gène, échelles = "free_y") +
theme_bw() +
theme(panel.grid = element_blank())
ERROR
Error in ggplot(data = moyenne_exp_by_time_sex, mapping = aes(x = temps, : could not find function "ggplot"Défi
Utilisez ce que vous venez d’apprendre pour créer un graphique illustrant comment l’expression moyenne de chaque chromosome change au cours de la durée de l’infection .
R
Mean_exp_by_chromosome <- rna %>%
group_by(chromosome_name, time) %>%
summary(mean_exp = Mean(expression_log))
ERROR
Error in rna %>% group_by(chromosome_name, time) %>% summary(mean_exp = Mean(expression_log)): could not find function "%>%"R
ggplot(data = Mean_exp_by_chromosome, mapping = aes( x = temps,
y = moyenne_exp)) +
geom_line() +
facet_wrap(~ chromosome_name, scales = "free_y")
ERROR
Error in ggplot(data = Mean_exp_by_chromosome, mapping = aes(x = temps, : could not find function "ggplot"Le geom facet_wrap extrait les graphiques dans
un nombre quelconque de dimensions pour leur permettre de s’adapter
joliment à une seule page. De plus, le geom
facet_grid permet de spécifier explicitement comment les
graphiques doivent être disposés par la notation en formule
(rows ~ columns; un . peut-être utilisé comme
un raccourci pour indiquer une seule ligne ou colonne).
Modifions le graphique précédent pour comparer l’évolution de l’expression génétique moyenne des hommes et des femmes au fil du temps :
R
# Une colonne, facette par lignes
ggplot(data = Mean_exp_by_time_sex,
mapping = aes(x = time, y = Mean_exp, color = gene)) +
geom_line() +
facet_grid(sexe ~ .)
ERROR
Error in ggplot(data = Mean_exp_by_time_sex, mapping = aes(x = time, y = Mean_exp, : could not find function "ggplot"R
# Une ligne, facette par colonne
ggplot(data = Mean_exp_by_time_sex,
mapping = aes(x = time, y = Mean_exp, color = gene)) +
geom_line() +
facet_grid(. ~ sexe)
ERROR
Error in ggplot(data = Mean_exp_by_time_sex, mapping = aes(x = time, y = Mean_exp, : could not find function "ggplot"Thèmes ggplot2
En plus de theme_bw(), qui change l’arrière-plan du
graphique en blanc, ggplot2 contient plusieurs autres
thèmes qui peuvent être utiles pour changer rapidement l’apparence de
votre visualisation. La liste complète des thèmes est disponible sur https://ggplot2.tidyverse.org/reference/ggtheme.html.
theme_minimal() et theme_light() sont
populaires, et theme_void() peut être utile comme point de
départ pour créer un nouveau thème à la main.
Le package ggthemes
fournit une grande variété d’options (y compris un thème Excel 2003 ).
Le site internet des
extensions ggplot2 met à disposition une collection de
packages permettant d’étendre les fonctionnalités de
ggplot2, y compris des thèmes supplémentaires.
Personnalisation
Revenons au graphique à facettes de l’expression moyenne par temps et gène, colorée par sexe.
Consultez la ggplot2, et réfléchissez aux améliorations possibles à apporter à votre graphique.
Maintenant, nous pouvons changer les noms des axes en quelque chose de plus informatif que ‘time’ et ‘mean_exp’, et ajouter un titre à la figure :
R
ggplot(data = moyenne_exp_by_time_sex,
mapping = aes(x = temps, y = moyenne_exp, couleur = sexe)) +
geom_line() +
facet_wrap(~ gène, échelles = "free_y") +
theme_bw() +
theme(panel.grid = element_blank()) +
labs(title = "Expression moyenne des gènes selon la durée de l'infection",
x = "Durée de l'infection (en jours)",
y = "Expression moyenne des gènes")
ERROR
Error in ggplot(data = moyenne_exp_by_time_sex, mapping = aes(x = temps, : could not find function "ggplot"Les axes ont des noms plus informatifs, mais leur lisibilité peut être améliorée en augmentant la taille de la police :
R
ggplot(data = moyenne_exp_by_time_sex,
mapping = aes(x = temps, y = moyenne_exp, couleur = sexe)) +
geom_line() +
facet_wrap(~ gène, échelles = "free_y") +
theme_bw() +
theme(panel.grid = element_blank()) +
labs(title = "Expression moyenne des gènes selon la durée de l'infection",
x = "Durée de l'infection (en jours)",
y = "Expression génétique moyenne") +
theme(text = element_text(size = 16))
ERROR
Error in ggplot(data = moyenne_exp_by_time_sex, mapping = aes(x = temps, : could not find function "ggplot"Notez qu’il est également possible de changer les polices de vos
graphiques. Si vous êtes sous Windows, vous devrez peut-être installer
le package
extrafont.
