RStudioプロジェクトと実験データ
Last updated on 2025-11-11 | Edit this page
Estimated time 30 minutes
Overview
Questions
- RStudioプロジェクトを使用して分析プロジェクトを管理するにはどうすればよいですか?
- 分析プロジェクトのためのディレクトリを効果的に整理する方法は?
- インターネットからデータセットをダウンロードして、ファイルとして保存する方法。
Objectives
- RStudioプロジェクトを作成し、分析プロジェクトに関連するファイルを保存するためのディレクトリを作成します。
- 次のエピソードで使用するデータセットをダウンロードします。
イントロダクション
通常、分析プロジェクトは、データセットファイル、いくつかのRスクリプト、そして出力ファイルが含まれたディレクトリから始まります。
プロジェクトが進むにつれ、より多くのスクリプト、出力ファイルおよびおそらく新しいデータセットの追加により、複雑さは避けられません。
複数のバージョンのスクリプトや出力ファイルを扱う際には、複雑さがさらに増すため、効率的な組織が必要です。
これらが最初からうまく管理されていないと、プロジェクトを休止した後に再開することや、プロジェクトを他の人と共有することは困難かつ時間を要します。
さらに、適切な整理がなければ、プロジェクトの複雑さが頻繁にsetwd関数を使用して異なる作業ディレクトリ間を切り替えることにつながり、無秩序な作業スペースが生じます。
このレッスンでは、最初にデータ分析プロジェクトで使用し生成されたファイルを、_作業ディレクトリ_内で管理するための効果的な戦略に焦点を当てます。
作業ディレクトリとは何ですか?
Rにおける作業ディレクトリは、Rがファイルを読み込んだり保存したりするために探すコンピュータ上のデフォルトの場所です。 詳細は、私たちの データ分析のためのRとBioconductorの紹介 レッスンにあります。
次に、RStudioに組み込まれた分析プロジェクトを管理するための機能であるRStudioプロジェクトを活用する方法を学びます。
RStudioとは何ですか?
RStudioは、科学者やソフトウェア開発者によって広く使われる無料の統合開発環境(IDE)で、ソフトウェアの開発やデータセットの分析に使用されます。 RStudioまたはその一般的な使用に関する支援が必要な場合は、私たちの データ分析のためのRとBioconductorの紹介 レッスンをご参照ください。
最後に、このレッスンでは、次のエピソードのためのデータをダウンロードするためにR関数download.fileを使用する方法も学びます。
作業ディレクトリの構造
より効率的なワークフローのために、分析に関連付けられたすべてのファイルを特定のディレクトリに保存することをお勧めします。これは、プロジェクトの作業ディレクトリとして機能します。 最初に、この作業ディレクトリには4つの異なるディレクトリが含まれている必要があります:
-
