スプレッドシートを使用したデータ整理
Last updated on 2026-04-28 | Edit this page
Overview
Questions
- 表形式のデータを整理するにはどうすればよいですか?
Objectives
- スプレッドシートとその長所と短所について学びます。
- データを効果的に使用するには、スプレッドシート内のデータをどのようにフォーマットすればよいでしょうか?
- 一般的なスプレッドシートのエラーとその修正方法について説明します。
- tidy data の原則に従ってデータを整理します。
- カンマ区切り (CSV) 形式やタブ区切り (TSV) 形式などのテキストベースのスプレッドシート形式について説明します。
This episode is based on the Data Carpentries’s Data Analysis and Visualisation in R for Ecologists lesson.
表計算プログラム
質問
- 優れたデータ統合用にスプレッドシートを使用するための基本的な原則は何でしょうか?
目的
- コンピュータがデータセットを最大限に活用できるようにデータを整理するためのベストプラクティスについて説明してみましょう。
キーポイント
- 適切なデータ構成は、あらゆる研究プロジェクトの基礎です。
適切なデータ整理は研究プロジェクトの基盤です。 多くの研究者は、スプレッドシートでデータを保管したり、データ入力を行ったりしています。 スプレッドシートプログラムは、データテーブルの設計や基本的なデータ品質管理機能の操作に非常に便利なグラフィカルインターフェースです。 @Broman:2018 も参照してください。
スプレッドシートの概要
スプレッドシートはデータ入力作業に非常に適しています。 そのため、多くのデータがスプレッドシート形式で管理されています。 研究者としての時間の多くは、この「データ整理」段階に費やされることになるでしょう。 最も楽しい作業とは言えないかもしれませんが、これは必要不可欠なプロセスです。 本コースでは、データの整理方法についての考え方や、より効率的なデータ処理のための実践的な手法を体系的に学んでいただきます。
このレッスンで教えられないこと
- スプレッドシートでの統計処理の方法
- スプレッドシートでのグラフ作成の方法
- スプレッドシート用プログラムでのコード記述の方法
これらの作業を行いたい場合、 O’Reilly社発行の『Head First Excel』 が優れた参考書としておすすめです。
なぜスプレッドシートでのデータ分析を教えないのか
スプレッドシートを用いたデータ分析では、通常多大な手作業が必要です。パラメータを変更したり新しいデータセットで分析を実行する場合、通常は最初からすべて手作業でやり直す必要があります。(マクロを作成できることは承知していますが、次のポイントを参照してください)
スプレッドシートプログラムで行った統計分析やグラフ作成の過程を追跡・再現することも困難です。後で作業内容を確認したい場合や、他者から分析の詳細を求められた場合などに問題となります。
数多くのスプレッドシートプログラムが利用可能です。参加者の多くが主要なスプレッドシートツールとしてExcelを使用しているため、本レッスンでは主にExcelの事例を取り上げます。同様に使用できる無料のスプレッドシートプログラムとしてはLibreOfficeがあります。コマンドの表記方法はプログラムによって若干異なる場合がありますが、基本的な概念は共通しています。
スプレッドシートプログラムは、研究者として必要な多くの作業をカバーしています。具体的には以下の用途に活用できます:
- データ入力
- データの整理
- データのサブセット作成と並べ替え
- 統計分析
- グラフ作成
スプレッドシートプログラムでは、データを表形式で表現・表示します。表形式でフォーマットされたデータはこの章の主要なテーマでもあり、効率的な下流工程の分析を可能にするため、データを標準化された方法で表形式に整理する方法について解説します。
課題: 隣の人と次の点について話し合ってください。
- 研究や授業、家庭などで表計算ソフトを使用したことはありますか?
- 表計算ソフトではどのような操作を行いますか?
- 表計算ソフトが特に適していると思う用途は何だと思いますか?
- 表計算ソフトを使用している際に、誤って操作してしまい、イライラしたりがっかりした経験はありますか?
スプレッドシートの問題
スプレッドシートはデータ入力には適していますが、実際にはデータ入力以外の用途でも頻繁に使用されます。 出版物用のデータ表作成、要約統計量の生成、図表の作成など、さまざまな用途に活用されています。
スプレッドシートで出版用の表を作成するのは最適な方法とは言えません。 データ表を出版用にフォーマットする際、通常は主要な要約統計量をデータとして直接読むことを目的とした形式で表示することは少なく、多くの場合特別な書式設定(セルの結合、枠線の設定、見栄えの調整など)が必要となります。 このような作業は、文書編集ソフトウェア内で行うことをおすすめします。
統計値の生成と図表作成という後半の2つの用途については、注意が必要です。 スプレッドシートソフトのグラフィカルでドラッグ&ドロップ操作が可能な性質のため、特に複雑な計算が必要な場合、自身の操作手順を再現すること(ましてや他者の手順を追跡すること)は非常に困難です。 さらに、スプレッドシートで計算を行う際には、隣接する複数のセルにわずかに異なる計算式を誤って適用してしまうリスクがあります。 RやSASのようなコマンドラインベースの統計処理プログラムを使用する場合、意図的に行わない限り、データセット内のある観測値にのみ計算を適用し、別の観測値には適用しないという操作はほぼ不可能です。
スプレッドシートにおけるデータ表のフォーマット
質問事項
- 効果的なデータ活用のために、スプレッドシートでデータをどのようにフォーマットすべきか?