Nous pouvons personnaliser davantage la couleur du texte des axes x
et y, la couleur de la grille, etc. Nous pouvons aussi par exemple
déplacer la légende vers le haut en mettant legend.position
égal à "top".
R
ggplot(data = mean_exp_by_time_sex,
mapping = aes(x = time, y = mean_exp, color = sex)) +
geom_line() +
facet_wrap(~ gene, scales = "free_y") +
theme_bw() +
theme(panel.grid = element_blank()) +
labs(title = "Mean gene expression by duration of the infection",
x = "Duration of the infection (in days)",
y = "Mean gene expression") +
theme(text = element_text(size = 16),
axis.text.x = element_text(colour = "royalblue4", size = 12),
axis.text.y = element_text(colour = "royalblue4", size = 12),
panel.grid = element_line(colour="lightsteelblue1"),
legend.position = "top")
ERROR
Error in ggplot(data = mean_exp_by_time_sex, mapping = aes(x = time, y = mean_exp, : could not find function "ggplot"Si vous aimez les modifications que vous avez créées au thème par défaut, vous pouvez les enregistrer en tant qu’objet pour pouvoir les appliquer facilement à d’autres graphiques par la suite. Voici un exemple avec l’histogramme que nous avons créé précédemment.
R
blue_theme <- theme(axis.text.x = element_text(colour = "royalblue4",
size = 12),
axis.text.y = element_text(colour = "royalblue4",
size = 12),
text = element_text(size = 16),
panel.grid = element_line(colour="lightsteelblue1"))
ERROR
Error in theme(axis.text.x = element_text(colour = "royalblue4", size = 12), : could not find function "theme"R
ggplot(rna, aes(x = expression_log)) +
geom_histogram(bins = 20) +
blue_theme
ERROR
Error in ggplot(rna, aes(x = expression_log)): could not find function "ggplot"Défi
Considérant toutes ces nouvelles informations, pourriez-vous consacrer encore cinq minutes, soit pour améliorer l’un des graphiques générés dans cet exercice, soit pour créer votre propre graphique ? Utilisez la RStudio ggplot2 pour vous en inspirer. Voici quelques idées :
- Voyez si vous pouvez modifier l’épaisseur des lignes.
- Pouvez-vous trouver un moyen de changer le nom de la légende ? Qu’en
est-il de ses labels ? (indice : recherchez une fonction ggplot
commençant par
scale_) - Essayez d’utiliser une palette de couleurs différente ou de spécifier manuellement les couleurs pour les lignes (voir http://www.cookbook-r.com/Graphs/Colors_(ggplot2)/).
Par exemple, sur la base de ce graphique :
R
ggplot(data = moyenne_exp_by_time_sex,
mapping = aes(x = temps, y = moyenne_exp, couleur = sexe)) +
geom_line() +
facet_wrap(~ gène, échelles = "free_y") +
theme_bw() +
theme(panel.grid = element_blank())
ERROR
Error in ggplot(data = moyenne_exp_by_time_sex, mapping = aes(x = temps, : could not find function "ggplot"Nous pouvons le personnaliser des manières suivantes :
R
# change the thickness of the lines
ggplot(data = mean_exp_by_time_sex,
mapping = aes(x = time, y = mean_exp, color = sex)) +
geom_line(size=1.5) +
facet_wrap(~ gene, scales = "free_y") +
theme_bw() +
theme(panel.grid = element_blank())
ERROR
Error in ggplot(data = mean_exp_by_time_sex, mapping = aes(x = time, y = mean_exp, : could not find function "ggplot"R
# change the name of the legend and the labels
ggplot(data = mean_exp_by_time_sex,
mapping = aes(x = time, y = mean_exp, color = sex)) +
geom_line() +
facet_wrap(~ gene, scales = "free_y") +
theme_bw() +
theme(panel.grid = element_blank()) +
scale_color_discrete(name = "Gender", labels = c("F", "M"))
ERROR
Error in ggplot(data = mean_exp_by_time_sex, mapping = aes(x = time, y = mean_exp, : could not find function "ggplot"R
# using a different color palette
ggplot(data = mean_exp_by_time_sex,
mapping = aes(x = time, y = mean_exp, color = sex)) +
geom_line() +
facet_wrap(~ gene, scales = "free_y") +
theme_bw() +
theme(panel.grid = element_blank()) +
scale_color_brewer(name = "Gender", labels = c("F", "M"), palette = "Dark2")
ERROR
Error in ggplot(data = mean_exp_by_time_sex, mapping = aes(x = time, y = mean_exp, : could not find function "ggplot"R
# manually specifying the colors
ggplot(data = mean_exp_by_time_sex,
mapping = aes(x = time, y = mean_exp, color = sex)) +
geom_line() +
facet_wrap(~ gene, scales = "free_y") +
theme_bw() +
theme(panel.grid = element_blank()) +
scale_color_manual(name = "Gender", labels = c("F", "M"),
values = c("royalblue", "deeppink"))
ERROR
Error in ggplot(data = mean_exp_by_time_sex, mapping = aes(x = time, y = mean_exp, : could not find function "ggplot"Composer des graphques
Le faceting est un super outil pour diviser un graphique en plusieurs sous-graphiques, mais parfois on aimerait plutôt obtenir une figure unique qui contient plusieurs graphiques indépendants, i.e. des graphiques basés sur différentes variables ou même différents data frames.