data: 生のデータを格納するために専用。 このフォルダには、生データだけを保存し、データセットが新たに受信されるまで修正しないのが理想的です(それでも、ストレージ容量があれば、将来また必要になる可能性があるため、以前のデータセットも保持することをお勧めします)。 RNA-seqデータ分析の場合、このディレクトリには通常、*.fastqファイルや実験に関連するメタデータファイルが含まれます。 -
scripts: データ分析のために作成したRスクリプトを保存するため。 -
documents: 分析に関連する文書を保存するため。 原稿のアウトラインやチームとのミーティングノートなど。 -
output:scriptsディレクトリ内のRスクリプトによって生成された中間または最終結果を保存するため。 重要なことは、データクリーニングまたは前処理を行う場合、出力はこのディレクトリに保存されるべきであり、これによりもはや生データとは見なされません。
プロジェクトが複雑になるにつれ、追加のディレクトリまたはサブディレクトリを作成する必要があるかもしれません。 それでも、上記の4つのディレクトリは作業ディレクトリの基盤として機能するべきです。
次のエピソードのためのディレクトリを作成する
このエピソードとレッスンの残りの部分のために作業ディレクトリとするために、コンピュータ上にディレクトリを作成します(ワークショップの例ではbio_rnaseqという名前のディレクトリを使用します)。
次に、この選択したディレクトリ内に、前述の4つの基本的なディレクトリ(data、scripts、documents、およびoutput)を作成します。
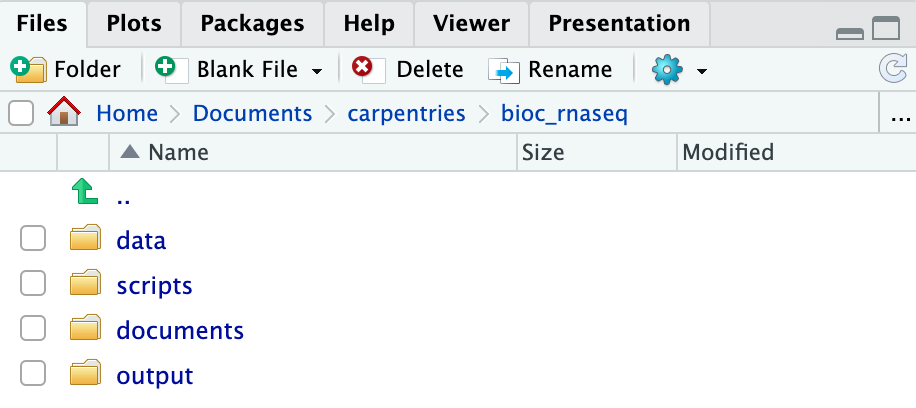
RStudioプロジェクトを使用して作業ディレクトリを管理する
前述の通り、RStudioプロジェクトは、分析プロジェクトを管理するためにRStudioに組み込まれた機能です。
それは、プロジェクト特有の設定を作業ディレクトリ内に保存された.Rprojファイルに保存することで実現します。
.Rprojファイルを直接開くか、RStudioのプロジェクトを開くオプションを通じてこれらの設定をRStudioにロードすると、Rの作業ディレクトリが.Rprojファイルの場所、すなわちプロジェクトの作業ディレクトリに自動的に設定されます。
RStudioプロジェクトを作成するには:
- RStudioを開始します。
- メニューバーに移動し、
File>New Project...を選択します。 -
Existing Directoryを選択します。 -
Browse...ボタンをクリックし、分析のために以前選択した作業ディレクトリを選択します(つまり、4つの必須ディレクトリが存在するディレクトリ)。 - ウィンドウの右下にある
Create Projectをクリックします。
上記のステップを完了すると、プロジェクトの作業ディレクトリ内に.Rprojファイルが見つかります。
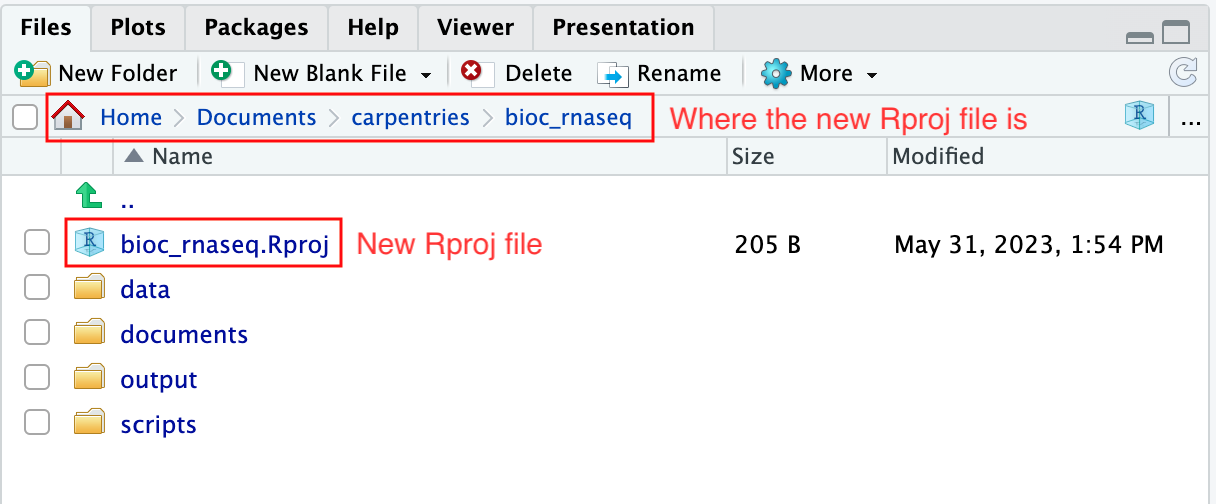
さらに、RStudioコンソールのヘッディングには、.Rprojファイルの存在するプロジェクトの作業ディレクトリの絶対パスが表示されます。RStudioがこのディレクトリをRの作業ディレクトリとして設定したことを示しています。