学習目標
スプレッドシートにおけるデータ入力とフォーマットに関するベストプラクティスを説明する
変数と観測値をスプレッドシート上で適切に整理するためのベストプラクティスを適用する
重要ポイント
生データは絶対に改変しないこと。変更を加える前に必ずコピーを作成すること
データクリーニングの全工程をプレーンテキストファイルに記録しておくこと
「Tidy Data」の原則に従ってデータを整理すること
最もよくある誤りは、スプレッドシートを実験ノートのように扱ってしまうことです。つまり、文脈や余白の注釈、データやフィールドの空間配置に依存して情報を伝えようとすることです。人間であればこれらの要素を(通常は)解釈できますが、コンピュータは人間とは異なる方法で情報を処理します。すべての要素が何を意味するのかを明確に指示しない限り(これは非常に困難な場合もあります)、コンピュータはデータの関連性を正しく把握できません。
コンピュータの処理能力を活用することで、データ管理と分析をはるかに効果的かつ迅速に行うことが可能になります。ただし、この能力を活用するためには、コンピュータが理解できるようにデータを適切な形式で設定する必要があります(コンピュータは非常に文字通りの解釈をする性質があるため)。
このため、最初から適切にフォーマットされたテーブルを設定することが極めて重要です。最初の予備実験データを入力する前から、データの整理を始めるべきです。データの整理方法は研究プロジェクトの基盤となります。分析作業全体を通じてデータを扱う際の効率性を大きく左右するため、データ入力時や実験セットアップ時に十分に検討する価値があります。スプレッドシートでは様々な方法でデータを設定できますが、これらの選択によっては、他のプログラムでデータを操作する能力が制限されたり、6ヶ月後の自分や共同研究者がデータを扱う際に問題が生じる可能性があります。
注記: データ入力とデータ分析に最適なレイアウト/フォーマット(ならびにソフトウェアやインターフェース)は、場合によって異なる場合があります。この点を考慮に入れ、理想的にはある形式から別の形式への自動変換を設定しておくことが重要です。
分析結果の管理方法
スプレッドシートを扱う際、データのクリーニングや分析作業を行っていると、最初に作成した状態とは大きく異なるシートになってしまうことがよくあります。分析結果を再現したり、査読者や指導者から別の分析方法を求められた場合に備えて、以下の点に留意してください:
クリーニング済みまたは分析済みデータの新しいファイルを作成すること。元のデータセットは変更しないでください。そうしないと、作業の起点が分からなくなってしまいます!
データクリーニングや分析の各工程を記録すること。これらの手順は、実験の各ステップと同様に記録する必要があります。データファイルと同じフォルダに保存したプレーンテキストファイルで管理することをお勧めします。
以下に、スプレッドシートの設定例を示します:
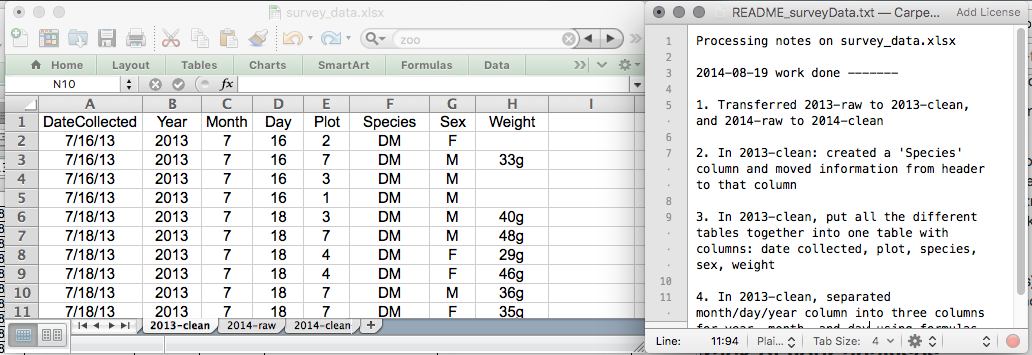
これらの原則を、今日の演習で実践してみてください。
本コースではバージョン管理については扱いませんが、データのバージョン管理方法については、「Carpentries」の「Git」レッスン Gitを参照してください。また、簡単なチュートリアルとしてこのブログ記事や、より研究指向の使用事例として@Perez-Riverol:2016も参考になるでしょう。
スプレッドシートにおけるデータの構造化
スプレッドシートプログラムをデータ処理に使用する際の基本原則:
- すべての変数を列に配置すること - 「体重」や「温度」など、測定対象の項目をここに記入します。
- 各観測データをそれぞれ別の行に配置すること。
- 一つのセルに複数の情報をまとめないこと。一見一つの項目のように見えても、将来的にそのデータをどのように使用・整理したいかを考えてください。
- 生データはそのままの状態で保持すること - 決して変更しないでください!