Commençons par créer les deux graphiques que nous souhaitons disposer l’un à côté de l’autre.
Le premier graphique compte le nombre de gènes uniques par
chromosome. Nous devons d’abord réorganiser les niveaux de
chromosome_name et filtrer les gènes uniques par
chromosome. Nous modifions également l’échelle de l’axe y en une échelle
log10 pour une meilleure lisibilité.
R
arn$chromosome_name <- factor(rna$chromosome_name,
niveaux = c(1:19,"X","Y"))
ERROR
Error in factor(rna$chromosome_name, niveaux = c(1:19, "X", "Y")): unused argument (niveaux = c(1:19, "X", "Y"))R
count_gene_chromosome <- rna %> % select(chromosome_name, gene) %>%
distinct() %>% ggplot() +
geom_bar(aes(x = chromosome_name), fill = "seagreen",
position = "esquive", stat = "count") +
labs(y = "log10(n gènes)", x = "chromosome") +
scale_y_log10()
ERROR
Error in rna %> % select(chromosome_name, gene) %>% distinct() %>% ggplot(): could not find function "%>%"R
count_gene_chromosome
ERROR
Error: object 'count_gene_chromosome' not foundCi-dessous, nous supprimons également complètement la légende en
mettant legend.position à"none".
R
exp_boxplot_sex <- ggplot(rna, aes(y=expression_log, x = as.factor(time),
color=sex)) +
geom_boxplot(alpha = 0) +
labs(y = "Exp moyenne du gène",
x = "time") + theme(legend.position = "none")
ERROR
Error in ggplot(rna, aes(y = expression_log, x = as.factor(time), color = sex)): could not find function "ggplot"R
exp_boxplot_sex
ERROR
Error: object 'exp_boxplot_sex' not foundLe package patchwork
fournit une approche élégante pour combiner des figures en utilisant le
« + » pour disposer les figures (typiquement côte à côte). Plus
précisément, le | les dispose explicitement côte à côte et
/ les empile les uns sur les autres .
R
install.packages("patchwork")
R
library("patchwork")
ERROR
Error in library("patchwork"): there is no package called 'patchwork'R
count_gene_chromosome + exp_boxplot_sex
ERROR
Error: object 'count_gene_chromosome' not foundR
## ou count_gene_chromosome | exp_boxplot_sex
R
count_gene_chromosome / exp_boxplot_sex
ERROR
Error: object 'count_gene_chromosome' not foundNous pouvons encore améliorer l’aspect de la composition finale avec
plot_layout pour créer des mises en page plus
complexes :
R
count_gene_chromosome + exp_boxplot_sex + plot_layout(ncol = 1)
ERROR
Error: object 'count_gene_chromosome' not foundR
count_gene_chromosome +
(count_gene_chromosome + exp_boxplot_sex) +
exp_boxplot_sex +
plot_layout(ncol = 1)
ERROR
Error: object 'count_gene_chromosome' not foundLe dernier graphique peut également être créé à l’aide des opérateurs
de composition | et /:
R
count_gene_chromosome /
(count_gene_chromosome | exp_boxplot_sex) /
exp_boxplot_sex
ERROR
Error: object 'count_gene_chromosome' not foundApprenez-en plus sur patchwork sur sa page Web ou dans cette
vidéo.
Une autre possibilité est le package
gridExtra qui permet de combiner des
ggplots séparés en une seule figure en utilisant
grid.arrange() :
R
install.packages("gridExtra")
R
library("gridExtra")
ERROR
Error in library("gridExtra"): there is no package called 'gridExtra'R
grid.arrange(count_gene_chromosome, exp_boxplot_sex, ncol = 2)
ERROR
Error in grid.arrange(count_gene_chromosome, exp_boxplot_sex, ncol = 2): could not find function "grid.arrange"En plus des arguments ncol et nrow,
utilisés pour créer des arrangements simples, il existe des outils pour
construire
des dispositions plus complexes.
Exporter des graphiques
Après avoir créé votre graphique, vous pouvez le sauvegarder dans un fichier, avec votre format préféré. L’onglet Export dans le volet Plot de RStudio enregistrera vos graphiques, mais néanmoins à basse résolution, ce qui pourrait compromettre leur publication dans de nombreuses revues et qui ne s’adaptera pas bien aux posters de grande taille.
Utilisez plutôt la fonction ggsave(), qui vous permet de
modifier facilement la dimension et la résolution de votre tracé en
modifiant les arguments appropriés (width,
height et dpi ).