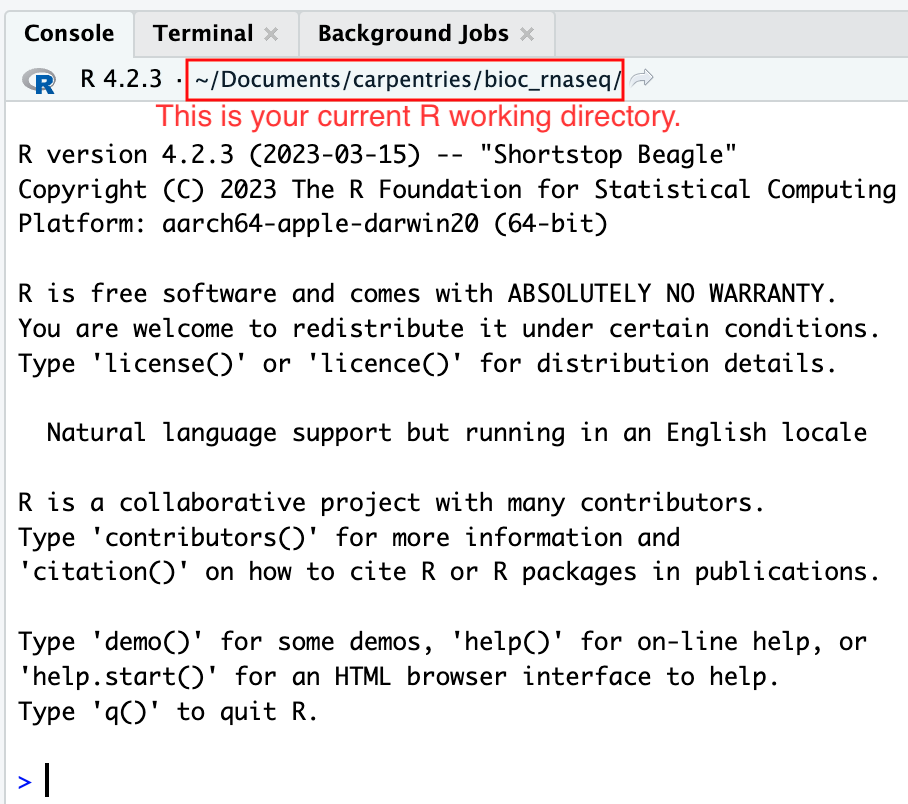
この時点から、読み込むデータがファイルから、またはファイルにデータを保存するRコードを実行すると、それはデフォルトでプロジェクトの作業ディレクトリに相対するパスに向けられます。
プロジェクトを閉じる場合、別のプロジェクトを開くため、新しいプロジェクトを作成するため、またはプロジェクトを一時的に休むためには、メニューバーにあるFile
> Close Projectオプションを使用します。
プロジェクトを再度開くには、作業ディレクトリ内の.Rprojファイルをダブルクリックするか、RStudioを開いてメニューバーのFile
> Open Projectオプションを使用します。
次のエピソードのためにRNA-seqデータをダウンロードする
最後に、私たちは次のエピソードのために必要なRNA-seqデータをダウンロードするためのRの使用方法を学びます。 使用するデータセットは、上気道感染がマウスの小脳および脊髄におけるRNA転写の変化に与える影響を調査するために生成されました。 このデータセットは、次の研究の一部として作成されました:
Blackmore、Stephenら。“インフルエンザ感染は、実験的自己免疫脳脊髄炎の遺伝子モデルにおいて疾患を引き起こします。” 国立科学アカデミー紀要114.30 (2017): E6107-E6116。
データセットはGene Expression Omnibus (GEO)で利用可能で、アクセッション番号はGSE96870です。 GEOからデータをダウンロードすることは簡単ではなく(このレッスンでは扱われません)。 そのため、アクセスが簡単なようにデータをGitHubリポジトリに公表しました。
ファイルをダウンロードするために、私たちはR関数download.fileを使用します。この関数は少なくとも2つのパラメータを必要とします:urlとdestfile。
urlパラメータは、データをダウンロードするためのインターネット上のアドレスを指定するために使用されます。
destfileパラメータは、ダウンロードしたファイルをどこに保存するか、そしてダウンロードしたファイルにどのように名前を付けるかを示します。
このレッスンの残りの部分で必要な4つのデータファイルのうちの1つをダウンロードしてみましょう。
データファイルはhttps://github.com/carpentries-incubator/bioc-rnaseq/raw/main/episodes/data/GSE96870_counts_cerebellum.csvにあります。
ダウンロードしたファイルを作業ディレクトリのdataフォルダにGSE96870_counts_cerebellum.csvという名前で保存します。
R
download.file(
url = "https://github.com/carpentries-incubator/bioc-rnaseq/raw/main/episodes/data/GSE96870_counts_cerebellum.csv",
destfile = "data/GSE96870_counts_cerebellum.csv"