- クリーニング済みデータはCSV(カンマ区切り値)形式などのテキストベース形式でエクスポートすること。これにより、誰でもデータを利用できるようになり、ほとんどのデータリポジトリでこの形式が要求されています。
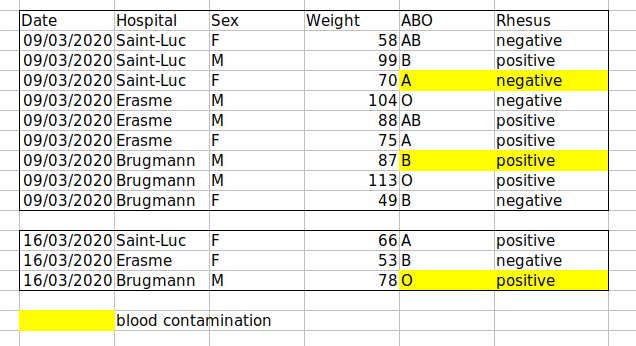
例えば、ベルギー・ブリュッセルの複数の病院で受診した患者データがあるとします。このデータには、受診日、病院名、患者の性別、体重、血液型が記録されています。
もしデータをこのように管理した場合:
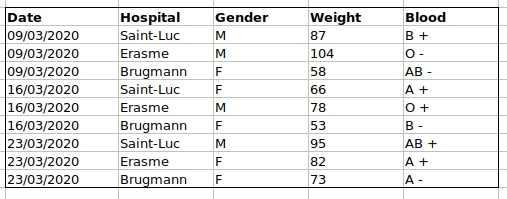
問題は、ABO型とRh因子が同じ「Blood」タイプの列に混在していることです。例えば、Aグループの全症例を調べたい場合や、ABO型別の体重分布を分析したい場合、このデータ構成では作業が困難になります。代わりに、ABO型とRh因子を別々の列に配置すれば、はるかに簡単に作業できるようになります。
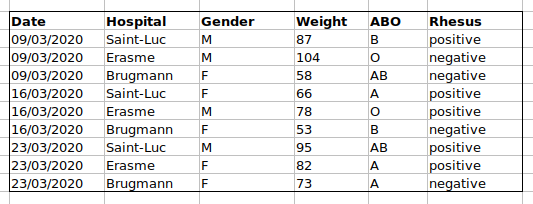
データシートを設定する際の重要なルールは、列は変数に、行は観測データに使用するということです:
- 列は変数を表す
- 行は観測データを表す
- セルは個々の値を表す
課題:整理されていないデータセットを扱い、それをどのようにクリーニングするか説明してください。
このリンクをクリックして、整理されていないデータセットをダウンロードしてください。
スプレッドシートソフトウェアでデータを開いてください。
データには2つのタブがあることがわかります。このデータセットには、2020年の第1波と第2波の期間中にブリュッセルの様々な病院で記録された多様な臨床変数が含まれています。ご覧の通り、データは2020年3月と11月の波で異なる形式で記録されています。あなたは現在このプロジェクトの責任者であり、データの分析を開始できるようにしたいと考えています。
隣にいる人と協力して、このスプレッドシートの問題点を特定してください。また、第1波と第2波のタブをクリーニングするために必要な手順、およびそれらを1つのスプレッドシートに統合する方法についても議論してください。
重要事項: 最初のアドバイスを必ず守ってください:クリーニング済みデータ用の新しいファイル(またはタブ)を作成する際には、元の生データを一切変更しないでください。
この演習を終えた後、グループでこのデータの問題点とそれを修正する方法について議論します。
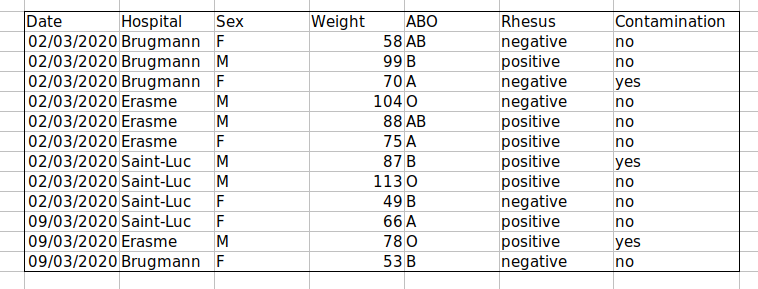
課題:データを整理した後、以下の質問に答えてください:
- 研究に参加した男性と女性はそれぞれ何人ですか?
- A型、AB型、B型の検体はそれぞれいくつ検査されましたか?
- 上記と同様ですが、汚染された検体は除外した場合の数値は?
- Rhesus陽性(+)と陰性(-)の検体はそれぞれいくつ検査されましたか?
- ユニバーサルドナー(O型・マイナス)の検体はいくつ検査されましたか?
- AB型男性の平均体重はいくらですか?
- 異なる病院で検査された検体数はいくつですか?