Assurez-vous d’avoir le dossier fig_output/ dans votre
répertoire de travail.
R
my_plot <- ggplot(data = mean_exp_by_time_sex,
mapping = aes(x = time, y = mean_exp, color = sex)) +
geom_line() +
facet_wrap(~ gene, scales = "free_y") +
labs(title = "Mean gene expression by duration of the infection",
x = "Duration of the infection (in days)",
y = "Mean gene expression") +
guides(color=guide_legend(title="Gender")) +
theme_bw() +
theme(axis.text.x = element_text(colour = "royalblue4", size = 12),
axis.text.y = element_text(colour = "royalblue4", size = 12),
text = element_text(size = 16),
panel.grid = element_line(colour="lightsteelblue1"),
legend.position = "top")
ggsave("fig_output/mean_exp_by_time_sex.png", my_plot, width = 15,
height = 10)
# This also works for grid.arrange() plots
combo_plot <- grid.arrange(count_gene_chromosome, exp_boxplot_sex,
ncol = 2, widths = c(4, 6))
ggsave("fig_output/combo_plot_chromosome_sex.png", combo_plot,
width = 10, dpi = 300)
Remarque : Les paramètres “width” et “height” déterminent également la taille de la police dans le graphique enregistré.
Autres packages pour la visualisation
ggplot2 est un package très puissant qui s’intègre très
bien dans l’ensemble tidy data et tidy tools. Il
existe cependant d’autres packages de visualisation dans R qu’il est
intéressant de connaître également.
Base graphics
Le système graphique par défaut fourni avec R, souvent appelé
base R graphics est simple et rapide. Il est basé sur le
painter’s or canvas model, où différentes sorties sont
directement superposées les unes sur les autres (voir figure @ref(fig:paintermodel)). C’est une différence
fondamentale avec ggplot2 (et avec lattice,
décrit ci-dessous), qui renvoie des objets dédiés, qui sont visualisés à
l’écran ou dans un fichier, et qui peuvent même être modifiés.
R
par(mfrow = c(1, 3))
plot(1:20, main = "Première couche, produite avec plot(1:20)")
plot(1:20, main = "Une ligne rouge horizontale, ajoutée avec abline(h = 10)")
abline(h = 10, col = "red")
plot(1:20, main = "Un rectangle , ajouté avec rect(5, 5, 15, 15)")
abline(h = 10, col = "red")
rect(5, 5, 15, 15, lwd = 3 )
Une autre différence importante est que les fonctions de base
graphics essaient de deviner ce que l’utilisateur veut faire, en
fonction de leur type d’entrée, c’est-à-dire qu’elles adapteront leur
comportement en fonction de la classe de leur entrée. C’est encore une
fois très différent de ce que nous avons avec ggplot2, qui
n’accepte que les data frames en entrée, et qui nécessite que
les graphiques soient construits petit à petit.
R
par(mfrow = c(2, 2))
boxplot(rnorm(100),
main = "Boxplot de rnorm(100)")
boxplot(matrix(rnorm( 100), ncol = 10),
main = "Boxplot de la matrice(rnorm(100), ncol = 10)")
hist(rnorm(100))
hist( matrice(rnorm(100), ncol = 10))
ERROR
Error in matrice(rnorm(100), ncol = 10): could not find function "matrice"
L’approche ‘clé sur porte’ de base graphics peut être très
efficace pour des figures simples et standards, qui peuvent être
produites très rapidement avec une seule ligne de code et une seule
fonction telle que plot, hist, ou
boxplot, … Les valeurs par défaut ne sont cependant pas
toujours les plus pertinentes et le peaufinage des figures peut devenir
long et fastidieux, surtout lorsqu’elles deviennent plus complexes (par
exemple pour le faceting).
Le package lattice
Le package lattice est similaire à
ggplot2 dans le sens où il utilise des data frames
en entrée, renvoie des objets graphiques et prend en charge le
faceting. Cependant, lattice n’est pas basé sur la
Grammar of Graphics et a une interface plus alambiquée.
Une bonne référence pour le package lattice est @latticebook.
Key Points
- Visualisation en R
Content from Prochaines étapes
Last updated on 2025-05-05 | Edit this page
Estimated time: 90 minutes
Overview
Questions
- Qu’est-ce qu’un « SummarizedExperiment » ?
- Qu’est-ce que Bioconductor ?
Objectives
- Présenter le projet Bioconductor.
- Introduire la notion de ‘conteneurs’ de données.
- Donner un aperçu du
SummarizedExperiment, très fréquemment utilisé dans les analyses de données de type omiques.
Prochaines étapes
ERROR
Error in bibliothèque("tidyverse"): could not find function "bibliothèque"Pour faciliter l’analyse des données omiques qui sont généralement complexes, les développeurs ont défini des conteneurs spécialisés (appelés classes), spécifiquement adaptés à leurs propriétés, afin de pouvoir les stocker et les manipuler facilement.