)
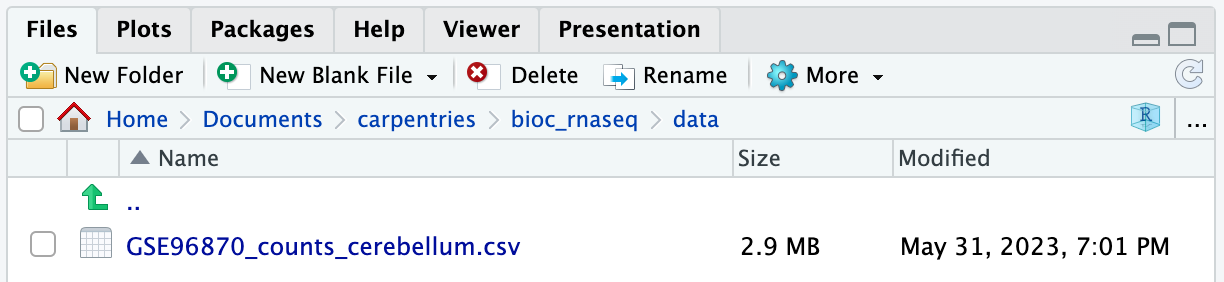
作業ディレクトリのdataフォルダに移動すると、GSE96870_counts_cerebellum.csvという名前のファイルが見つかるはずです。
残りのデータセットファイルをダウンロードする
このレッスンの残りの部分に必要なデータセットファイルがあと3つあります。
| URL | ファイル名 |
|---|---|
| https://github.com/carpentries-incubator/bioc-rnaseq/raw/main/episodes/data/GSE96870_coldata_cerebellum.csv | GSE96870_coldata_cerebellum.csv |
| https://github.com/carpentries-incubator/bioc-rnaseq/raw/main/episodes/data/GSE96870_coldata_all.csv | GSE96870_coldata_all.csv |
| https://github.com/carpentries-incubator/bioc-rnaseq/raw/main/episodes/data/GSE96870_rowranges.tsv | GSE96870_rowranges.tsv |
download.file関数を使用して、作業ディレクトリのdataフォルダにファイルをダウンロードします。
R
download.file(
url = "https://github.com/carpentries-incubator/bioc-rnaseq/raw/main/episodes/data/GSE96870_coldata_cerebellum.csv",
destfile = "data/GSE96870_coldata_cerebellum.csv"
)
download.file(
url = "https://github.com/carpentries-incubator/bioc-rnaseq/raw/main/episodes/data/GSE96870_coldata_all.csv",
destfile = "data/GSE96870_coldata_all.csv"
)
download.file(
url = "https://github.com/carpentries-incubator/bioc-rnaseq/raw/main/episodes/data/GSE96870_rowranges.tsv",
destfile = "data/GSE96870_rowranges.tsv"
)
- プロジェクトに必要なファイルを作業ディレクトリに適切に整理することは、秩序を維持し、将来のアクセスを容易にするために重要です。
- RStudioプロジェクトは、プロジェクトの作業ディレクトリを管理し、分析を促進するための貴重なツールとして機能します。
- Rにおける
download.file関数は、インターネットからデータセットをダウンロードするために使用できます。