Rスクリプトに関する優れた参考資料として、特にWickhamによる2014年の論文『Tidy Data』が挙げられます。
スプレッドシート使用時によくある誤り
質問
- スプレッドシートでデータをフォーマットする際によくある問題点と、それらを回避する方法を教えてください。
目的
- スプレッドシートのフォーマットに関する一般的な問題を認識し、適切に対処できるようになること。
重要ポイント
- 1つのスプレッドシート内に複数のテーブルを混在させないこと。
- データを複数のタブに分散させないこと。
- 0値は0として正確に記録すること。
- 欠損データは適切な欠損値マーカーで記録すること。
- フォーマット機能を情報伝達や見た目の装飾目的で使用しないこと。
- コメントは別の列に記入すること。
- 列ヘッダーには単位を明記すること。
- 1つのセルには1種類の情報のみを記録すること。
- 列ヘッダーにはスペース、数字、特殊文字を使用しないこと。
- データ内に特殊文字を使用しないこと。
- メタデータは別ファイルのプレーンテキスト形式で記録すること。
データ解析においては、自身のデータだけでなく、共同研究者やインターネットから入手したデータにもいくつかの潜在的なエラーが存在する可能性があります。これらのエラーと、下流工程のデータ分析や結果解釈に及ぼす悪影響を認識していれば、自身やプロジェクトメンバーの意識を高め、これらのエラーを回避しようとする動機付けとなるでしょう。スプレッドシートにおけるデータの書式設定をわずかに変えるだけでも、データクリーニングや分析の効率性と信頼性に大きな影響を与えることができます。
- 複数のテーブルを使用する場合
- 複数のタブを使用する場合
- ゼロ値を入力しない場合
- 問題のあるNULL値を使用する場合
- 情報伝達のための書式設定を使用する場合
- データシートを見栄え良くするための書式設定を使用する場合
- セル内にコメントや単位を記載する場合
- 1つのセルに複数の情報を記載する場合
- 問題のあるフィールド名を使用する場合
- データに特殊文字を使用する場合
- データテーブルにメタデータを含める場合
複数のテーブルを使用する場合
よくある間違いとして、1つのスプレッドシート内に複数のデータテーブルを作成する方法があります。これはコンピュータにとって混乱を招くため、絶対に避けるべきです。1つのスプレッドシート内に複数のテーブルを作成すると、コンピュータに対して誤った関連性を示唆することになり、各行を個別の観測値として認識してしまいます。また、同じフィールド名を複数の場所で使用することで、データを実用的な形式に整理する際の手間が増える可能性があります。以下の例がこの問題を説明しています:
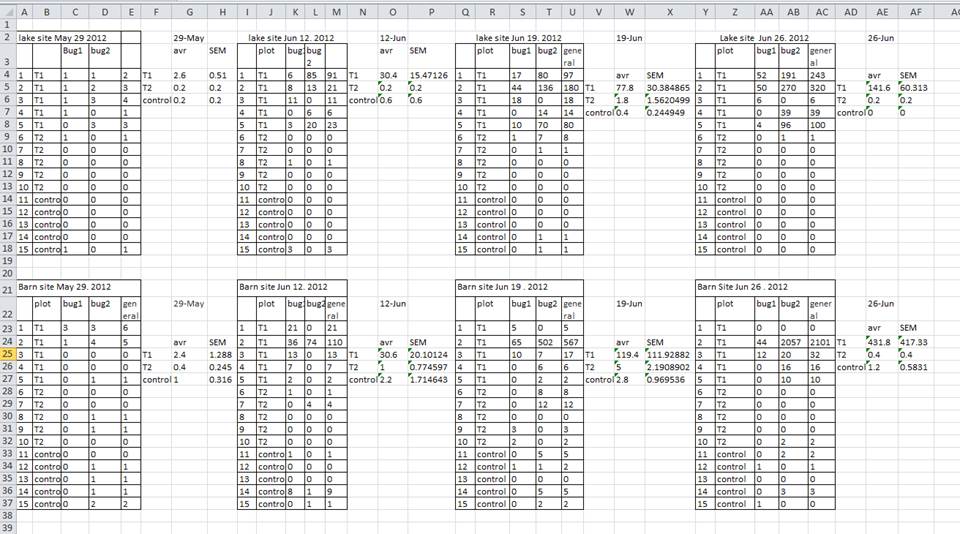
上記の例では、コンピュータは例えば4行目を見て、A列からAF列までがすべて同じサンプルを指していると解釈してしまいます。実際には、この行は4つの異なるサンプル(5月29日、6月12日、6月19日、6月26日の4つの異なる採取日におけるサンプル1)と、そのうち2つのサンプルについての計算された要約統計量(平均値(avr)と測定値の標準誤差(SEM))を含んでいます。他の行も同様に問題を含んでいます。
複数のタブを使用する場合
では、ワークブックのタブはどうでしょう?データを整理する簡単な方法のように思えますが、実はそうでもありません。追加のタブを作成すると、データ内に存在する関連性をコンピュータが認識できなくなります(この関連性を確保するためには、スプレッドシートアプリケーション固有の関数やスクリプトを導入する必要があります)。例えば、測定を行う日ごとに別々のタブを作成する場合を考えてみましょう。
これは2つの理由で適切な方法とは言えません:
測定を行うたびに新しいタブにデータを記録し始めると、データに不整合が意図せず混入する可能性が高くなります
たとえすべての不整合を防ぐことができたとしても、データを分析する前に追加の手順が必要になります。これらのデータを単一のデータテーブルに統合しなければならず、コンピュータに対してタブの結合方法を明示的に指示する必要があります。さらに、タブの書式が不統一な場合、手動での作業が必要になることもあります。
次にデータを入力する際に、新しいタブやテーブルを作成しようと考えた時、元のスプレッドシートに別の列を追加するだけでこのタブを追加せずに済む方法がないか考えてみてください。私たちは以前、整理されていないデータファイルの例として複数のタブを使用していましたが、今ではタブを統合してデータを整理する方法をご理解いただけたでしょう。
実験が進むにつれ、データシートは非常に長くなることがあります。これにより、スプレッドシートの上部にあるヘッダーが見えにくくなり、データ入力が困難になる場合があります。ただし、ヘッダー行を繰り返し入力することは避けてください。ヘッダー行はデータと混ざってしまい、後々問題を引き起こす可能性があります。代わりに、列ヘッダーを固定することで、多くの行があるスプレッドシートでも常に表示されるようにすることができます。
ゼロ値の入力を省略する場合
測定対象の数値が通常ゼロである場合――例えば調査でウサギの目撃回数を記録する場合など――その列にわざわざ「0」と入力する必要はあるでしょうか?