Cet aspect est central au projet Bioconductor1 qui utilise la même infrastructure de données dans tous ses packages. Il est en effet demandé aux développeurs de packages Bioconductor d’utiliser l’infrastructure existante pour assurer la cohérence, l’interopérabilité et la stabilité du projet dans son ensemble. Ceci a d’ailleurs certainement contribué au succès de Bioconductor . Ceci a d’ailleurs certainement contribué au succès de Bioconductor .
Pour illustrer la notion de conteneur de données
omiques, nous présenterons la classe appelée
SummarizedExperiment.
SummarizedExperiment
La figure ci-dessous représente la structure de cette classe.

Les objets de la classe SummarizedExperiment contiennent :
Un (ou plusieurs) test(s) contenant les données omiques quantitatives (données d’expression), stockées sous forme d’objet de type matriciel. dans lesquelles les lignes représentent les features (les variables mesurées, comme par exemple les gènes dans le cas d’une analyse RNAseq) et les colonnes représentent les différents échantillons analysés.
Les métadonnées décrivant les échantillons sous forme d’un data frame. Les lignes de ce tableau représentent les différents échantillons (l’ordre des lignes doit correspondre exactement à l’ordre des colonnes des données d’expression).
Un slot avec les métadonnées décrivant les features sous forme d’un data frame. également. Dans cette table, les lignes représentent chaque feature et l’ordre de ces lignes doit être le même que dans la table des données d’expression. Les colonnes de cette table représentent les co-variables des features comme par exemple la localisation chromosomique des gènes, leur référence ENSEMBL ou leur fonction.
La structure coordonnée du SummarizedExperiment garantit
que lors de la manipulation des données, les dimensions des différents
slots corresponderont toujours (c’est-à-dire les colonnes des
données d’expression puis les lignes de les exemples de métadonnées,
ainsi que les lignes des données d’expression et les métadonnées des
fonctionnalités). Par exemple, si nous devions exclure un échantillon du
test, il serait automatiquement supprimé des métadonnées de
l’échantillon au cours de la même opération.
On peut par contre peut ajouter aux slots de métadonnées des co-variables supplémentaires (colonnes) sans affecter les autres structures.
Création d’un SummarizedExperiment
Afin de créer un SummarizedExperiment, nous allons
commencer par en créer les composants individuels, c’est-à-dire la
matrice de comptage, la table de métadonnées des échantillons et celle
des features. Nous allons générer ces tables à partir de
fichiers csv C’est généralement ainsi que les données RNA-Seq sont
fournies (après le traitement des données brutes).
ERROR
Error in read_csv("data/rnaseq.csv"): could not find function "read_csv"ERROR
Error in pivot_wider(select(rna, gene, sample, expression), names_from = sample, : could not find function "pivot_wider"ERROR
Error in select(counts, -gene): could not find function "select"ERROR
Error: object 'counts' not foundERROR
Error in select(rna, sample, organism, age, sex, infection, strain, time, : could not find function "select"ERROR
Error: object 'sample_metadata' not foundERROR
Error in select(rna, gene, ENTREZID, product, ensembl_gene_id, external_synonym, : could not find function "select"ERROR
Error: object 'gene_metadata' not foundERROR
Error in eval(expr, p): object 'count_matrix' not foundERROR
Error in eval(expr, p): object 'gene_metadata' not foundERROR
Error in eval(expr, p): object 'sample_metadata' not found-
Une matrice d’expression : nous chargeons la
matrice de comptage, en spécifiant que la première colonnes contient les
noms des gènes, et nous convertissons le data frame en une
matrice. Vous pouvez télécharger le data frame ici.
R
count_matrix <- read.csv("data/count_matrix.csv",
row.names = 1) %>%
as.matrix()
ERROR
Error in read.csv("data/count_matrix.csv", row.names = 1) %>% as.matrix(): could not find function "%>%"R
count_matrix[1:5, ]
ERROR
Error: object 'count_matrix' not foundR
dim(count_matrix)
ERROR
Error: object 'count_matrix' not found- Un tableau décrivant les échantillons, disponible ici.
R
sample_metadata <- read.csv("data/sample_metadata.csv")
sample_metadata
OUTPUT
sample organism age sex infection strain time tissue mouse
1 GSM2545336 Mus musculus 8 Female InfluenzaA C57BL/6 8 Cerebellum 14
2 GSM2545337 Mus musculus 8 Female NonInfected C57BL/6 0 Cerebellum 9
3 GSM2545338 Mus musculus 8 Female NonInfected C57BL/6 0 Cerebellum 10
4 GSM2545339 Mus musculus 8 Female InfluenzaA C57BL/6 4 Cerebellum 15
5 GSM2545340 Mus musculus 8 Male InfluenzaA C57BL/6 4 Cerebellum 18
6 GSM2545341 Mus musculus 8 Male InfluenzaA C57BL/6 8 Cerebellum 6
7 GSM2545342 Mus musculus 8 Female InfluenzaA C57BL/6 8 Cerebellum 5
8 GSM2545343 Mus musculus 8 Male NonInfected C57BL/6 0 Cerebellum 11
9 GSM2545344 Mus musculus 8 Female InfluenzaA C57BL/6 4 Cerebellum 22
10 GSM2545345 Mus musculus 8 Male InfluenzaA C57BL/6 4 Cerebellum 13
11 GSM2545346 Mus musculus 8 Male InfluenzaA C57BL/6 8 Cerebellum 23
12 GSM2545347 Mus musculus 8 Male InfluenzaA C57BL/6 8 Cerebellum 24
13 GSM2545348 Mus musculus 8 Female NonInfected C57BL/6 0 Cerebellum 8
14 GSM2545349 Mus musculus 8 Male NonInfected C57BL/6 0 Cerebellum 7
15 GSM2545350 Mus musculus 8 Male InfluenzaA C57BL/6 4 Cerebellum 1
16 GSM2545351 Mus musculus 8 Female InfluenzaA C57BL/6 8 Cerebellum 16
17 GSM2545352 Mus musculus 8 Female InfluenzaA C57BL/6 4 Cerebellum 21
18 GSM2545353 Mus musculus 8 Female NonInfected C57BL/6 0 Cerebellum 4
19 GSM2545354 Mus musculus 8 Male NonInfected C57BL/6 0 Cerebellum 2
20 GSM2545362 Mus musculus 8 Female InfluenzaA C57BL/6 4 Cerebellum 20
21 GSM2545363 Mus musculus 8 Male InfluenzaA C57BL/6 4 Cerebellum 12
22 GSM2545380 Mus musculus 8 Female InfluenzaA C57BL/6 8 Cerebellum 19R
dim(sample_metadata)
OUTPUT
[1] 22 9- Un tableau décrivant les gènes, disponible ici.
R
gene_metadata <- read.csv("data/gene_metadata.csv")
gene_metadata[1:10, 1:4]
OUTPUT
gene ENTREZID
1 Asl 109900
2 Apod 11815
3 Cyp2d22 56448
4 Klk6 19144
5 Fcrls 80891
6 Slc2a4 20528
7 Exd2 97827
8 Gjc2 118454
9 Plp1 18823
10 Gnb4 14696
product
1 argininosuccinate lyase, transcript variant X1
2 apolipoprotein D, transcript variant 3
3 cytochrome P450, family 2, subfamily d, polypeptide 22, transcript variant 2
4 kallikrein related-peptidase 6, transcript variant 2
5 Fc receptor-like S, scavenger receptor, transcript variant X1
6 solute carrier family 2 (facilitated glucose transporter), member 4
7 exonuclease 3'-5' domain containing 2
8 gap junction protein, gamma 2, transcript variant 1
9 proteolipid protein (myelin) 1, transcript variant 1
10 guanine nucleotide binding protein (G protein), beta 4, transcript variant X2
ensembl_gene_id
1 ENSMUSG00000025533
2 ENSMUSG00000022548
3 ENSMUSG00000061740
4 ENSMUSG00000050063
5 ENSMUSG00000015852
6 ENSMUSG00000018566
7 ENSMUSG00000032705
8 ENSMUSG00000043448
9 ENSMUSG00000031425
10 ENSMUSG00000027669R
dim(gene_metadata)
OUTPUT
[1] 1474 9Nous allons créer un SummarizedExperiment à partir de
ces tables :
La matrice de comptage sera utilisée comme assay
Le tableau décrivant les échantillons sera utilisé comme emplacement de métadonnées **sample **
Le tableau décrivant les gènes sera utilisé comme emplacement de métadonnées **features **
Nous allons assembler les différentes parties à l’aide du
constructeur SummarizedExperiment :
R
## BiocManager::install("SummarizedExperiment")
bibliothèque("SummarizedExperiment")
ERROR
Error in bibliothèque("SummarizedExperiment"): could not find function "bibliothèque"Tout d’abord, il est impératif de s’assurer que les échantillons sont dans le même ordre dans la matrice de comptage et dans les annotations des échantillons. De même, nous allons vérifier que l’ordre des gènes de la matrice de comptage correspond bien à l’ordre des gènes dans les métadonnées les décrivant.