ただし、スプレッドシートにおけるゼロ値と空欄セルには重要な違いがあります。コンピュータにとってゼロは実際に測定・カウントされたデータ値です。一方、空欄セルは「未測定」であることを意味し、コンピュータはこれを「不明値」(null値または欠損値)として解釈します。
スプレッドシートや統計解析ソフトは、ゼロ値として意図した空欄セルを誤って解釈する可能性があります。観測値の値を入力しないことは、そのデータを「不明」または「欠損」(null)として扱うようコンピュータに指示することになります。これは後続の計算や分析に問題を引き起こす可能性があります。例えば、数値データセットに1つのnull値が含まれている場合、その平均値は常にnull値となります(コンピュータは欠損値の正確な値を推測できないため)。このため、ゼロ値は確実に「0」として記録し、真の欠損データのみをnull値として扱うことが極めて重要です。
問題のあるnull値の使用
具体例: -999などの数値やゼロ値を用いて欠損データを表現する場合。
解決策:
データセット内でnull値が異なった形で表現される背景には、いくつかの理由があります。測定機器から自動的に記録される際に混乱を招くnull値が生成される場合もあります。この場合、対処の余地はあまりありませんが、OpenRefineなどのデータクリーニングツールを使用して分析前に処理することが可能です。また、データが存在しない理由が異なることを示すために、異なるnull値が使用されることもあります。これは重要な情報ではありますが、実質的に1つの列で2種類の情報を表現していることになります。フォーマットによる情報伝達の場合と同様に、「data_missing」などの新しい列を作成し、この列を用いて異なる理由を記録するのが適切です。
いずれの場合も、不明値や欠損データが-999、999、あるいは0として記録されている場合は問題が生じます。
多くの統計解析ソフトは、これらの値が欠損値(null値)として意図されたものであることを認識できません。これらの値がどのように解釈されるかは、使用する分析ソフトウェアによって異なります。明確で一貫性のあるnull値の指標を使用することが不可欠です。
空白セル(ほとんどのアプリケーションで使用)やNA値(R言語の場合)は良い選択肢です。@White:2013の論文では、各種ソフトウェアアプリケーションにおけるnull値の適切な表示方法について詳しく解説しています:
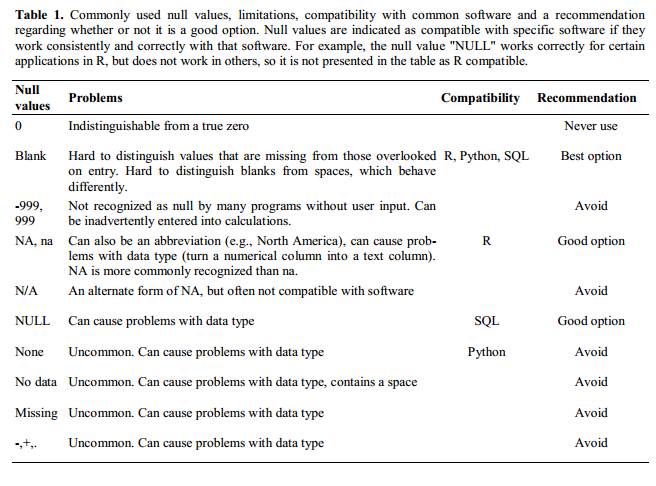
フォーマットによる情報伝達
具体例: 分析から除外すべきセル、行、または列を強調表示する場合や、データの区切りを示すために空白行を使用する場合。
解決策: 除外すべきデータを符号化する新しいフィールドを作成する。
データシートの見栄えを良くするためのフォーマット使用
具体例: セルの結合。
解決策: 注意しないと、ワークシートをより見栄え良くするためのフォーマット処理が、コンピュータがデータの関連性を認識する能力を損なう可能性があります。結合されたセルは統計解析ソフトウェアにとってデータが読み取り不能な状態になります。データを整理するためにセルを結合する必要がないようにデータ構造を再構成することを検討してください。
セルへのコメントや単位の記載
ほとんどの解析ソフトウェアはExcelやLibreOfficeのコメントを認識できず、データセル内に配置されたコメントに混乱する可能性があります。前述のフォーマットの場合と同様に、セルに注釈を追加する必要がある場合は別のフィールドを作成してください。同様に、単位をセル内に記載することも避けてください。理想的には、1つの列に配置するすべての測定値は同じ単位であるべきです。何らかの理由で単位が異なる場合は、別のフィールドを作成し、セルの単位を明確に指定してください。
セルに複数の情報を混在させる場合
具体例: ABO血液型とRh因子を一つのセルに記録する場合(例:A+、B+、A-など)
解決策: 一つのセルに複数の情報を混在させないようにしてください。これにより、データ分析の方法が制限されてしまいます。これらの測定値の両方が必要な場合は、これらの情報を記録するための専用のデータシートを設計してください。例えば、ABOグループ用とRh因子用の2つの列を設けるといった方法が考えられます。
問題のあるフィールド名の使用
説明的なフィールド名を使用することは重要ですが、スペース、数字、特殊文字を含めないように注意してください。スペースは区切り文字としてスペースを使用するパーサーによって誤解釈される可能性があり、一部のプログラムでは数字で始まるテキスト文字列のフィールド名を受け付けない場合があります。