R
stopifnot(rownames(count_matrix) == gene_metadata$gene)
ERROR
Error: object 'count_matrix' not foundR
stopifnot(colnames(count_matrix) == sample_metadata$sample)
ERROR
Error: object 'count_matrix' not foundR
se <- SummarizedExperiment(assays = list(counts = count_matrix),
colData = sample_metadata,
rowData = gene_metadata)
ERROR
Error in SummarizedExperiment(assays = list(counts = count_matrix), colData = sample_metadata, : could not find function "SummarizedExperiment"R
se
ERROR
Error: object 'se' not foundLa sauvegarde des données
L’export de données vers un tableur, comme nous l’avons fait dans un
épisode précédent, présente plusieurs limitations, comme celles décrites
dans le premier chapitre (éventuelles incohérences avec ,
et . pour les séparateurs décimaux et manque de définitions
de types de variables). De plus, l’exportation de données vers une
feuille de calcul n’est pertinente que pour les données rectangulaires
telles que les data frames et les matrices.
Une manière plus générale de sauvegarder des données, spécifique à R
et dont le fonctionnement est garanti sur n’importe quel système
d’exploitation, consiste à utiliser la fonction saveRDS() .
Cette fonction sauvegardera une représentation binaire de l’objet sur le
disque (en utilisant l’extension de fichier .rds ici), et
celle-ci pourra être rechargée dans R à l’aide de la fonction
readRDS.
R
saveRDS(se, file = "data_output/se.rds")
rm(se)
se <- readRDS("data_output/se.rds")
head(se)
Pour conclure, lorsqu’il s’agit de sauvegarder des données qui seront
re-chargées ultérieurement dans R, la sauvegarde et le chargement avec
saveRDS et readRDS sont les approches les plus
adéquates. Si les données tabulaires doivent être partagées avec
quelqu’un qui n’utilise pas R, alors l’exportation vers une feuille de
calcul sous forme de texte est une bonne alternative.
En utilisant cette structure de données, nous pouvons accéder à la
matrice d’expression avec la fonction assay() :
R
head(essai(se))
ERROR
Error in essai(se): could not find function "essai"R
dim(essai(se))
ERROR
Error in essai(se): could not find function "essai"Nous pouvons accéder aux de métadonnées des échantillons à l’aide de
la fonction colData :
R
colData(se)
ERROR
Error in colData(se): could not find function "colData"R
dim(colData(se))
ERROR
Error in colData(se): could not find function "colData"Nous pouvons également accéder aux métadonnées des features
à l’aide de la fonction rowData() :
R
head(rowData(se))
ERROR
Error in rowData(se): could not find function "rowData"R
dim(rowData(se))
ERROR
Error in rowData(se): could not find function "rowData"Sous-ensemble d’un SummarizedExperiment
Il est possible d’extraire un sous-ensemble d’un SummarizedExperiment exactement de la même manière que pour un data frame, en utilsant des indices ou des caractères logiques.
Ci-dessous, nous allons créer par exemple un nouveau SummarizedExperiment qui ne contient que les 5 premiers gènes et les 3 premiers échantillons.
R
se1 <- se[1:5, 1:3]
ERROR
Error: object 'se' not foundR
se1
ERROR
Error: object 'se1' not foundR
colData(se1)
ERROR
Error in colData(se1): could not find function "colData"R
rowData(se1)
ERROR
Error in rowData(se1): could not find function "rowData"Nous pouvons également utiliser la fonction colData()
pour créer un sous-ensemble basé sur une caractéristique des
échantillons, ou la fonction rowData() pour créer un
sous-ensemble basé sur une caractéristique des gènes. Dans l’exemple
ci-dessous, nous n’allons conserver que les gènes correspondant à des
miRNAs et uniquement les échantillons non-infectés :
R
se1 <- se[rowData(se)$gene_biotype == "miRNA",
colData(se)$infection == "NonInfected"]
ERROR
Error: object 'se' not foundR
se1
ERROR
Error: object 'se1' not foundR
assay(se1)
ERROR
Error in assay(se1): could not find function "assay"R
colData(se1)
ERROR
Error in colData(se1): could not find function "colData"R
rowData(se1)
ERROR
Error in rowData(se1): could not find function "rowData"Défi
Extraire les niveaux d’expression génique des 3 premiers gènes dans les échantillons collectés au temps 0 et au temps 8.
R
assay(se)[1:3, colData(se)$time != 4]
ERROR
Error in assay(se): could not find function "assay"R
# Equivalent to
assay(se)[1:3, colData(se)$time == 0 | colData(se)$time == 8]
ERROR
Error in assay(se): could not find function "assay"Défi
Vérifiez que vous obtenez les mêmes valeurs en utilisant la longue
table rna.
R
arn |>
filtre(gène %in% c("Asl", "Apod", "Cyd2d22")) |>
filtre(temps != 4) |> select(expression )
ERROR
Error in select(filtre(filtre(arn, gène %in% c("Asl", "Apod", "Cyd2d22")), : could not find function "select"La table en format long et le SummarizedExperiment
contiennent les mêmes informations, mais sont simplement structurés
différemment. Chaque structure a ses avantages propres: la première
convient bien aux packages tidyverse, tandis que
la seconde est une structure adéquate pour faciliter l’analyse et le
traitement statistique de nombreuses données omiques. Le
SummarizedExperiment est par exemple utilisé lors des
analyses de RNA-seq avec le package DESeq2.