アンダースコア(_)はスペースの代わりとして有効です。読みやすさを向上させるため、キャメルケース表記(例:ExampleFileName)を使用することも検討してください。ただし、現時点で意味が通じる略語も、6ヶ月後には理解しづらくなる可能性があることに留意してください。一方で、名前が過度に長くなりすぎないようにすることも大切です。フィールド名に単位を含めることで、混乱を防ぎ、他者がデータの意味を容易に理解できるようになります。
具体例
| 適切な名前 | 代替案 | 避けるべき例 |
|---|---|---|
| Max_temp_C | MaxTemp | Maximum Temp (°C) |
| Precipitation_mm | Precipitation | precmm |
| Mean_year_growth | MeanYearGrowth | Mean growth/year |
| sex | sex | M/F |
| weight | weight | w. |
| cell_type | CellType | Cell Type |
| Observation_01 | first_observation | 1st Obs |
データファイルにおける特殊文字の使用
具体例: スプレッドシートプログラムをワープロソフトのように扱う場合 例えば、Word文書などからデータを直接コピーしてメモを作成する際などに見られます。
解決策: これは一般的な手法です。例えば、セル内に長文を入力する場合、改行記号やエンダッシュなどの特殊文字を含めることがよくあります。また、Wordなどのアプリケーションからデータをコピーすると、書式設定や非標準の装飾文字(左右揃えの引用符など)も一緒にコピーされます。このようなデータをコーディング環境や統計処理システム、あるいはリレーショナルデータベースにエクスポートすると、行が途中で切断されたり、エンコーディングエラーが発生したりするなどの問題が生じる可能性があります。
一般的なベストプラクティスとして、改行記号、タブ、垂直タブなどの特殊文字を追加することは避けるべきです。言い換えれば、テキストセルはテキストとスペースのみを含むシンプルなWebフォームと同様に扱うべきです。
データテーブルへのメタデータの包含
具体例: データテーブルの上部または下部に、各列の意味や単位、例外事項などを説明した凡例を追加する場合
解決策: データに関するメタデータ(「メタデータ」)の記録は不可欠です。データ収集・分析作業中はデータセットと密接に関わっているため、その時点であれば「sglmemgp」という変数が「グループの単独メンバー」を意味することや、変数を変換したり派生変数を作成した際に使用した正確なアルゴリズムなどを覚えているかもしれません。しかし、数ヶ月後や数年後にこれらを正確に覚えている可能性は極めて低いでしょう。
さらに、他の人々があなたのデータを調査・利用したいと考える理由は多岐にわたります - あなたの研究成果を理解するため、あなたの発見を検証するため、提出した論文を見直すため、あなたの結果を再現するため、類似研究を設計するため、あるいは単に他者がアクセス・再利用できるようにデータをアーカイブするためです。デジタルデータは定義上機械可読ですが、データの意味を理解するのは人間の役割です。研究の収集・分析段階でデータを文書化することの重要性は、特にその研究が学術記録の一部となる場合にはいくら強調してもしすぎることはありません。
ただし、メタデータはデータファイル自体に含めるべきではありません。紙媒体の表や補足ファイルとは異なり、メタデータ(凡例の形式など)はデータファイル内に含めるべきではありません。なぜなら、この情報はデータそのものではなく、データファイルの解釈方法を乱す可能性があるからです。代わりに、メタデータはデータファイルと同じディレクトリに別ファイルとして保存し、できればプレーンテキスト形式で、データファイルと明確に関連付けられる名前を付けるべきです。メタデータファイルは自由テキスト形式であるため、データファイルのフォーマットを乱すことなく、コメントや単位、null値の符号化方法など、文書化が必要な重要な情報も記録できます。
さらに、ファイルレベルまたはデータベースレベルのメタデータは、データセットを構成するファイル間の関係性、それらのファイル形式、および以前のファイルに取って代わるものか補完するものかといった情報を示します。プロジェクト内のすべてのファイルとフォルダを記録する古典的な方法として、フォルダレベルのreadme.txtファイルが用いられます。
(メタデータに関する記述は、EDINAとエディンバラ大学データライブラリが提供するオンラインコース『Research Data』MANTRAの内容を改変したものです。MANTRAのライセンスはCreative Commons 表示 4.0 国際ライセンスに準拠しています。)
データのエクスポート方法
質問
- スプレッドシートからエクスポートしたデータを、後続の分析アプリケーションで効果的に活用するにはどうすればよいでしょうか?