Ajouter des variables aux métadonnées
Comme mentionné ci-dessus, il est possible d’ajouter des informations aux métadonnées. Supposons que vous souhaitiez ajouter le centre où les échantillons ont été collectés…
R
colData(se)$center <- rep("Université de l'Illinois", nrow(colData(se)))
ERROR
Error in colData(se): could not find function "colData"R
colData(se)
ERROR
Error in colData(se): could not find function "colData"Cela illustre le fait que les slots de métadonnées peuvent croître indéfiniment sans affecter les autres structures !
TidyRésuméExpérience
Vous vous demandez peut-être si pouvons-nous utiliser les commandes
Tidyverse pour interagir avec les objets
SummarizedExperiment ? La réponse est oui, nous pouvons le
faire grâce au package tidySummarizedExperiment.
Rappelez-vous à quoi ressemble notre objet SummarizedExperiment :
R
se
ERROR
Error: object 'se' not foundChargez tidySummarizedExperiment puis jetez à nouveau un
œil à l’objet se .
R
#BiocManager::install("tidySummarizedExperiment")
library("tidySummarizedExperiment")
ERROR
Error in library("tidySummarizedExperiment"): there is no package called 'tidySummarizedExperiment'R
se
ERROR
Error: object 'se' not foundIl s’agit toujours d’un objet SummarizedExperiment, il
conserve donc sa structure spécifique, mais nous pouvons maintenant le
voir comme un tibble. Notez la première ligne de la sortie dit
ceci, c’est une abstraction
SummarizedExperiment-tibble . Nous pouvons
également voir dans la deuxième ligne affichée le nombre de gènes et
d’échantillons.
Si nous voulons revenir à la vue standard
SummarizedExperiment, nous pouvons le faire.
R
options("restore_SummarizedExperiment_show" = TRUE)
se
ERROR
Error: object 'se' not foundMais ici, nous restons sur la vue tibble.
R
options("restore_SummarizedExperiment_show" = FALSE)
se
ERROR
Error: object 'se' not foundNous pouvons maintenant utiliser les commandes Tidyverse pour
interagir avec l’objet SummarizedExperiment.
Nous pouvons utiliser filter pour filtrer les lignes en
utilisant une condition, par exemple pour afficher toutes les lignes
pour un échantillon.
R
se %>% filtre(.sample == "GSM2545336")
ERROR
Error in se %>% filtre(.sample == "GSM2545336"): could not find function "%>%"Nous pouvons utiliser « select » pour spécifier les colonnes que nous voulons afficher.
R
se %>% sélectionner (.sample)
ERROR
Error in se %>% sélectionner(.sample): could not find function "%>%"Nous pouvons utiliser mutate pour ajouter des
informations sur les métadonnées.
R
se %>% muter(center = "Université de Heidelberg")
ERROR
Error in se %>% muter(center = "Université de Heidelberg"): could not find function "%>%"Nous pouvons également combiner des commandes avec le pipe
‘%>%’ de tidyverse . Pour l’exemple de , nous pourrions combiner
group_by et summarise pour obtenir le nombre
total de pour chaque échantillon.
R
se %>%
group_by(.sample) %>%
summarise(total_counts=sum(counts))
ERROR
Error in se %>% group_by(.sample) %>% summarise(total_counts = sum(counts)): could not find function "%>%"Nous pouvons également utiliser l’objet
SummarizedExperiment comme un tibble classique
pour la visualisation.
Ici, nous traçons la distribution des comptes par échantillon.
R
se |>
ggplot(aes(counts + 1, group=.sample, color=infection)) +
geom_density() +
scale_x_log10() +
theme_bw()
ERROR
Error in ggplot(se, aes(counts + 1, group = .sample, color = infection)): could not find function "ggplot"Pour plus d’informations sur TidySummarizedExperiment,
consultez le site Web du package ici.
A retenir
Le
SummarizedExperimentest un moyen très efficace de stocker et de gérer les données omiques.Les
SummarizedExperimentssont utilisés dans de nombreux packages Bioconductor.
Si vous suivez la prochaine formation axée sur l’analyse de
séquençage d’ARN, vous apprendrez à utiliser le package Bioconductor
DESeq2 pour faire des analyses d’expression différentielle.
Ce package utilise un SummarizedExperiment pour
traiter l’ensemble des données.
Key Points
- Bioconductor est un projet qui fournit un cadre et des packages pour faciliter l’analyse et l’interprétation des données issues de la biologie à haut débit.
- Un
SummarizedExperimentest un type d’objet particulièrement utile pour stocker et traiter ce type de donnée.
Le projet Bioconductor a été initié par Robert Gentleman, l’un des deux créateurs du langage R . Bioconductor utilise le langage R pour fournir des outils dédiés à l’analyse des données omiques. Bioconductor est open source et open development.↩︎