目的
- スプレッドシートデータを汎用的なファイル形式で保存する
- スプレッドシートからCSVファイルへデータをエクスポートする
重要なポイント
一般的なスプレッドシート形式で保存されたデータは、データ分析ソフトウェアで正しく読み込まれないことが多く、データにエラーが生じる原因となります。
CSVやTSVといった形式にデータをエクスポートすれば、ほとんどのアプリケーションで一貫して利用できる形式になります。
分析に使用するデータをExcelの標準ファイル形式(*.xlsまたは*.xlsx
-
使用するExcelのバージョンによって異なります)で保存するのは推奨されません。その理由は?
この形式は独自のファイル形式であり、将来的に技術が廃れたり、ファイルを開くことが不便、あるいは不可能になる可能性があるためです。
他のスプレッドシートソフトウェアでは、Excel独自の形式で保存されたファイルを開けない場合があります。
Excelの異なるバージョン間でデータの扱い方が異なるため、不整合が生じる可能性があります。日付データの取り扱いは、データ保存における不整合の典型的な例としてよく知られています。
さらに、多くの学術誌や研究助成機関がデータリポジトリへのデータ登録を義務付けており、これらの機関のほとんどはExcel形式を受け付けていません。以下に挙げる別の形式を使用する必要があります。
上記のポイントは、LibreOffice/OpenOfficeで使用されるオープンデータ形式などの他の形式にも当てはまります。これらの形式は静的なものではなく、異なるソフトウェアパッケージ間で同じように解析されるわけではありません。
汎用的でオープン、かつ静的な形式でデータを保存すれば、この問題を効果的に解決できます。タブ区切り形式(タブ区切り値またはTSV)またはカンマ区切り形式(カンマ区切り値またはCSV)の使用を検討してください。CSVファイルはテキストファイルの一種で、列がカンマで区切られているため「カンマ区切り値」と呼ばれます。Excel/SPSSなどのファイル形式に比べてCSVファイルの利点は、ほぼすべてのソフトウェア、例えばTextEditやNotePadといったテキストエディタでも開いて読み込める点です。CSVファイルのデータは、SQLiteやRなどの他の形式や環境にも簡単にインポートできます。CSVファイルを使用する場合、特定の高価なソフトウェアの特定バージョンに縛られることがないため、最大限の移植性と永続性が求められる場合に最適な形式と言えます。ほとんどのスプレッドシートソフトウェアでは、CSV形式などの区切りテキスト形式へのエクスポートが簡単に行えますが、ファイルエクスポート時には警告が表示される場合があります。
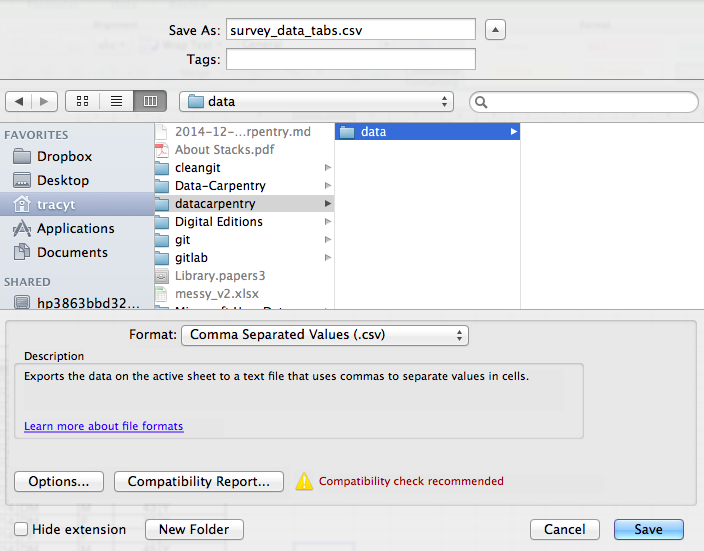
Excelで開いているファイルをCSV形式で保存するには:
- 上部メニューから「ファイル」→「名前を付けて保存」を選択します。
- 「ファイル形式」フィールドのリストから「カンマ区切り値」(
*.csv)を選択します。 - ファイル名と保存先を再確認し、「保存」をクリックします。
後方互換性に関する重要な注意点:CSVファイルはExcelでも開くことができます!
Rとxlsファイルに関する補足:xlsファイル(およびGoogleスプレッドシート)を読み込めるRパッケージが存在します。xlsドキュメント内の異なるワークシートにアクセスすることも可能です。
ただし:
- これらのパッケージの中にはWindows環境でしか動作しないものがあります。
- これは、単純な手動エクスポート処理の代わりに、データ分析用Rコードに追加の複雑さと依存関係が生じることを意味します。
- データフォーマットのベストプラクティスは依然として適用されます。
- 本当に
csv形式(または類似の形式)が不適切だと言えるほどの正当な理由があるのでしょうか?
カンマ使用時の注意点
一部のデータセットでは、データ値自体にカンマ(,)が含まれている場合があります。この場合、Excelを含む多くのソフトウェアは、データを列形式で正しく表示できません。これは、データ値の一部として含まれるカンマが、実際には区切り文字として解釈されてしまうためです。
例えば以下のようなデータ形式を考えてみましょう:
species_id,genus,species,taxa
AB,Amphispiza,bilineata,Bird
AH,Ammospermophilus,harrisi,Rodent, not censused
AS,Ammodramus,savannarum,Bird
BA,Baiomys,taylori,Rodentレコード
AH,Ammospermophilus,harrisi,Rodent, not censused
において、taxa
の値にはカンマが含まれています(Rodent, not censused)。このようなデータをExcelなどの表計算ソフトで読み込もうとすると、以下のような表示結果になります:
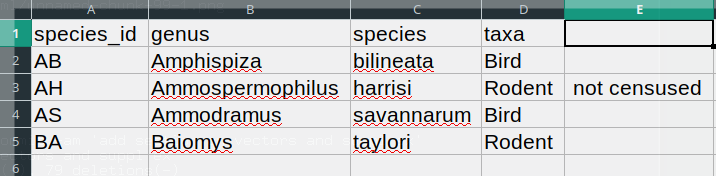
taxa
の値は1つの列(D列)に収まるべきところ、2つの列に分割されてしまいました。これによりさらなるエラーが発生する可能性があります。例えば、余分な列は欠損値が多い列(適切なヘッダー情報なし)として解釈されてしまいます。さらに、行3のレコード(taxa
値にカンマが含まれていた行)の列Dの値も不正確になってしまいます。
csv形式でデータを保存する場合で、データ値にカンマが含まれる可能性がある場合は、上記の問題を回避するために値をダブルクォート(““)で囲むことが有効です。このルールを適用すると、データは以下のようになります:
species_id,genus,species,taxa
"AB","Amphispiza","bilineata","Bird"
"AH","Ammospermophilus","harrisi","Rodent, not censused"
"AS","Ammodramus","savannarum","Bird"
"BA","Baiomys","taylori","Rodent"この形式でExcelに読み込めば、ダブルクォートの外側にあるカンマのみが区切り文字として認識されるため、余分な列は生成されません。
あるいは、カンマを含むデータを扱う場合、表計算ソフトで作業する際には別の区切り文字を使用する必要があります1。この場合、タブ文字を区切り文字として設定し、TSVファイル形式で作業することを検討してください。TSVファイルはCSVファイルと同様に表計算ソフトからエクスポート可能です。
既に存在するデータセットで、データ値がダブルクォートで囲まれていないにもかかわらずカンマが区切り文字とデータ値の両方に使われている場合、データクリーニングにおいて重大な問題に直面する可能性があります。特に数百件から数千件のレコードを含むデータセットの場合、手動でカンマを削除したり値をダブルクォートで囲んだりする作業には膨大な時間がかかり、誤って多くのエラーを混入させてしまうリスクもあります。
データクリーニングは多くの科学分野における主要な課題の一つです。そのアプローチは通常、特定の状況に応じて異なります。ただし、スクリプトを記述して実行するなど、自動化された方法でデータをクリーニングすることは良い実践方法です。PythonやRの学習を通じて、関連するスクリプト開発スキルを身につける基礎が身につきます。
まとめ

上記の図は、データを繰り返し変換・可視化・モデリングする典型的なデータ分析ワークフローを示しています。この反復プロセスは、データが十分に理解されるまで複数回繰り返されます。しかし実際のケースでは、データ分析そのものよりもデータのクリーニングと準備に多くの時間が費やされる場合がほとんどです。
変換/可視化/モデリングのサイクルを迅速に繰り返すアジャイルなデータ分析ワークフローを実現するには、データが予測可能な形式でフォーマットされており、データを実際に確認したり修正したりすることなくその内容を理解できることが重要です。
- 適切なデータ整理は、あらゆる研究プロジェクトの基盤です。
これは特にヨーロッパ諸国で顕著な問題です。これらの地域ではカンマが小数点区切りとして使用されるため、csvファイルではデフォルトでセミコロン(;)が値の区切り文字として使われます。あるいは、値が自動的にダブルクォートで囲まれることになります。↩︎